下载地址
ElasticSearch:https://www.elastic.co/cn/downloads/elasticsearch
Logstash:https://www.elastic.co/cn/downloads/logstash
Kibana:https://www.elastic.co/cn/downloads/kibana
安装Kibana的过程中遇到这样的问题

网上搜了好多帖子,如下

但是问题都没有解决
最终安装了head插件
1.下载head
https://github.com/mobz/elasticsearch-head
2.下载安装node
http://nodejs.cn/download/
3.编译head
进入E:javaELKelasticsearch-head目录 执行npm install 命令npm install -g cnpm --registry=https://registry.npm.taobao.org
再执行 cnpm i 命令
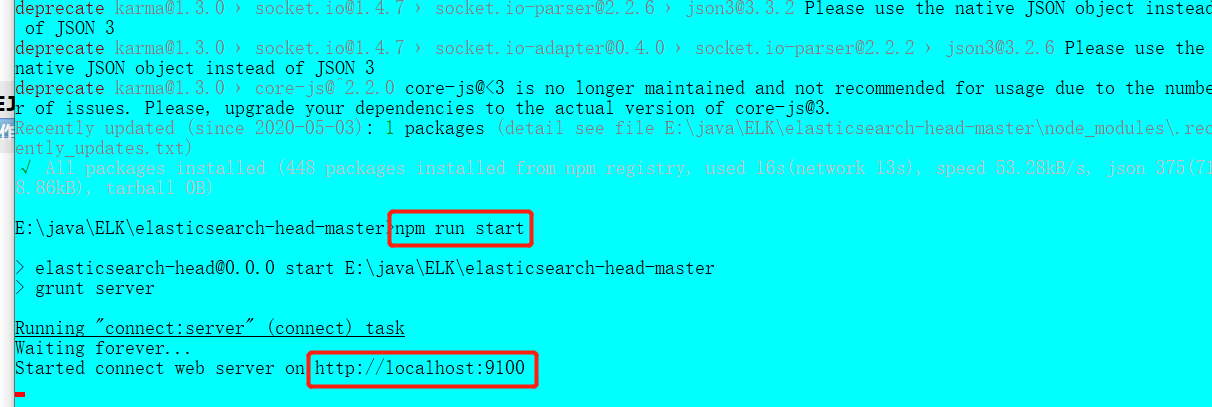
4.执行成功之后启动head
npm run start
5.检验
http://localhost:9100/
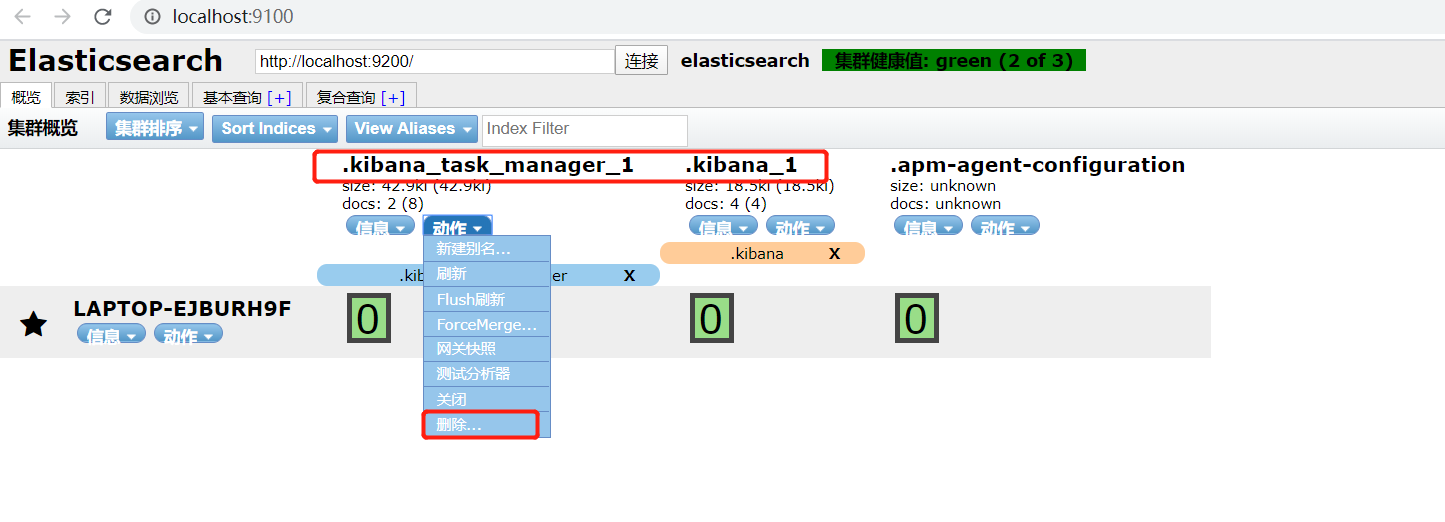
6.将这两个索引删除,重启Kibana就OK了

搭建elsticsearch集群 报错with the same id but is a different node instance解决办法
][o.e.c.c.JoinHelper ] [slave1] failed to join {master}{6AlOPeB3R4yYI4D6cCU7aw}{nr4lP8fLT6K0RoBJ7LCoJA}{192.222.1.222}{192.222.1.222:9300}{dilm}{ml.machine_memory=21370114048, ml.max_open_jobs=20, xpack.installed=true} with JoinRequest{sourceNode={slave1}{6AlOPeB3R4yYI4D6cCU7aw}{SAuV5W3QRRai8nlhxOVgOQ}{192.222.1.222}{192.222.1.222:9301}{dil}{ml.machine_memory=21370114048, xpack.installed=true, ml.max_open_jobs=20}, optionalJoin=Optional[Join{term=22, lastAcceptedTerm=17, lastAcceptedVersion=139, sourceNode={slave1}{6AlOPeB3R4yYI4D6cCU7aw}{SAuV5W3QRRai8nlhxOVgOQ}{192.222.1.222}{192.222.1.222:9301}{dil}{ml.machine_memory=21370114048, xpack.installed=true, ml.max_open_jobs=20}, targetNode={master}{6AlOPeB3R4yYI4D6cCU7aw}{nr4lP8fLT6K0RoBJ7LCoJA}{192.222.1.222}{192.222.1.222:9300}{dilm}{ml.machine_memory=21370114048, ml.max_open_jobs=20, xpack.installed=true}}]}
org.elasticsearch.transport.RemoteTransportException: [master][192.222.1.222:9300][internal:cluster/coordination/join]
Caused by: java.lang.IllegalArgumentException: can't add node {slave1}{6AlOPeB3R4yYI4D6cCU7aw}{SAuV5W3QRRai8nlhxOVgOQ}{192.222.1.222}{192.222.1.222:9301}{dil}{ml.machine_memory=21370114048, ml.max_open_jobs=20, xpack.installed=true}, found existing node {master}{6AlOPeB3R4yYI4D6cCU7aw}{nr4lP8fLT6K0RoBJ7LCoJA}{192.222.1.222}{192.222.1.222:9300}{dilm}{ml.machine_memory=21370114048, xpack.installed=true, ml.max_open_jobs=20} with the same id but is a different node instance
at org.elasticsearch.cluster.node.DiscoveryNodes$Builder.add(DiscoveryNodes.java:612) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.coordination.JoinTaskExecutor.execute(JoinTaskExecutor.java:147) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.coordination.JoinHelper$1.execute(JoinHelper.java:119) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.executeTasks(MasterService.java:702) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.calculateTaskOutputs(MasterService.java:324) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.runTasks(MasterService.java:219) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService.access$000(MasterService.java:73) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.MasterService$Batcher.run(MasterService.java:151) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.TaskBatcher.runIfNotProcessed(TaskBatcher.java:150) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.cluster.service.TaskBatcher$BatchedTask.run(TaskBatcher.java:188) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:633) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252) ~[elasticsearch-7.6.2.jar:7.6.2]
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215) ~[elasticsearch-7.6.2.jar:7.6.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[?:?]
at java.lang.Thread.run(Thread.java:830) [?:?]
因为复制虚拟机时,elsticsearch时,将elsticsearch文件夹下的data文件夹一并复制了。而在前面测试时,data文件夹下已经产生了data数据,于是报上面的错误。
解决办法:删除elsticsearch文件夹下的data文件夹下的节点数据
参考来源:https://blog.csdn.net/ctwctw/article/details/106027078
ES集群配置参考:https://blog.csdn.net/Zereao/article/details/89373246