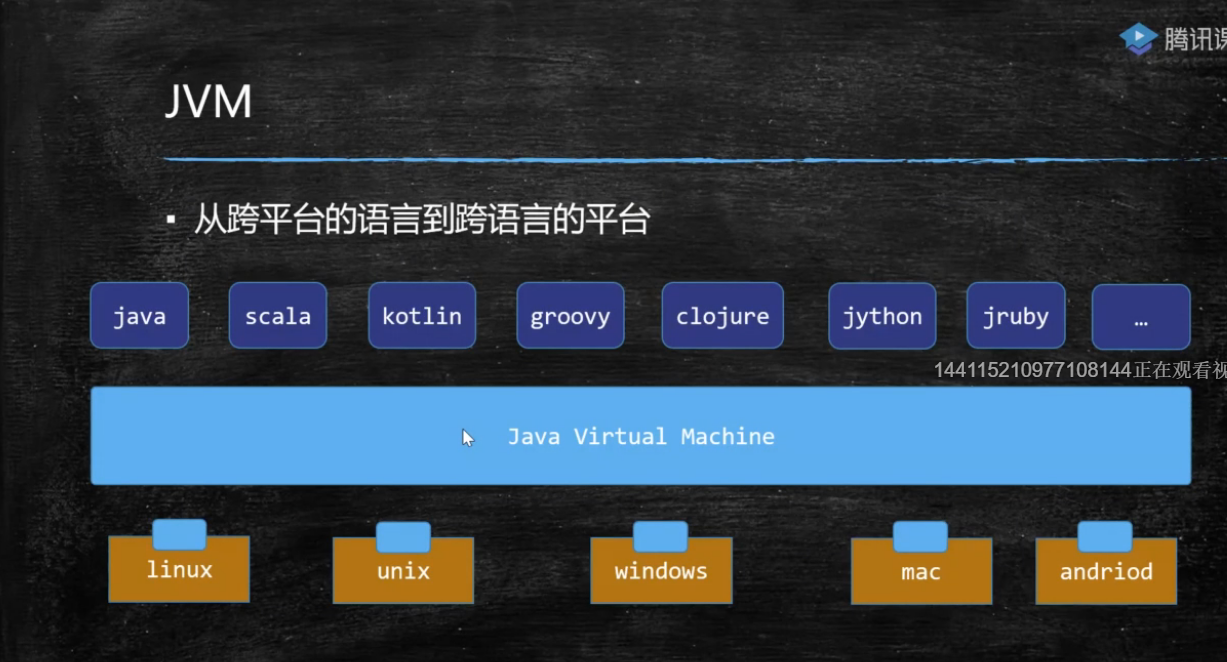
1:JVM基础知识 什么是JVM 1. java虚拟机,跨语言的平台,实现java跨平台 2. 可以实现多种语言跨平台,只要该语言可以编译成.class文件 3. 解释执行.class文件 java是跨平台的语言,JVM是跨语言的平台
JVM运行流程
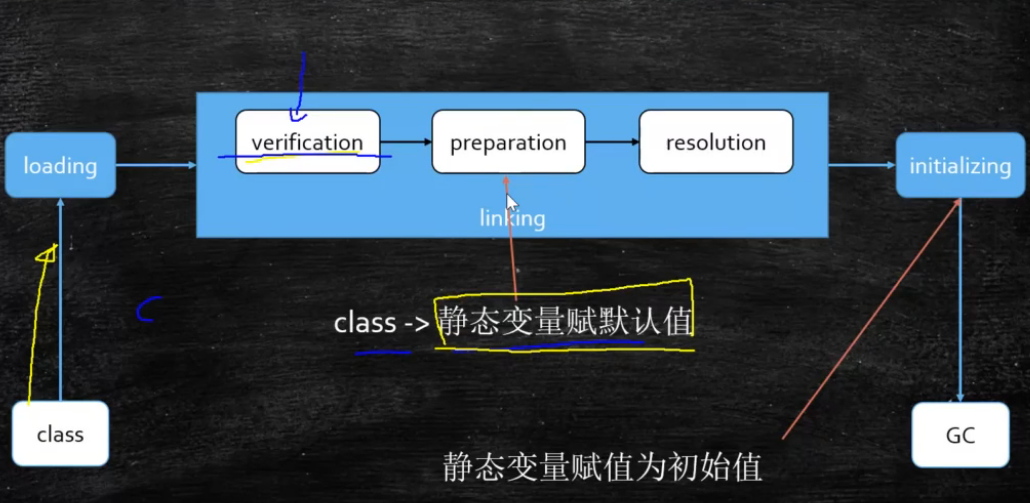
1. preparation 默认值=>初始值=>
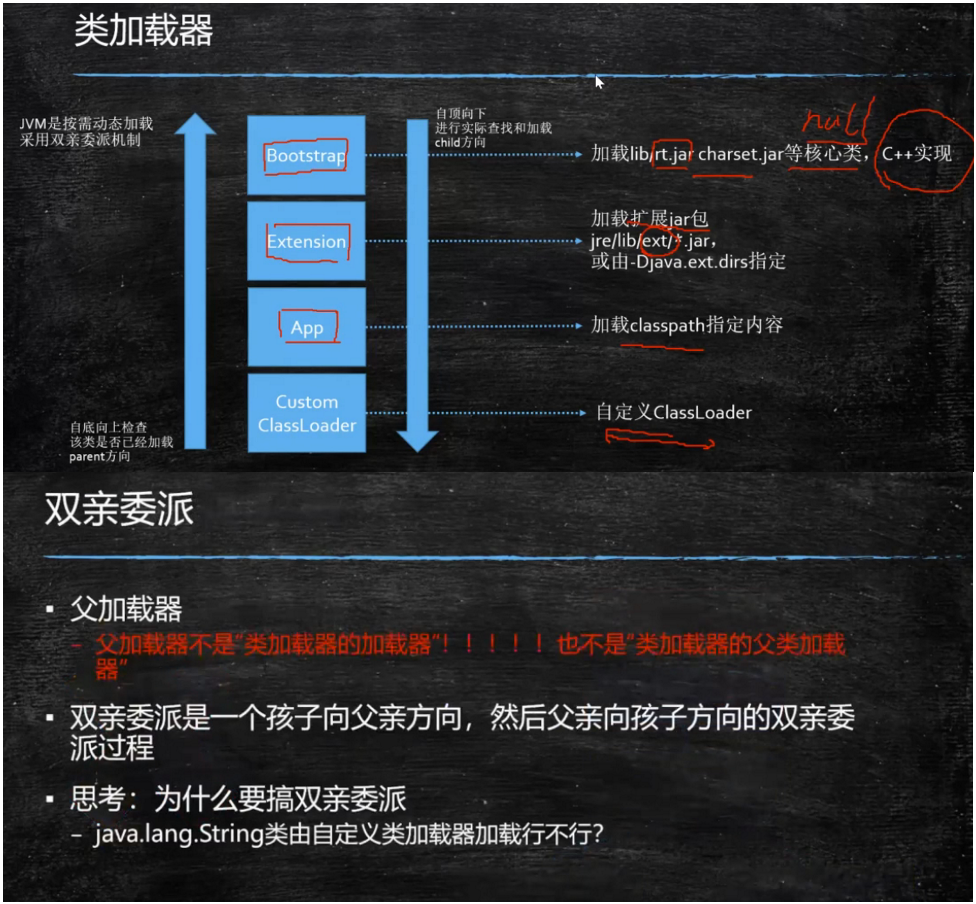
2. 类加载器(jvm是按需动态加载,采用双亲委派机制,自底向上检查该类是否已经加载)
3. 为什么要使用双亲委派,为了安全
4. 自定义ClassLoader(customer Class Loader)=>classpath指定内容(App)=>加载扩展包(jre.lib.ext *.jar)=>加载rt.jar等核心包(BootStrap)
常见的JVM
1. Hotspot oracle
2. Jrocket BEA被oracle收购
3. J9 IBM
4. VM Microsoft
5. TaobaoVM 阿里
6. LiQuidVM 直接针对硬件 oracle
7. zing azul最新垃圾回收的业界标杆
2:ClassFileFormat
数据类型:u1 u2 u4 u8和_info(表类型)
1. _info的来源是hotspot源码中的写法
查看16进制格式的ClassFile
1. sublime/notepad/
2. IDEA插件-BinEd
有很多可以观察ByteCode的方法
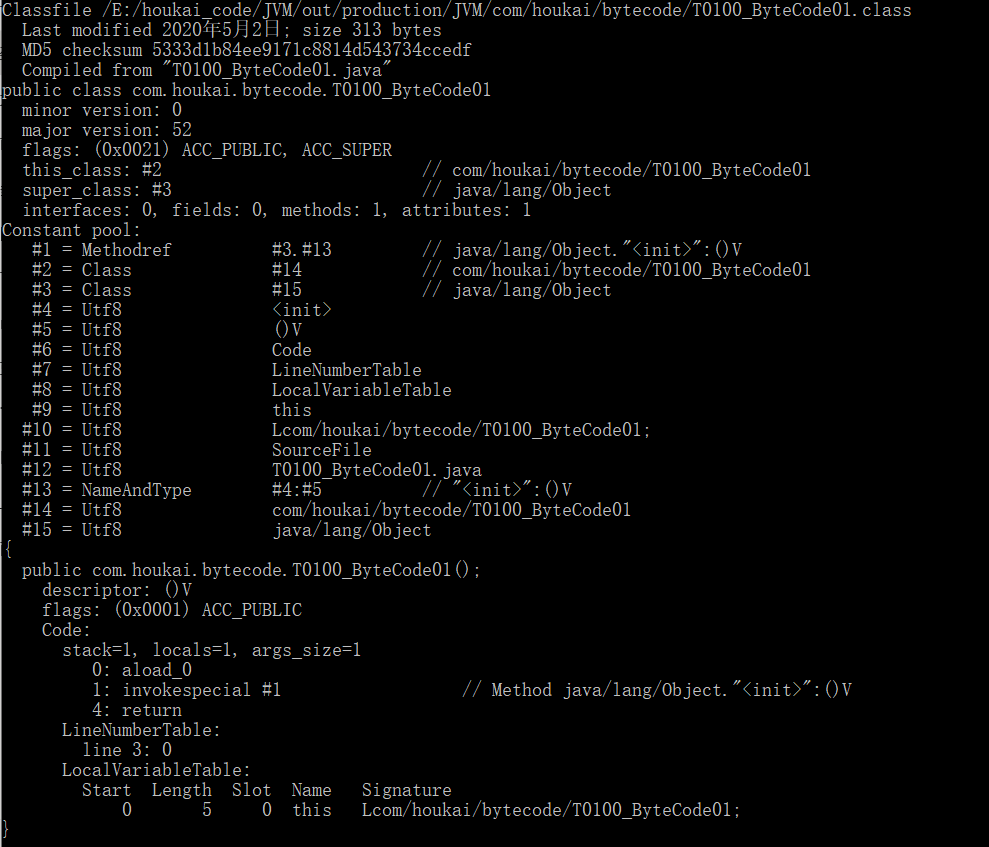
1. javap
javap -v E:JVMoutproductionJVMcomytecodeT0100_ByteCode01.class
2. JBE-可以直接修改
3. JClassLib-IDEA插件
4. classfile组成
ClassFIle{
u4 magic;
u2 miner_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count - 1];
u2
}
5. 二进制文件详解

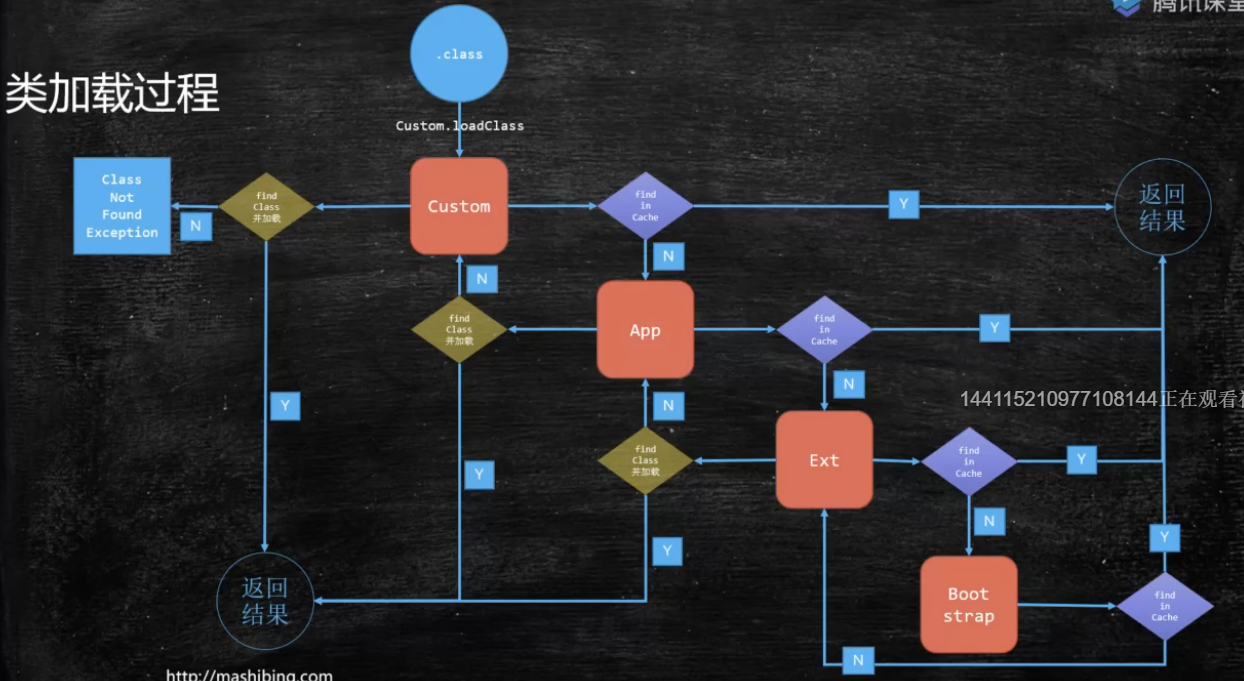
类加载 加载过程 1.Loading 双亲委派:从自定义类加载器到classpath下的App到ext再到bootstrap一层一层去找,检查该类是否已经加载,有就返回, 返回也是从父类向子类一层一层查找 CustomerClassLoader<=>App<=>Extension<=>Bootstrap 2.Linking Verification 验证文件是否符合JVM规定(前两位ca fe ba be) Preparation 静态变量赋默认值,不是初始值 Resolution 将类、方法、属性等符号引用解析为直接引用 常量池中的各种符号引用解析为指针、偏移量等内存地址的直接引用 3.Initializing 调用类初始化代码 <clinit>,给静态成员变量赋初始值
双亲委派机制:CustomerClassLoader<=>App<=>Extension<=>Bootstrap
代码验证

为什么使用双亲委派:为了安全,防止篡改jdk原有的类加载器
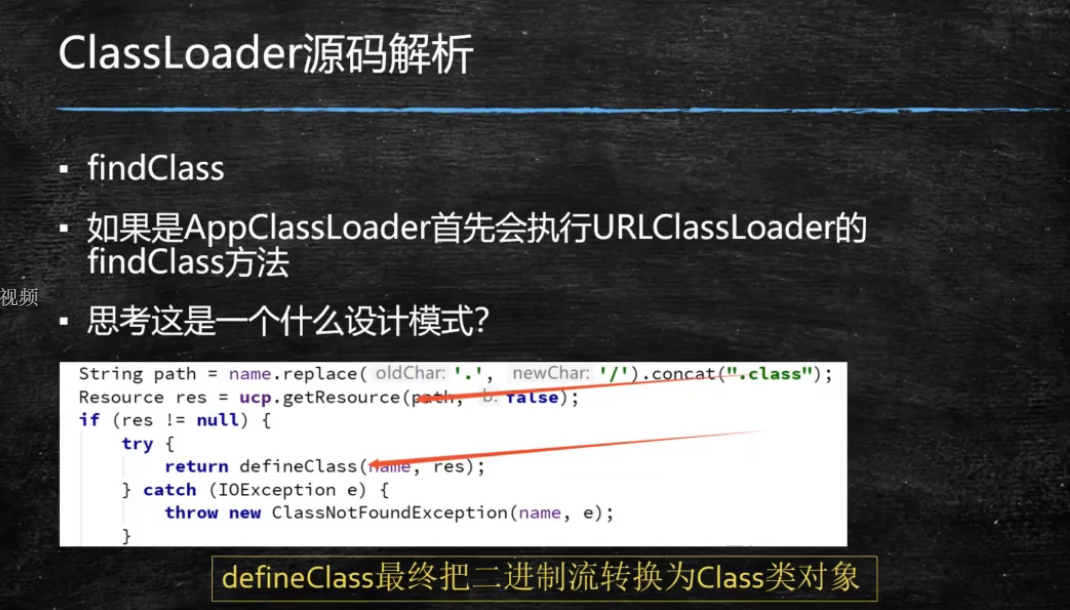
classLoader源码解析
findInCache -> parent.loadClass -> findClass()
parent是如何指定的,打破双亲委派
用super(parent)指定 双亲委派的打破 如何打破:重写loadClass() 何时打破过? i. JDK1.2之前,自定义ClassLoader都必须重写loadClass() ii. ThreadContextClassLoader可以实现基础类调用实现类代码,通过thread.setContextClassLoader指定 iii. 热启动,热部署 1) osgi tomcat 都有自己的模块指定classloader(可以加载同一类库的不同版本) 自定义类加载器 extends ClassLoader overwrite findClass() -> defineClass(byte[] -> Class clazz) 加密 public class T007_MSBClassLoaderWithEncription extends ClassLoader { public static int seed = 0B10110110; @Override protected Class<?> findClass(String name) throws ClassNotFoundException { File f = new File("c:/test/", name.replace('.', '/').concat(".testclass")); try { FileInputStream fis = new FileInputStream(f); ByteArrayOutputStream baos = new ByteArrayOutputStream(); int b = 0; while ((b=fis.read()) !=0) { baos.write(b ^ seed); } byte[] bytes = baos.toByteArray(); baos.close(); fis.close();//可以写的更加严谨 return defineClass(name, bytes, 0, bytes.length); } catch (Exception e) { e.printStackTrace(); } return super.findClass(name); //throws ClassNotFoundException } public static void main(String[] args) throws Exception { encFile("com.koukay.jvm.hello"); ClassLoader l = new T007_MSBClassLoaderWithEncription(); Class clazz = l.loadClass("com.koukay.jvm.Hello"); Hello h = (Hello)clazz.newInstance(); h.m(); System.out.println(l.getClass().getClassLoader()); System.out.println(l.getParent()); } private static void encFile(String name) throws Exception { File f = new File("c:/test/", name.replace('.', '/').concat(".class")); FileInputStream fis = new FileInputStream(f); FileOutputStream fos = new FileOutputStream(new File("c:/test/", name.replaceAll(".", "/").concat(".testclass"))); int b = 0; while((b = fis.read()) != -1) { fos.write(b ^ seed); } fis.close(); fos.close(); } } 代码执行方式 -Xmixed 混合执行 默认模式 -Xint 解释执行 -Xcomp 编译执行

JMM
硬件数据一致性
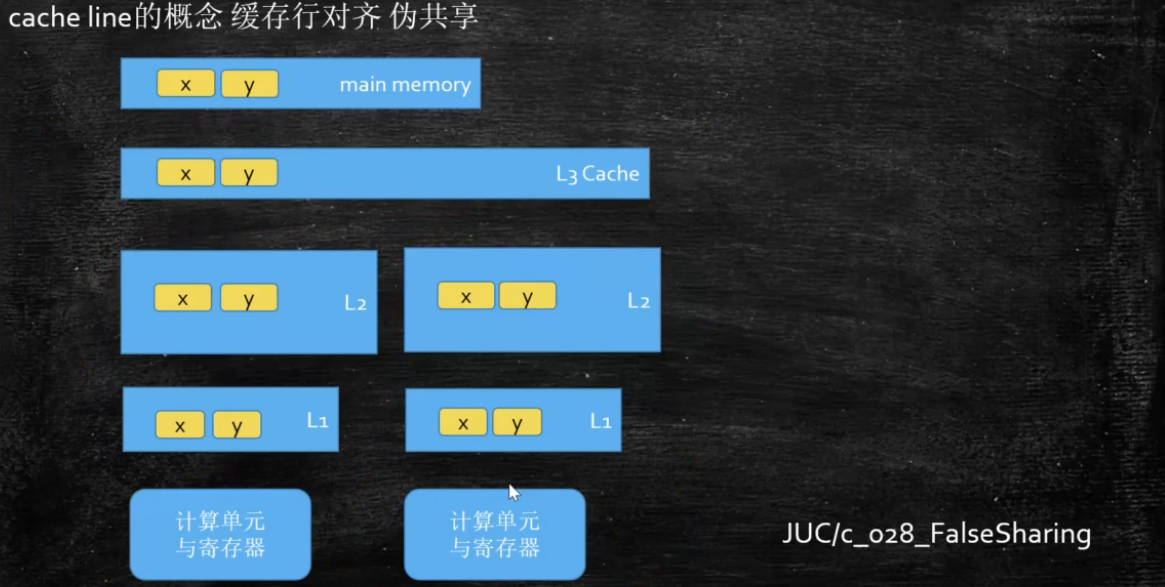
硬件层面:离CPU越近,效率越高,但是容量越小
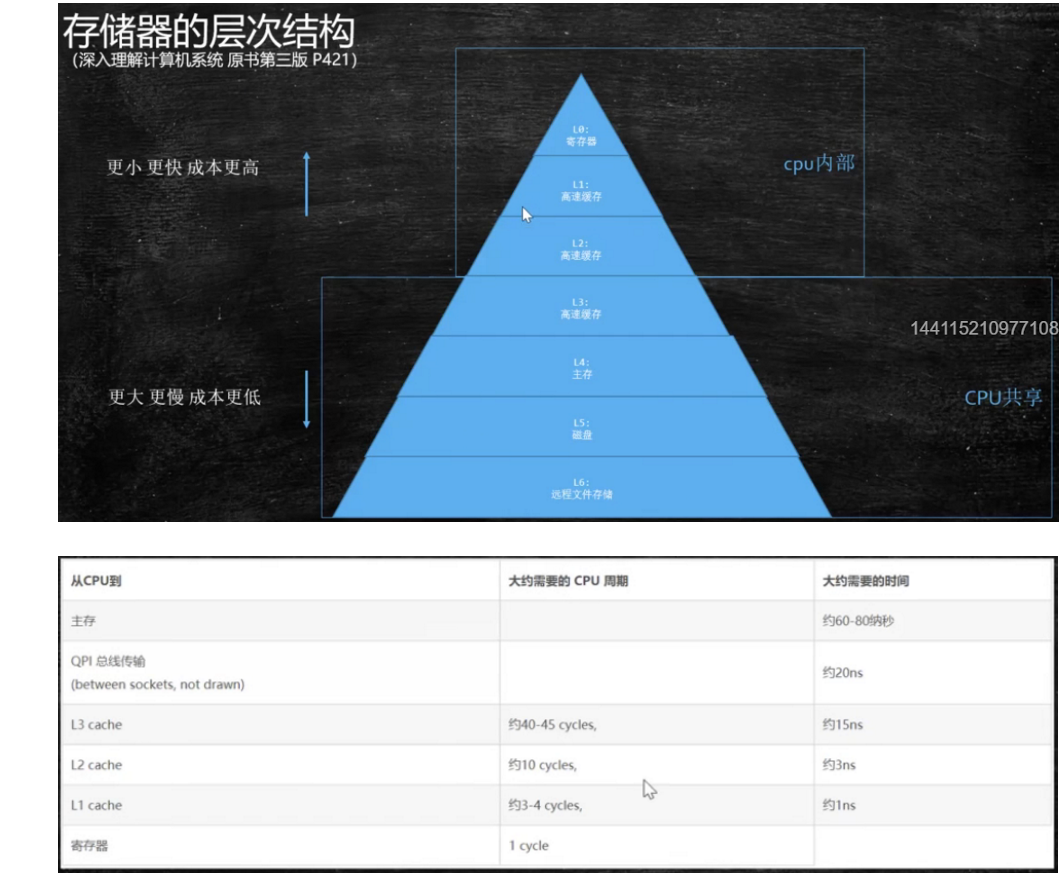
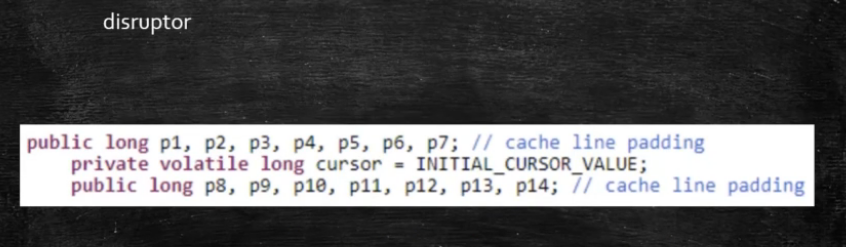
主内存同一缓存行的两个数可能同时被加载到L1和L2中,导致整个缓存行数据发生改变,解决方案-加总线锁,但是效率低
位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题
读取缓存以cache line为基本单位,目前64bytes
解决方案-加总线锁,但是效率低

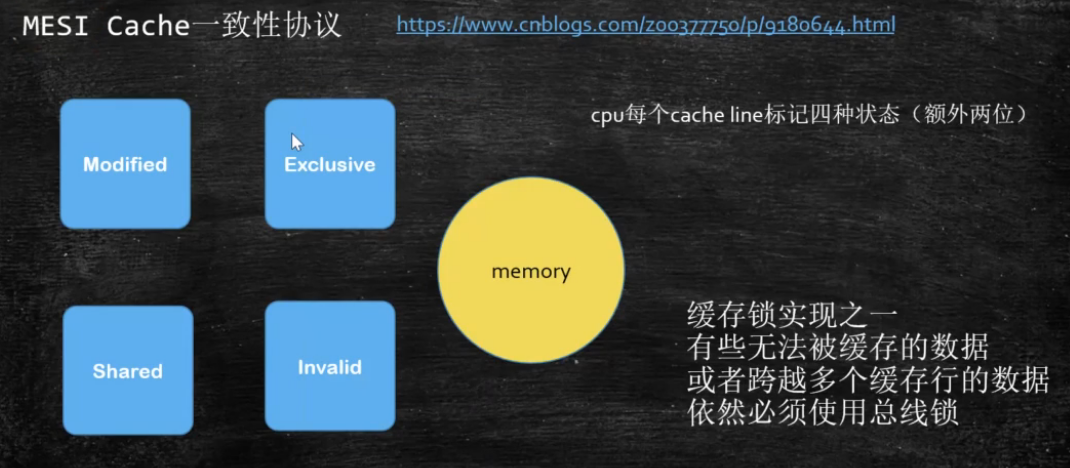
效率高一点的解决方案,使用MESI缓存一致性协议(现代CPU的数据一致性实现 = 缓存锁(MESI ...) + 总线锁) https://www.cnblogs.com/z00377750/p/9180644.html
MESI协议中的状态
https://www.cnblogs.com/z00377750/p/9180644.html CPU中每个缓存行(caceh line)使用4种状态进行标记(使用额外的两位(bit)表示): M: 被修改(Modified) 该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。 当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。 E: 独享的(Exclusive) 该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。 同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。 S: 共享的(Shared) 该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。 I: 无效的(Invalid) 该缓存是无效的(可能有其它CPU修改了该缓存行)。 对齐缓存行,可以提高效率
CPU为提升效率,会乱序执行
乱序问题
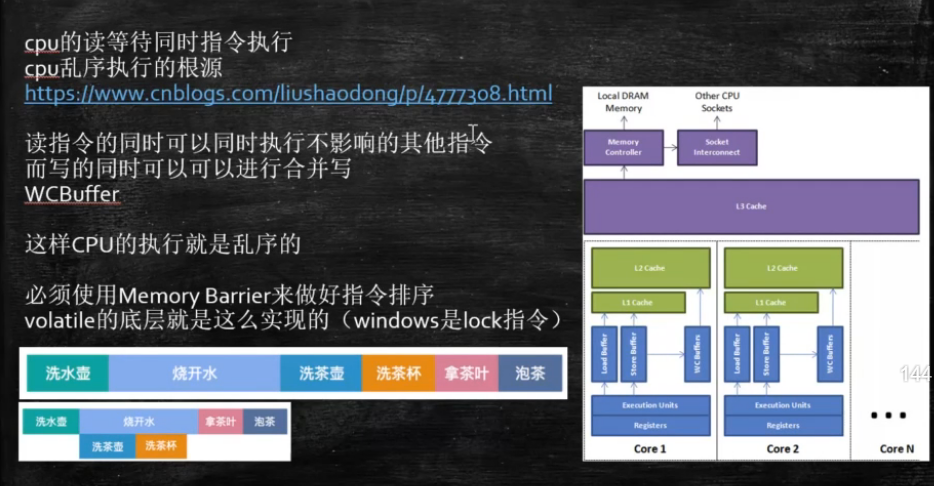
cpu为了提高指令执行效率,会在一条指令执行的过程中(比如去内存读取数据)去同时执行另一条指令, 前提是两条指令没有依赖关系 如果一个cpu在执行的时候需要访问的内存都不在cache中,cpu必须要通过内存总线到主存中取,那么在数据返回到cpu这段时间内(这段时间大致为cpu执行成百上千条指令的时间,至少两个数据量级)干什么呢? 答案是cpu会继续执行其他的符合条件的指令。比如cpu有一个指令序列 指令1 指令2 指令3 …, 在指令1时需要访问主存,在数据返回前cpu会继续后续的和指令1在逻辑关系上没有依赖的”独立指令”,cpu一般是依赖指令间的内存引用关系来判断的指令间的”独立关系”,具体细节可参见各cpu的文档。这也是导致cpu乱序执行指令的根源之一。 写操作合并 当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1_cache未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区。这一技术称为合并写入技术。在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区,该缓冲区大小和一个cache line大小,一般都是64字节。这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响 当后续的写操作需要修改相同的缓存行时,这些缓冲区变得非常有趣。在将后续的写操作提交到L2缓存之前,可以进行缓冲区写合并。 这些64字节的缓冲区维护了一个64位的字段,每更新一个字节就会设置对应的位,来表示将缓冲区交换到外部缓存时哪些数据是有效的。当然,如果程序读取已被写入到该缓冲区的某些数据,那么在读取缓存数据之前会先去读取本缓冲区的。 经过上述步骤后,缓冲区的数据还是会在某个延时的时刻更新到外部的缓存(L2_cache).如果我们能在缓冲区传输到缓存之前将其尽可能填满,这样的效果就会提高各级传输总线的效率,以提高程序性能。 https://www.cnblogs.com/liushaodong/p/4777308.html 如何保证特点情况下不乱序 硬件内存屏障 X86(CPU内存屏障) sfence:store| 在sfence指令前的写操作必须在sfence指令后的写操作前完成 Ifence:load| 在Ifence指令前的读操作必须在Ifence指令后的读操作前完成 mfence:modify/mix | 在mfence指令前的读写操作必须在mfence指令后的读写操作前完成 Intel lock汇编指令 原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序 java内存模型中volatile变量在写操作之后会插入一个store屏障,在读操作之前会插入load屏障,一个类的final字段会在初始化之后插入一个store屏障,来确保final字段在构造函数初始化完成并可被使用时可见 JVM级别如何规范(JSR内存屏障) LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2, 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。 StoreStore屏障:对于这样的语句Store1; StoreStore; Store2, 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。 LoadStore屏障:对于这样的语句Load1; LoadStore; Store2, 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。 StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2, 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。 volatile的实现细节 字节码层面 ACC_VOLATILE JVM层面 volatile内存区的读写都加屏障 StoreStoreBarrier volatile 写操作 StoreLoadBarrier LoadLoadBarrier volatile 读操作 LoadStoreBarrier OS和硬件层面 hsdis - HotSpot Dis Assembler windows lock 指令实现 | MESI实现 https://blog.csdn.net/qq_26222859/article/details/52235930 synchronized实现细节 字节码层面 ACC_SYNCHRONIZED monitorenter monitorexit JVM层面 C C++ 调用了操作系统提供的同步机制 OS和硬件层面 X86 : lock cmpxchg / xxx https://blog.csdn.net/21aspnet/article/details/88571740
java并发内存模型
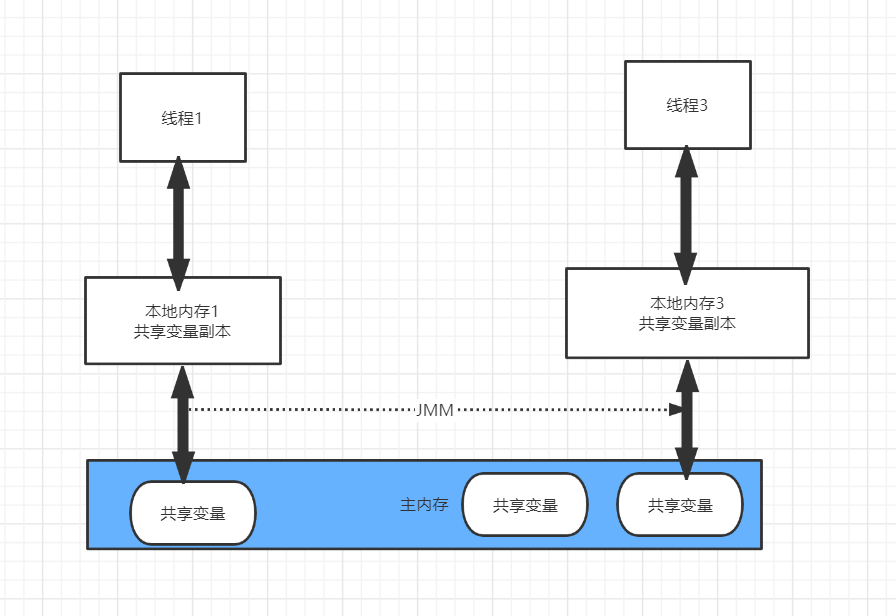
java线程之间通讯由java内存模型(JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见,从抽象的角度来看,
JMM定义了线程和主内存之间的关系,线程之间的共享变量存储在主内存中,每个线程都有个私有的本地内存,本地内存存储了共享变量副本,本地内存是JMM的抽象概念,并不真实存在
请解释一下对象的创建过程
将class load到内存
校验class规范,静态变量初始化默认值,解析指针引用
静态变量赋初始化值
为对象分配内存
成员变量赋默认值
调用构造方法
检分零头初(对象创建的几个步骤:检查加载 分配空间 设置零值 设置对象头 对象初始化)

观察虚拟机配置
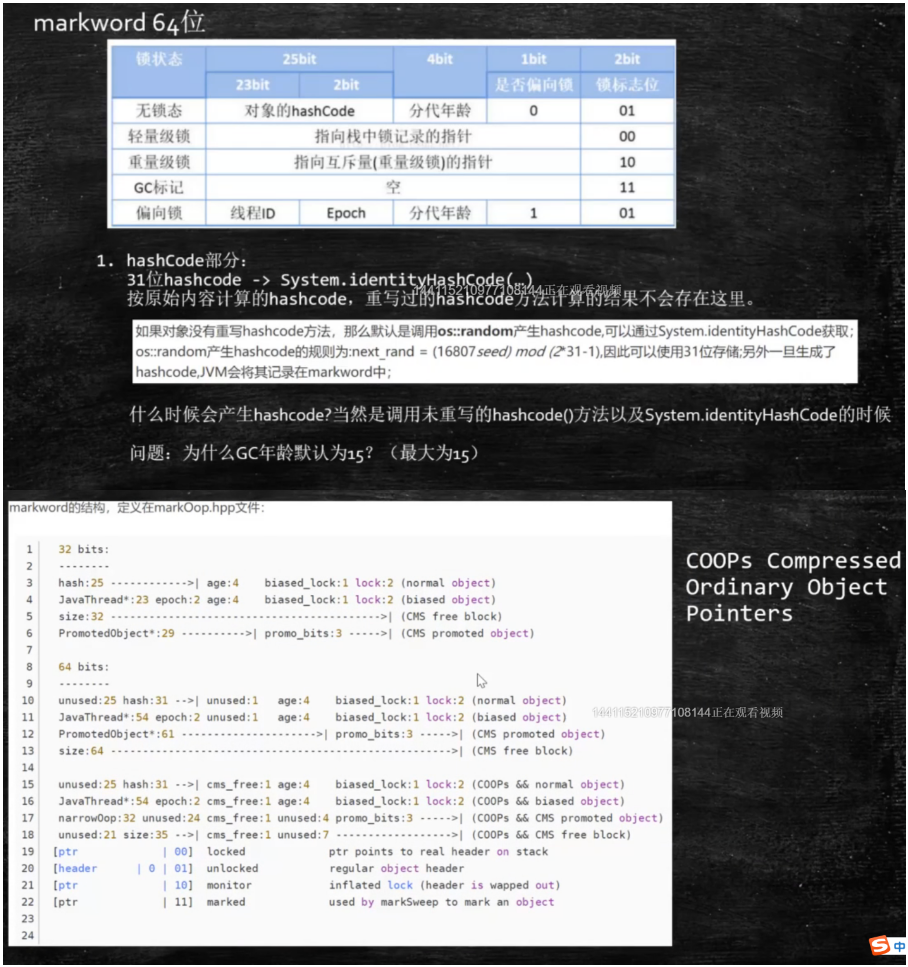
java -XX:+PrintCommandLineFlags -version -XX:InitialHeapSize=333908032 -XX:MaxHeapSize=5342528512 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC java version "1.8.0_231" Java(TM) SE Runtime Environment (build 1.8.0_231-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode) 对象在内存中存储布局 普通对象 对象头:markword 8 对象状态,被回收多少次 ClassPointer指针:-XX:+UseCompressedClassPointers 为4字节 不开启为8字节 指向哪个class 实例数据 引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节 变量 Oops Ordinary Object Pointers Padding对齐,8的倍数 数组对象 对象头:markword 8 ClassPointer指针 数组长度:4字节 数组数据 Padding对齐 8的倍数 对象头包括什么 对象头2位表示锁,gc标记分代年龄 gc年龄为什么为最大为15,因为他只有4位
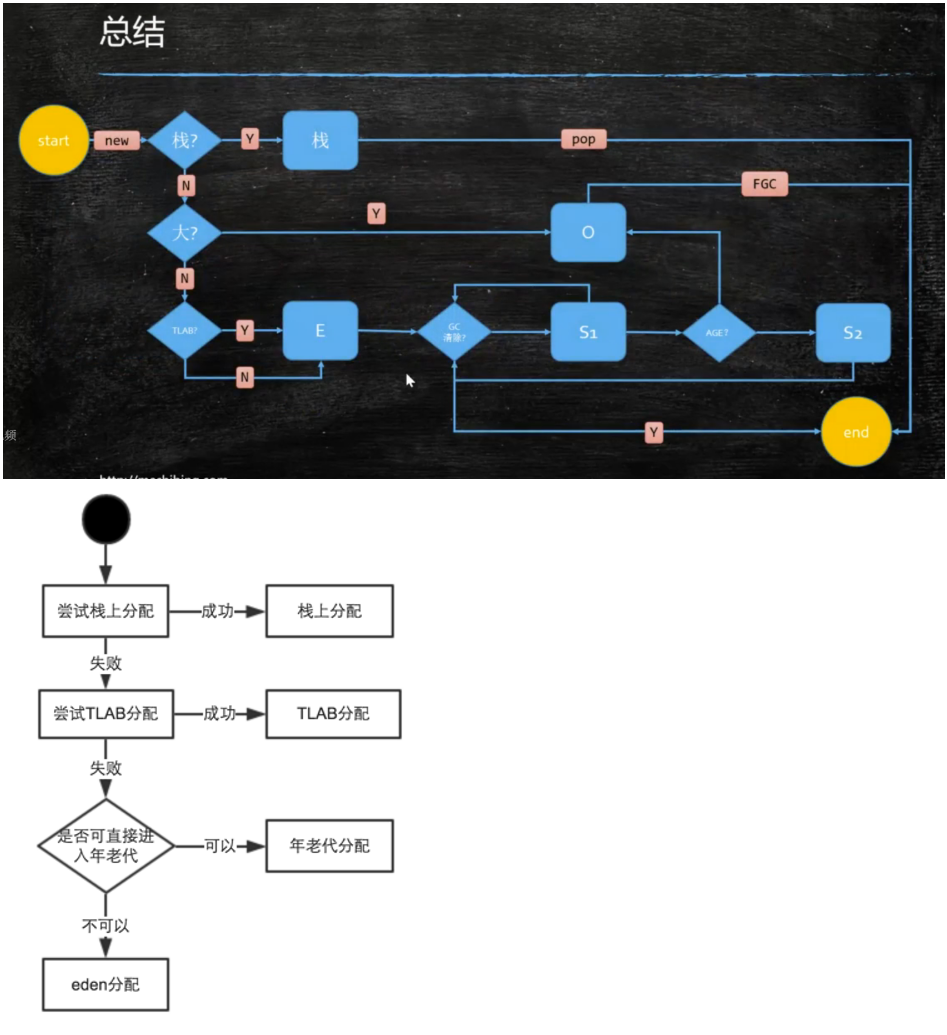
new object()占用多少字节 16 对象头8,引用指针4,4个padding,不压缩还是16个字节 public class T03_SizeOfAnObject { /** * 压缩后 * 16 * 16 * 32 * 不压缩 * 16 * 24 * 40 * @param args */ public static void main(String[] args) { //Padding对齐,8的倍数 //对象头8,指针引用(分压缩和不压缩,压缩是4,不压缩是8),如果是8不加padding,如果是4得加4padding,不压缩:16,压缩后16 System.out.println(ObjectSizeAgent.sizeOf(new Object())); //对象头8,指针引用(分压缩和不压缩,压缩是4,不压缩是8),再加上4个数组长度,如果压缩就不加padding,如果不压缩需要加4padding,不压缩:24,压缩后16 System.out.println(ObjectSizeAgent.sizeOf(new int[] {})); //对象头8,指针引用(分压缩和不压缩,压缩是4,不压缩是8),id是4,name是4,age是4,b1是1,b2是1,o是4,b3是1,不压缩:40,压缩后32 System.out.println(ObjectSizeAgent.sizeOf(new P())); } //一个Object占多少个字节 // -XX:+UseCompressedClassPointers -XX:+UseCompressedOops // -XX:-UseCompressedClassPointers表示不压缩 // Oops = ordinary object pointers private static class P { //8 _markword //4 _class pointer int id; //4 String name; //4 int age; //4 byte b1; //1 byte b2; //1 Object o; //4 byte b3; //1 } } 对象定位 句柄池 (指针池)间接指针,节省内存 直接指针 访问速度快 就HotSpot而言,他使用的是直接指针访问方式进行对象访问,但从整个软件开发的范围来看,各种语言和框架使用句柄来访问的情况也十分常见。 https://blog.csdn.net/clover_lily/article/details/80095580 对象分配过程 先栈后堆,先伊甸后old 1.编译器通过逃逸分析判断对象是在栈上分配还是堆上分配,如果是堆上分配则进入下一步。(开启逃逸分析需要设置jvm参数) 2.如果tlab可以放下该对象则在tlab上分配,否则进入下一步。 3.重新申请一个tlab,再尝试存放该对象,如果放不下则进入下一步。 4.在eden区加锁,尝试在eden区存放,若存放不下则进入下一步。 5.执行一次Young GC。 6.Young GC后若eden区仍放不下该对象,则直接在老年代分配。
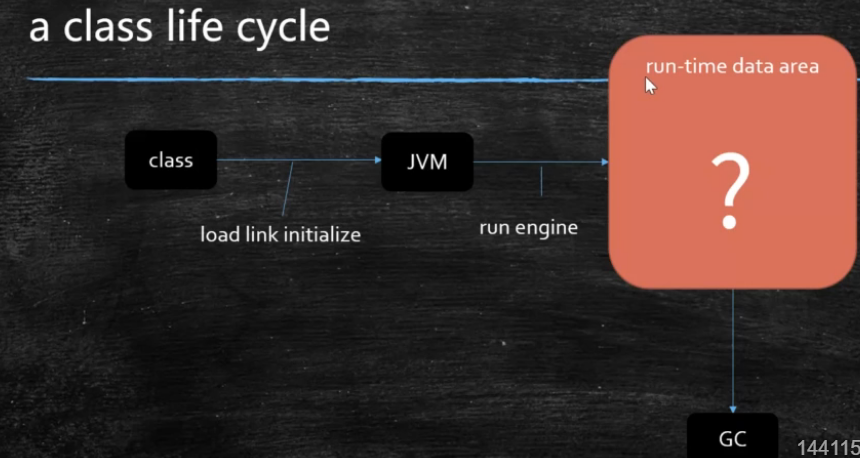
JVM Runtime Data Area and JVM Instruction Set a class life cycle class (load link initialize)--> JVM (run engin) -->run-time data area -->GC
Runtime Data Area 运行时数据区
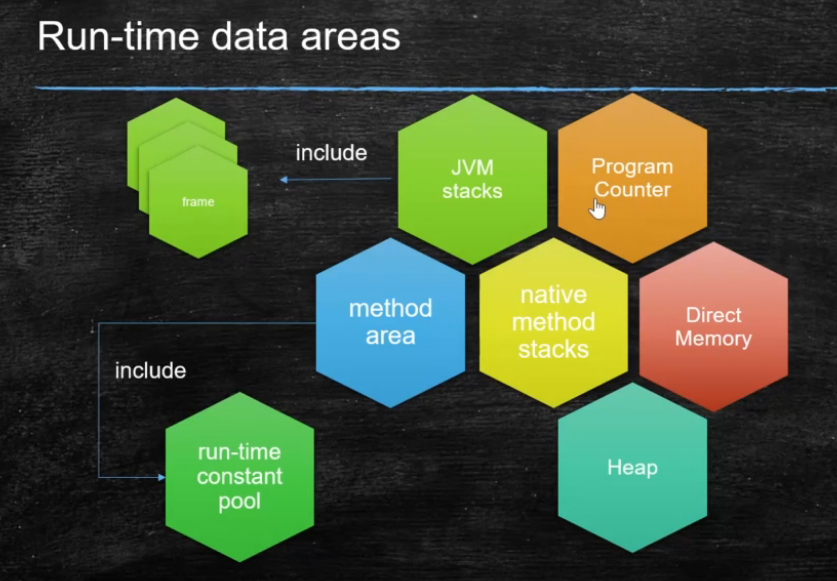
Program Counter:(程序计数器)存放指令位置
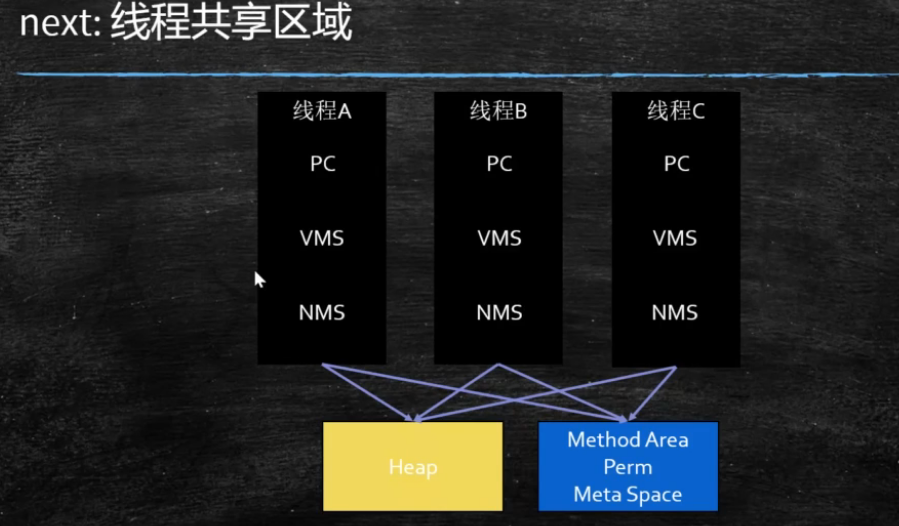
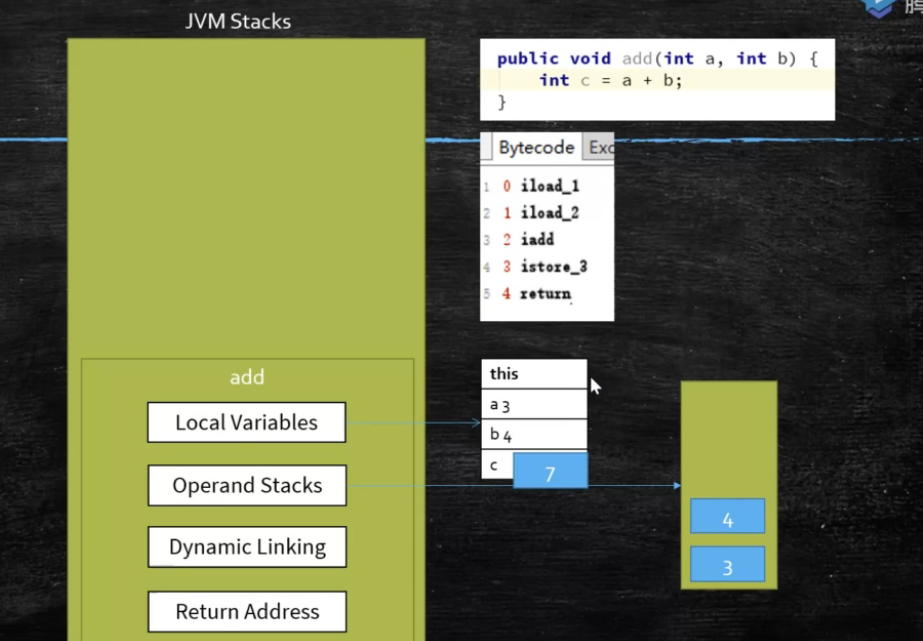
虚拟机的运行类似这样的循环 while(not end){ 取pc中的位置,知道对应位置的指令; 执行该指令; pc++; } JVM Stack 虚拟机栈 每个JVM线程有个JVM栈,和线程同时创建 JVM栈存储的栈帧Frame Frame - 每个方法对应一个栈帧,用于存储数据和部分结果,以及执行动态链接,方法返回值和抛出异常 Local Variable Table 本地变量表 Operand Stack 对于long的处理(store and load),多数虚拟机的实现都是原子的 jls 17.7,没必要加volatile Dynamic Linking 动态链接是一个将符号引用解析为直接引用的过程 https://blog.csdn.net/qq_41813060/article/details/88379473 jvms 2.6.3 return address a() -> b(),方法a调用了方法b, b方法的返回值放在什么地方 Heap 堆 Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象。线程间共享 在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。 Method Area 方法区 保存在着被加载过的每一个类的信息; 这些信息由类加载器在加载类的时候,从类的源文件中抽取出来; static变量信息也保存在方法区中; Perm Space (<1.8) 字符串常量位于PermSpace FGC不会清理 大小启动的时候指定,不能变 Meta Space (>=1.8) 字符串常量位于堆 会触发FGC清理 不设定的话,最大就是物理内存 Runtime Constant Pool 常量池 Native Method Stack 本地方法栈 Direct Memory 直接内存 JVM可以直接访问的内核空间的内存 (OS 管理的内存) NIO , 提高效率,实现zero copy
指令集分类
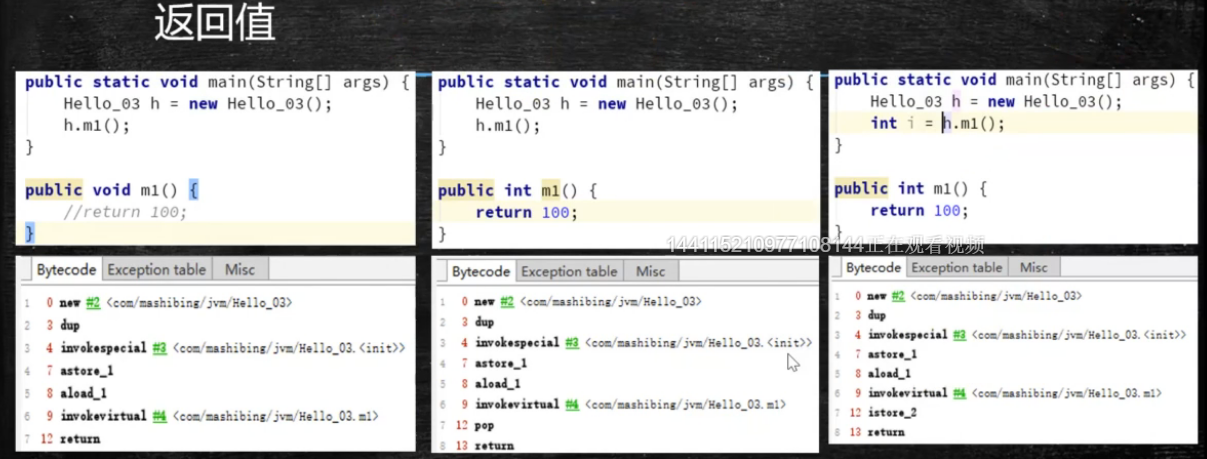
基于寄存器的指令集 基于栈的指令集 Hotspot中的Local Variable Table = JVM中的寄存器 常用指令: store: istore_<n> Store int into local variable 出栈 load: iload_<n> Load int from local variable 压栈 pop: pop Pop the top operand stack value 弹栈 mul: imul Multiply int 乘法 sub: isub Subtract int 减法 invoke: InvokeStatic: invokestatic Invoke a class (static) method 引用静态方法 InvokeVirtual: invokevirtual Invoke instance method; dispatch based on class 调用实例方法 基于类的分派 InvokeInterface: invokeinterface Invoke interface method 调用接口方法 InovkeSpecial: invokespecial Invoke instance method; direct invocation of instance initialization methods and methods of the current class and its supertypes 调用实例方法,直接调用当前类及其父类的初始化方法 可以直接定位,不需要多态的方法 private 方法 , 构造方法 InvokeDynamic: invokedynamic Invoke a dynamically-computed call site 调用动态计算方法 JVM最难的指令 lambda表达式或者反射或者其他动态语言scala kotlin,或者CGLib ASM,动态产生的class,会用到的指令 案例解析 public class TestIPulsPlus { public static void main(String[] args) { int i = 8; i = ++i; System.out.println(i); } }
public class TestIPulsPlus {
public static void main(String[] args) { int i = 8; i = i++; System.out.println(i); } }


Garbage Collector and GC tuning 什么是垃圾 没有任何引用指向的一个对象或多个对象(循环引用)都是垃圾 如何定位垃圾 引用计数(ReferenceCount) 不能解决RC a->b->c->a 但是没有引用指向他们,所以他们是一团垃圾 跟可达算法(Root Searching) main开始的栈帧 静态变量.常量池 jni指针 GC Algorithm 常见垃圾回收算法 Mark-Sweep 标记清除 - 位置不连续 产生碎片 效率偏低(两遍扫描)

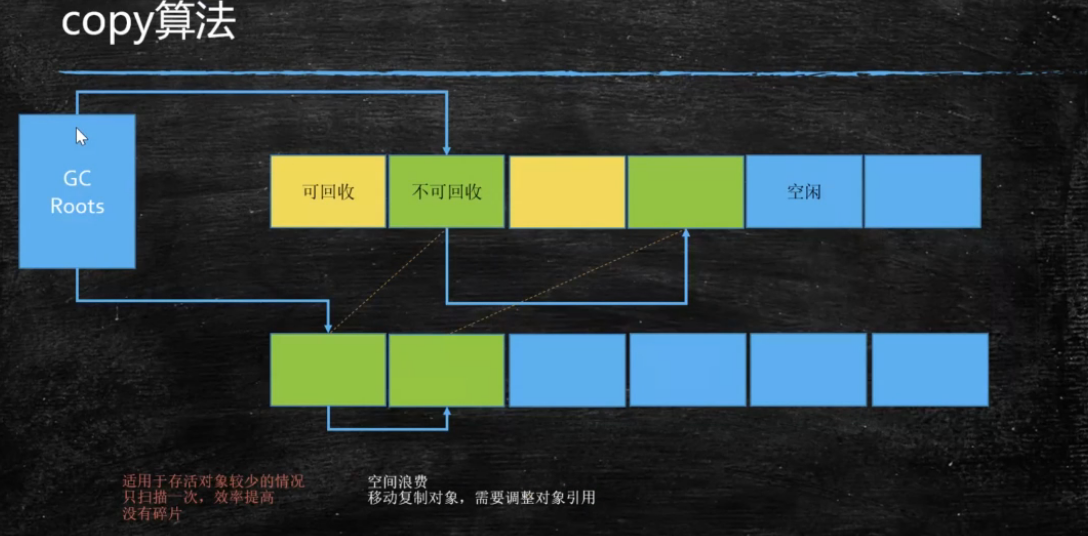
拷贝算法 (copying) - 没有碎片,浪费空间
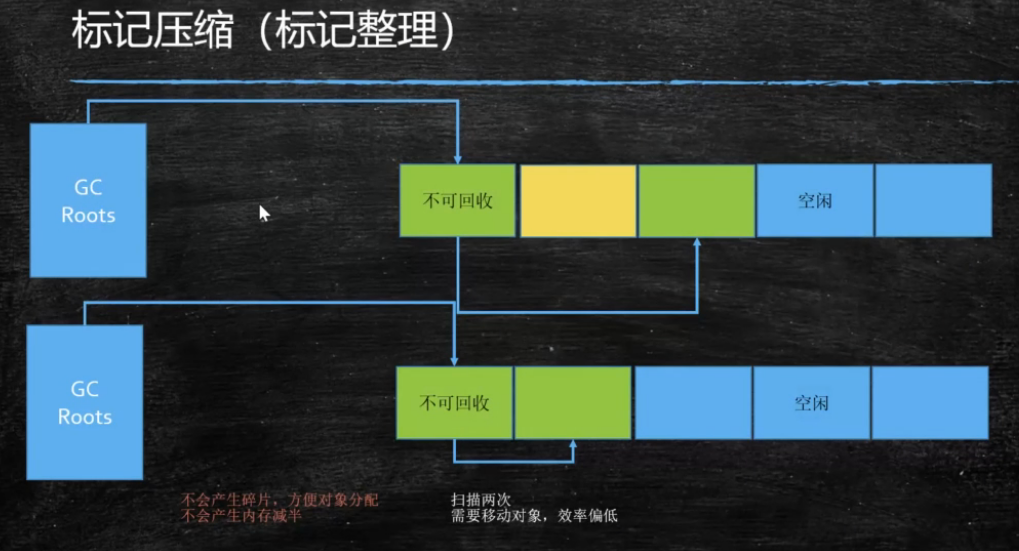
标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)
JVM内存分代模型(用于垃圾回收算法)
部分垃圾回收器使用的模型 除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型 G1是逻辑分代,物理不分代 除此之外不仅逻辑分代,而且物理分代 新生代 + 老年代 + 永久代(1.7)Perm Generation/ 元数据区(1.8) Metaspace 永久代 元数据 - Class 永久代必须指定大小限制 ,元数据可以设置,也可以不设置,无上限(受限于物理内存) 字符串常量 1.7 - 永久代,1.8 - 堆 MethodArea逻辑概念 - 永久代、元数据 新生代 = Eden + 2个suvivor区 YGC回收之后,大多数的对象会被回收,活着的进入s0 再次YGC,活着的对象eden + s0 -> s1 再次YGC,eden + s1 -> s0 年龄足够 -> 老年代 (15 CMS 6) s区装不下 -> 老年代 老年代 顽固分子 老年代满了FGC Full GC GC Tuning (Generation) 尽量减少FGC MinorGC = YGC MajorGC = FGC new:old 1:2 eden:s1:s2 8:1:1

对象分配过程图
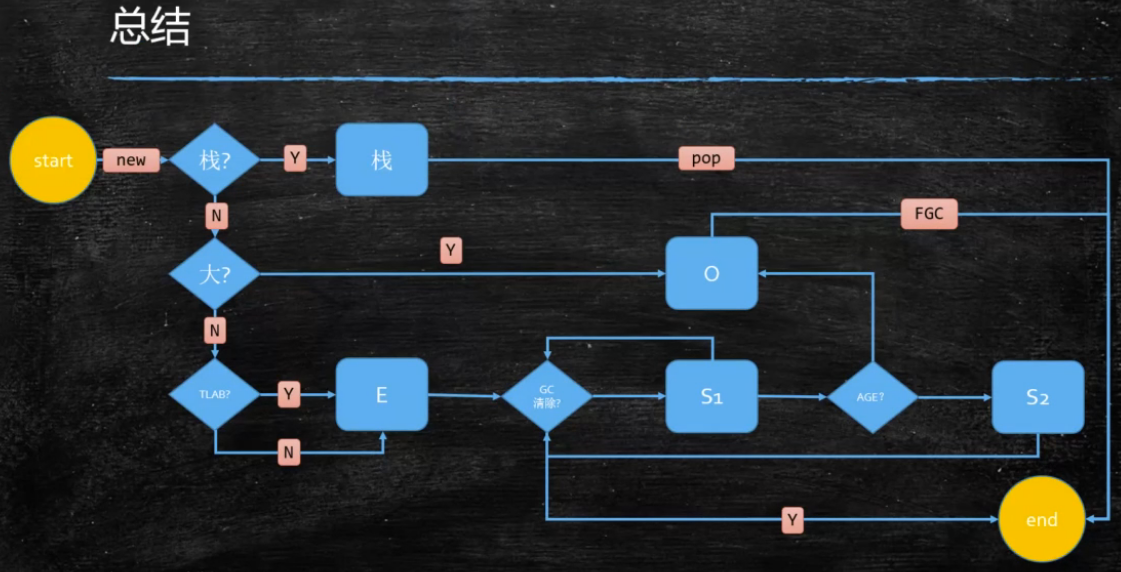
栈上分配
private的小对象 只在方法内使用,没有对象指向 简单类型表示对象 无需调整 TLAB分配 Tlab Thread Local Allocation Buffer 占用eden 小对象 无需调整 测试栈上分配及线程本地分配效率: -XX:-DoEscapeAnalysis-XX:-EliminateAllocations-XX:-UseTLAB 逃逸分析 标量替换 线程专有对象分配 对象什么时候进入老年代 指定YoungGC次数 XX:MaxTenuringThreshod Eden+s1->s2动态年龄超过 s2的50% 把年龄最大的放入Old 常见的垃圾回收器
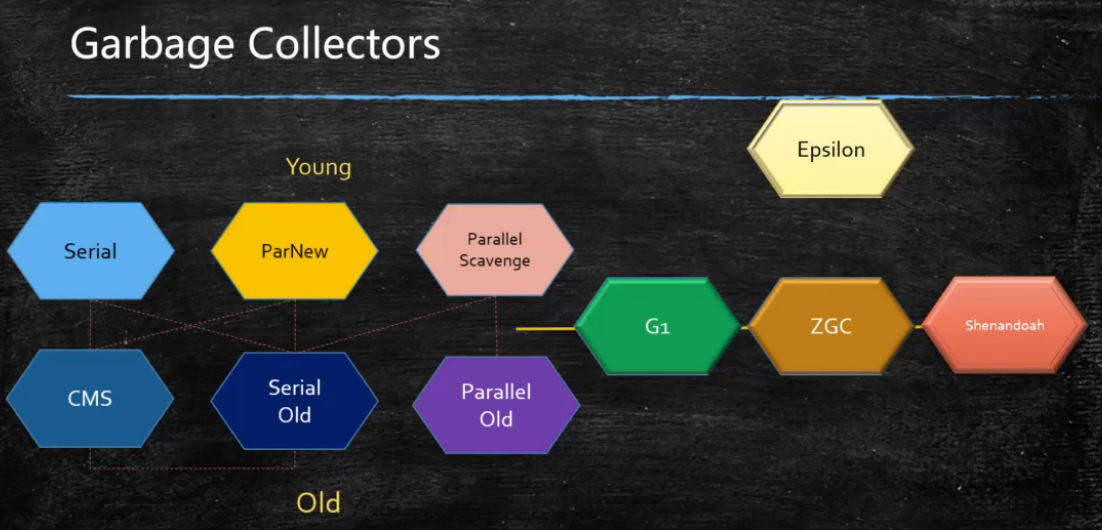
JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前没有任何一个JDK版本默认是CMS 并发垃圾回收是因为无法忍受STW Serial 年轻代 STW 单线程的,串行回收 内存小 safe point 在安全点暂停 PS 年轻代 并行回收 STW 多线程 ParNew 年轻代 STW 配合CMS的并行回收 SerialOld 老年代 STW 单线程的,串行回收 ParallelOld 老年代 STW 多线程 ConcurrentMarkSweep CMS老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms) CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定 CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收 想象一下: PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW) 几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC 算法:三色标记 + Incremental Update CMS的问题 i. Memory Fragmentation 内存碎片 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction 默认为0 指的是经过多少次FGC才进行压缩 ii. Floating Garbage 浮动垃圾 Concurrent Mode Failure 产生:if the concurrent collector is unable to finish reclaiming the unreachable objects before the tenured generation fills up, or if an allocation cannot be satisfiedwith the available free space blocks in the tenured generation, then theapplication is paused and the collection is completed with all the applicationthreads stopped 解决方案:降低触发CMS的阈值 PromotionFailed 解决方案类似,保持老年代有足够的空间 –XX:CMSInitiatingOccupancyFraction 92% 可以降低这个值,让CMS保持老年代足够的空间 优化环境 有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G 的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G 的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了 为什么原网站慢? 很多用户浏览数据,很多数据load到内存,内存不足,频繁GC,STW长,响应时间变慢 为什么会更卡顿? 内存越大,FGC时间越长 咋办? PS -> PN + CMS 或者 G1 系统CPU经常100%,如何调优?(面试高频) CPU100%那么一定有线程在占用系统资源, 找出哪个进程cpu高(top) 该进程中的哪个线程cpu高(top -Hp) 导出该线程的堆栈 (jstack) 查找哪个方法(栈帧)消耗时间 (jstack) 工作线程占比高 | 垃圾回收线程占比高 系统内存飙高,如何查找问题?(面试高频) 导出堆内存 (jmap) 分析 (jhat jvisualvm mat jprofiler ... ) 如何监控JVM jstat jvisualvm jprofiler arthas top... G1(10ms) 算法:三色标记 + SATB ZGC (1ms) PK C++ 算法:ColoredPointers + LoadBarrier Shenandoah 算法:ColoredPointers + WriteBarrier Eplison PS 和 PN区别的延伸阅读: ▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73 垃圾收集器跟内存大小的关系 Serial 几十兆 PS 上百兆 - 几个G CMS - 20G G1 - 上百G ZGC - 4T - 16T(JDK13) 1.8默认的垃圾回收:PS + ParallelOld 常见垃圾回收器组合参数设定:(1.8) -XX:+UseSerialGC = Serial New (DefNew) + Serial Old 小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器 -XX:+UseParNewGC = ParNew + SerialOld 这个组合已经很少用(在某些版本中已经废弃) https://stackoverflow.com/questions/34962257/why-remove-support-for-parnewserialold-anddefnewcms-in-the-future -XX:+UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old -XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】 -XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old -XX:+UseG1GC = G1 Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC java +XX:+PrintCommandLineFlags -version 通过GC的日志来分辨 Linux下1.8版本默认的垃圾回收器到底是什么? 1.8.0_181 默认(看不出来)Copy MarkCompact 1.8.0_222 默认 PS + PO