论文题目:Beyond OCR + VQA: Involving OCR into the Flow for Robust and Accurate TextVQA
论文链接:https://dl.acm.org/doi/abs/10.1145/3474085.3475606
一、任务概述
- 视觉问答任务(VQA):将图像和关于图像的自然语言问题作为输入,生成自然语言答案作为输出。
- 文本视觉问答任务(TextVQA):面向文字识别的问答任务。
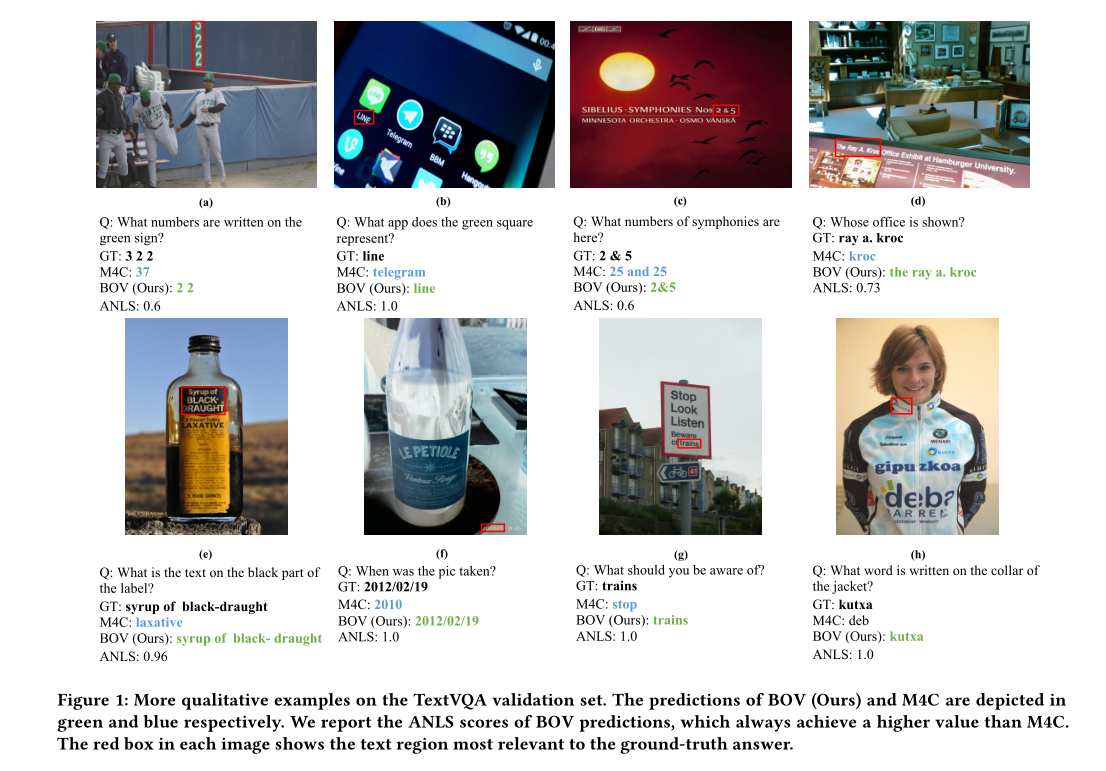
二、Baseline
2.1 Baseline 1: Look, Read, Reason & Answer (LoRRA):
- 2019年提出,推出标准数据集,原文地址:https://arxiv.org/abs/1904.08920v2
- 典型的TextVQA:将问题回答建模为分类任务,需要给定答案空间。
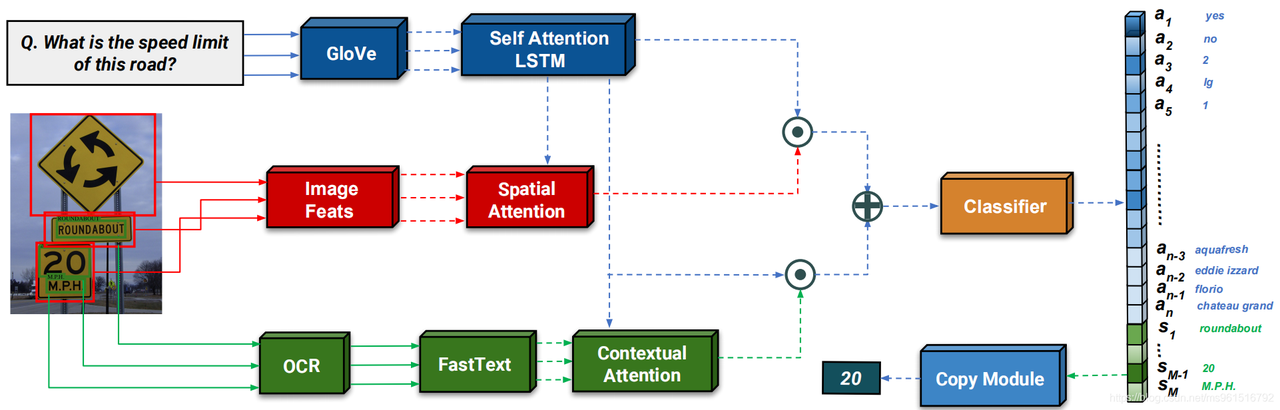
-
多模态嵌入:问题embedding、图像中的物体进行embedding、OCR的结果进行embedding(FastText做pre-train)
- 嵌入方式:
-
- 对问题进行GloVe Embedding,再通过LSTM得到问题嵌入 fQ(q),用于后续对图片特征以及OCR样本进行注意力加权平均。
- 将图像进行特征提取,提取的特征fI(v)与fQ(q)一起经过注意力机制得到加权的空间注意力,得到的结果与fQ(q)进行组合。
![]()
-
- OCR模块基于预训练模型(Faster RCNN + CTC)进行识别,识别出的结果fO(s)与fQ(q)一起经过注意力机制得到加权的空间注意力,得到的结果与fQ(q)进行组合。
![]()
-
- contact一起之后过分类器(MLP),分类的类别为问题空间a1……an 加上 OCR是识别出的词
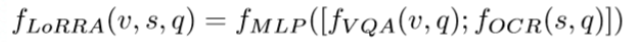
2.2 Baseline 2:M4C
- 主贡献:提出了迭代预测的解码方式,但我们更关注特征表示的部分
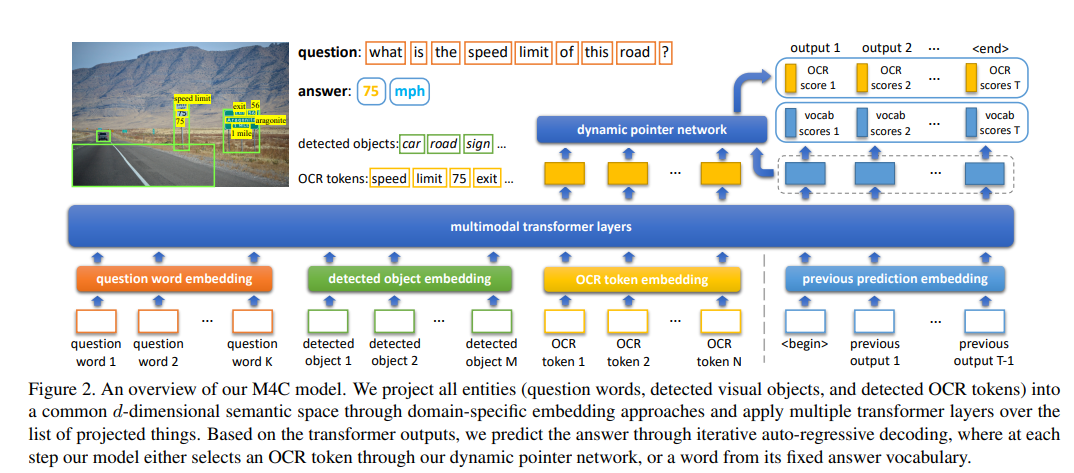
- Question embedding:BERT-base模型的encoder,但只用前3层,得到矩阵shape=(K, d)
- Detected object embedding:Faster-RCNN + Position,shape=(M, d)
- 融合方式:Linear + LayerNorm
- OCR token embedding 由四部分组成:
: 300维的FastText文本特征
: Faster RCNN特征,和detected object的获取方式一样
: 604维的Pyramidal Histogram of Characters(PHOC)特征
: 4维的位置特征,计算方式和detected object一样
- 融合方式:前三个特征过linear后做layernorm,position单独融合,再加起来
![]()
三、Motivation
- OCR的错误识别会较大程度影响多模态信息之间的交互(即fA的过程)
- 因为在表征空间中需要copy OCR识别的token,OCR的错误会较严重的影响解码器的性能(哪怕另两个分支完全准确也没法正确的输出)
四、Method
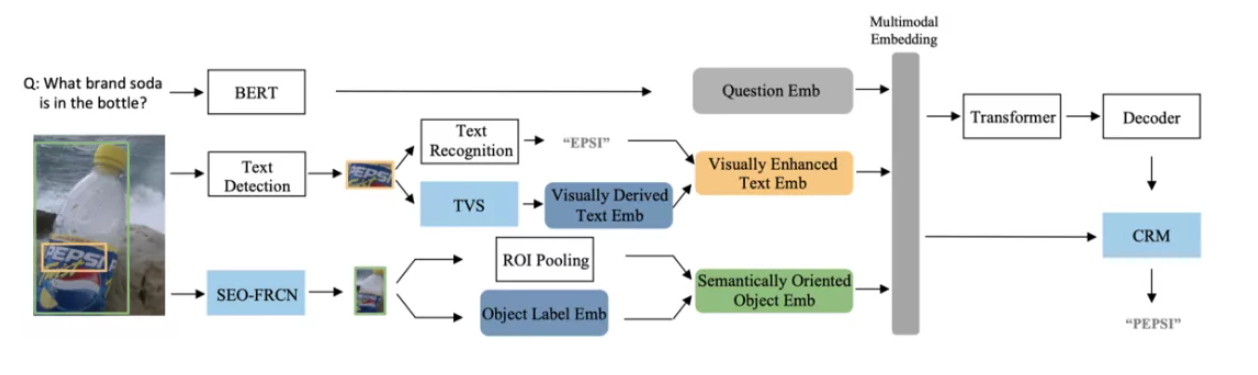
4.1 Contribution
- 增强特征表示的鲁棒性:减小OCR错误和物体识别错误对推理的影响
- 增强解码器的鲁棒性:在答案预测模块提出一个上下文感知的答案修正模块(CRM)对“复制”的答案词进行校正。
4.2 Architectural Details—— 视觉增强的文字表征模块 TVS (OCR增强)
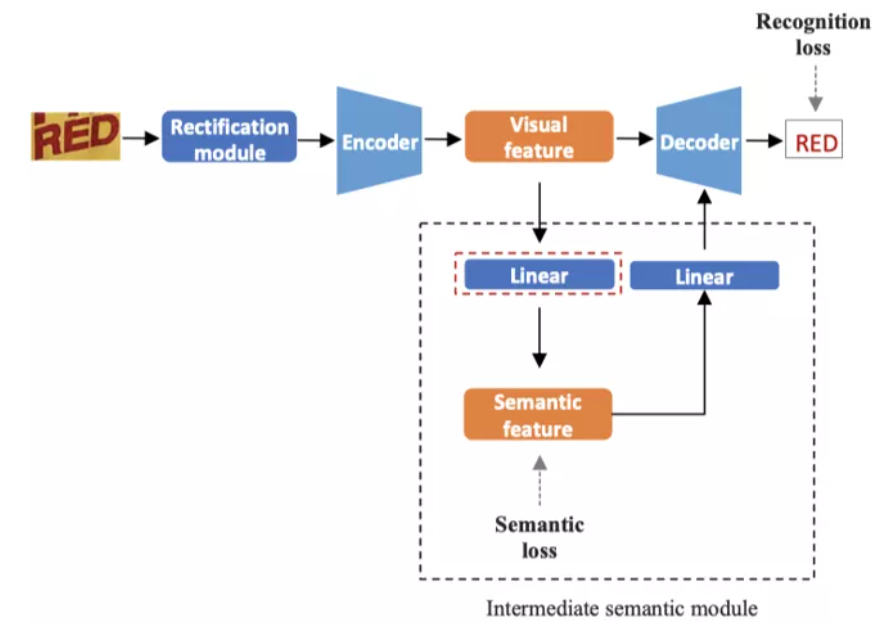
- method:
- 文字图像矫正模块
- 编码模块:45层ResNet+ 2层Bi-LSTM
- 解码模块:单层 注意力机制的GRU
- 中间语义模块:根据文字视觉信息预测语义信息
- train:利用外部数据集训练(SynthText + Synth90K)
- loss: OCR识别损失+语义损失
- 语义损失由真实和预测的语义特征向量间的余弦距离计算得到
- 优势:
- 通过语义损失的监督,编码模块能产生与文字解码更相关的视觉特征
- TVS为直接由文字图像的视觉特性获得语义表示提供可能。
- 整网中推理,OCR token details(n个文本框):
-
: TVS的视觉特征
- 融合方式:
![]()
4.3 Architectural Details—— 语义导向的物体表征 SEO-FRCN(Visual增强)

- method:传统的Faster RCNN,在解码环节增加一个分支来 预测物体类别的embedding
- 物体类别embedding的gt 时物体类别名称的语义特征。
- train:使用Visual Genome数据集,backbone resnet101 预训练,新分支fine tune
- loss:RPN loss + 四分支loss
![]()
- 优势:能够拉近相似物体的图像相似度(例如 traffic light和traffic sign)
- 整网中推理,Visual token details(m个物体):
:视觉特征
- 特征融合:
![]()
4.3 Architectural Details——上下文感知的答案修正 CRM (解码结果增强)

- method:在推理阶段,对于”直接复制OCR结果”进行改进。
- 如果解码的输出指向图像中的文字,则将它视作一个候选词,利用输入的问题、其他文字信息和相关物体信息进行文字修正。
- 使用多个OCR模块输出多个预测结果作为候选集,选出得分最高的结果作为最后的输出。
- 组成:Transformer进行上下文信息融合 + linear&sigmoid 二分类器
- training:如果候选集的结果与gt相同则为1,不同则为0,构建训练数据。二分类预测一个相关分数,最小化交叉熵损失进行训练。
五、Experiment
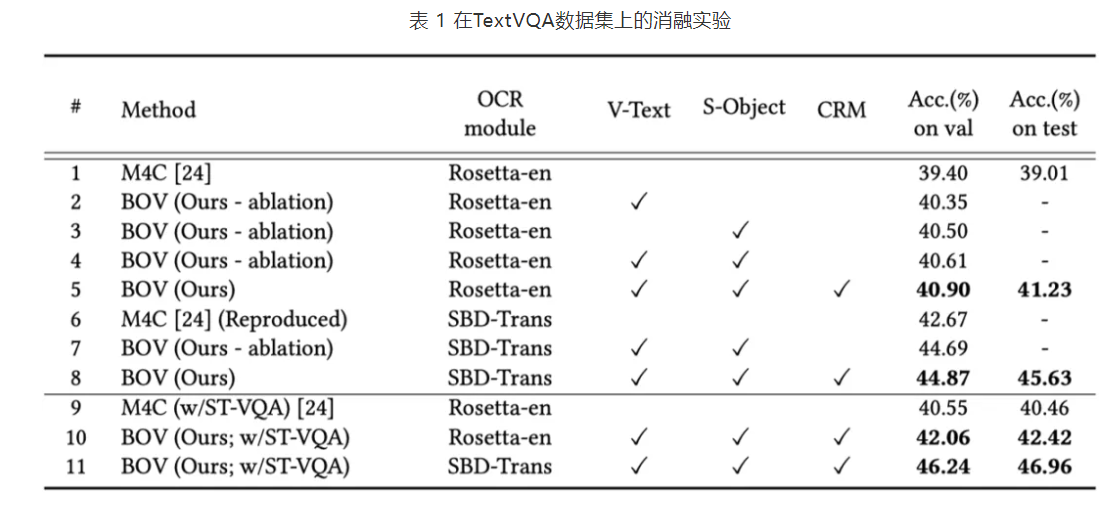
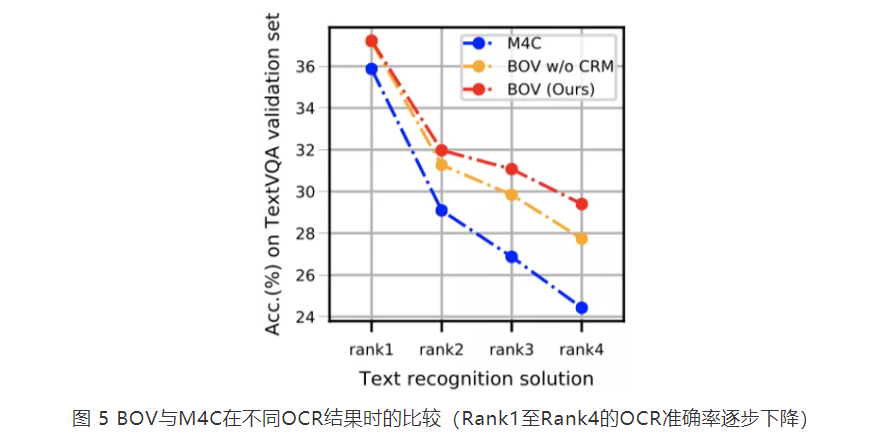
六、结论
- 将OCR融入TextVQA的前向处理流程,构建了一个鲁棒且准确的TextVQA模型
参考博客
[1] https://zhuanlan.zhihu.com/p/250951251
[2] https://mp.weixin.qq.com/s/s7EP8ZiB_0UAv0M4VDhNGA