1、小程序的发展
jsbridge -> js-sdk -> 小程序
- 腾讯内部使用的jsbridge,被外部发现,并使用,逐渐成为微信中网页的事实标准。后提供了外部使用的js-sdk,之后为了提供更丰富的能力,提供小程序。
- 小程序中js的组成:
小程序的逻辑层和渲染层是分开的,逻辑层运行在 JSCore 中,并没有一个完整浏览器对象,因而缺少相关的DOM API和BOM API。
2、后端技术
后端可通过微信提供的云服务和自己搭建服务端来实现,两者的区别如下:
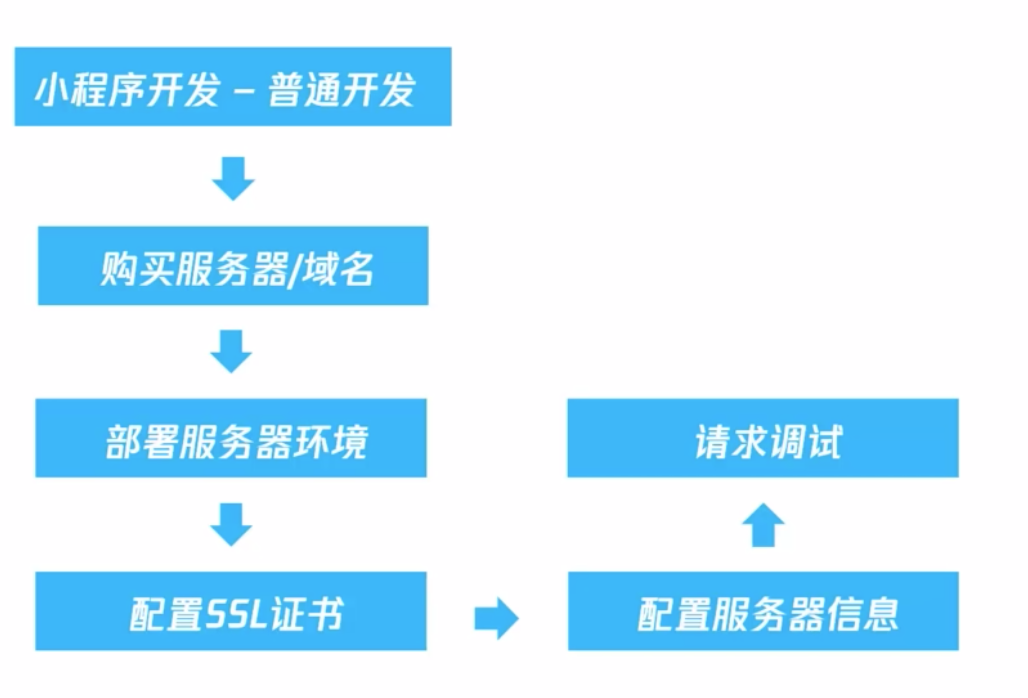
可以看到,使用自己搭建的服务端,需要一定的运维能力,需要提供数据库、https接口等,成本比较大。对于个人开发者,或者没有相关服务器、运维能力的团队,可以使用云服务。
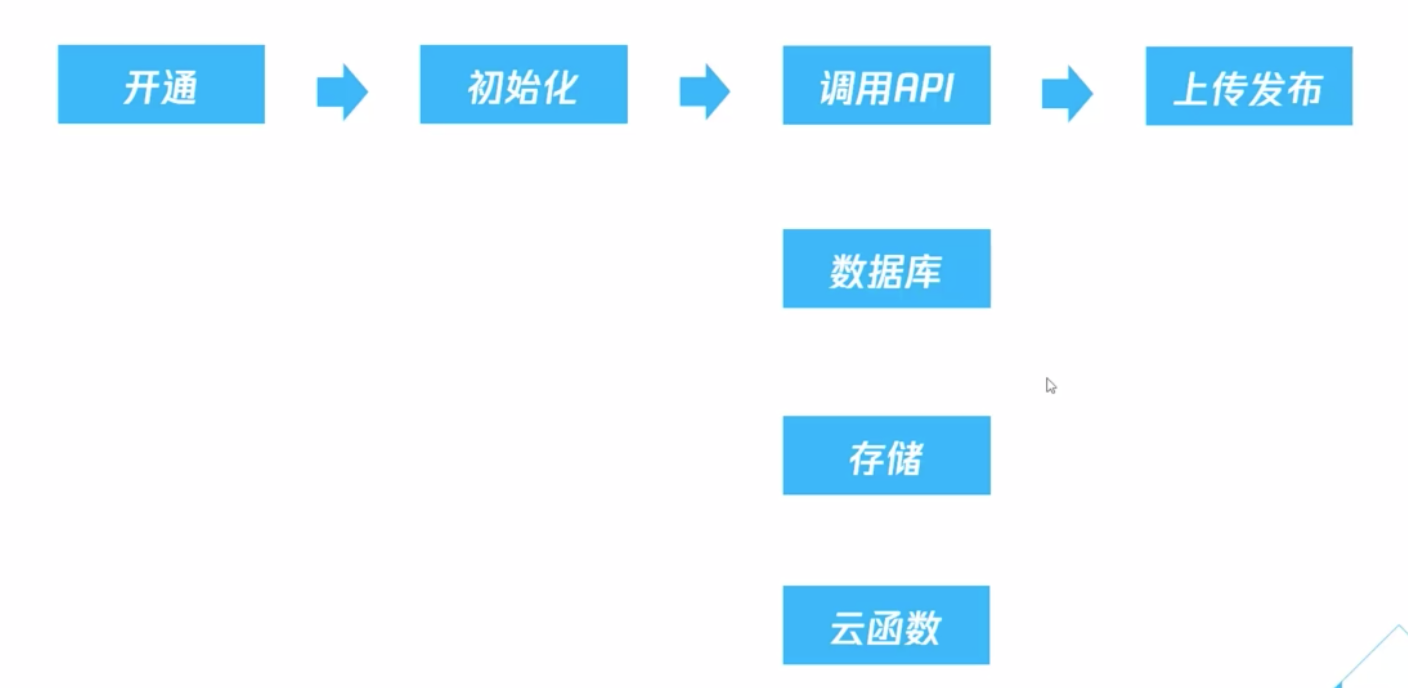
3、云开发的流程
在下面的demo事例中,将提供相应云开发具体操作方式。
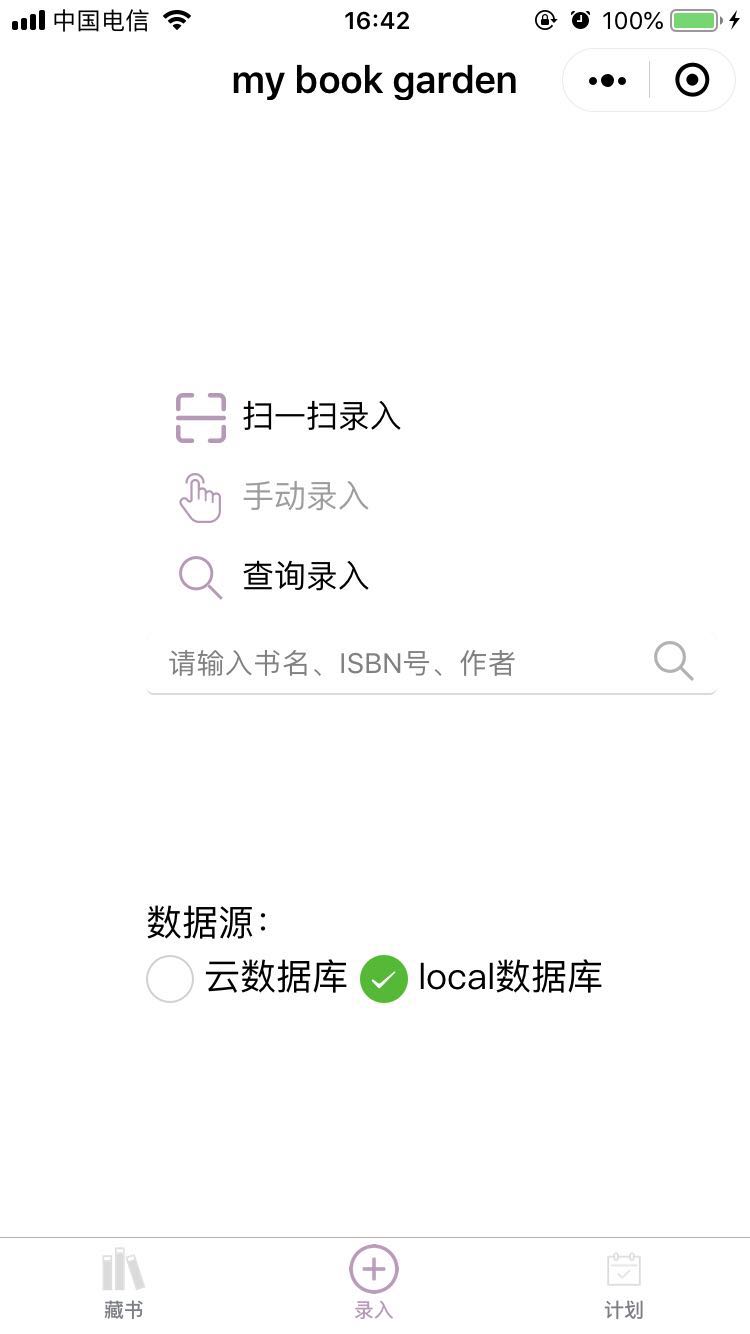
4、藏书馆demo体验
demo功能说明:
提供了书本的扫码、查询录入功能,将家中的图书管理起来。其中由于豆瓣的书本查询api关闭,最终通过网页爬虫,实现在线书本信息收集的工作。通过将书本信息存入提取,录入到数据库中,形成自己的在线书库。
功能部分:
- 1、微信扫码识别条形码 or 手动输入作者、书名、isbn查询
- 2、亚马逊网页爬虫
- 3、数据录入数据库中
本示例提供了两种服务端,nodejs + mongodb自建;及云服务。将提供两者的实现方法。
上截图:

4.1、微信扫码识别条形码
wx.scanCode({
success (res) {
that.searchBookList(res.result);
},
fail(err) {
console.log('fail', err);
}
});
微信提供条形码识别的api,直接调用即可~~生成以后,通过亚马逊网页爬虫爬取信息。
4.2、亚马逊网页爬虫
由于豆瓣的图书api禁用,只能通过网页爬虫的方式去获取相关的信息,对比了豆瓣、当当、京东、亚马逊、几个在线图书馆,最终选择了亚马逊。区别对比:
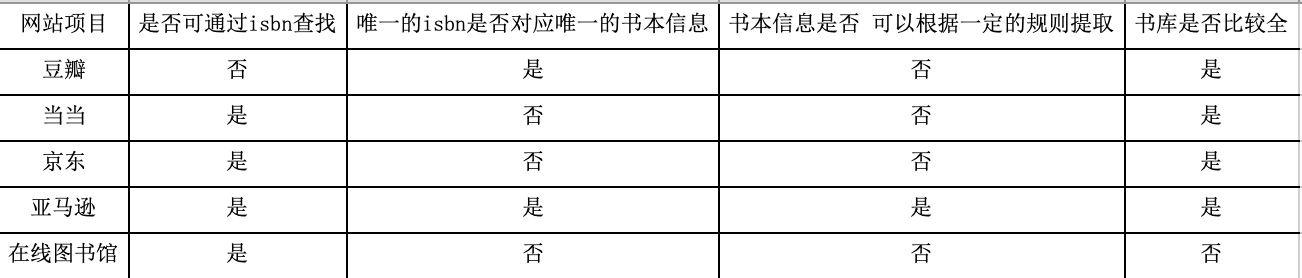
从对比表格可以看出,仅仅亚马逊可以作为图书信息收集的渠道,但也会出现不稳定的情况,有时候需要多次请求才可取到。豆瓣做了相应的规避爬虫的处理,书本信息无法读取到(爬了几次,ip被豆瓣放入了黑名单。。。)。当当、京东比较尴尬的点是,它的查询结果包含其他第三方书店的结果信息,导致一个isbn对应很多的结果记录,在后面做作者、书名的查询扩展时,比较难过滤,所以丢弃。在线图书馆情况就更多,信息杂乱,书目不全等,丢弃。综合以上,最终选用亚马逊网页来实现书本信息的收集。
包含两个爬虫:
- 1、根据作者、书名、isbn查询书目列表;
- 2、step1 里的亚马逊详情链接,跳转到详情页,读取具体书本详细信息。
step1: 搜索结果爬虫
// 需要使用encodeURI进行编码,处理中文问题
const bookInfoDomain = 'https://www.amazon.cn';
rp(bookInfoDomain + '/s?k=' + encodeURI(event.params.searchValue + '&i=stripbooks')).then(html => {
return getBookBaseInfo(html);
}).catch(err => {
console.log(err)
});
书本查询结果列表的搜索结果,(搜索书名“自立”的结果)如图所示:
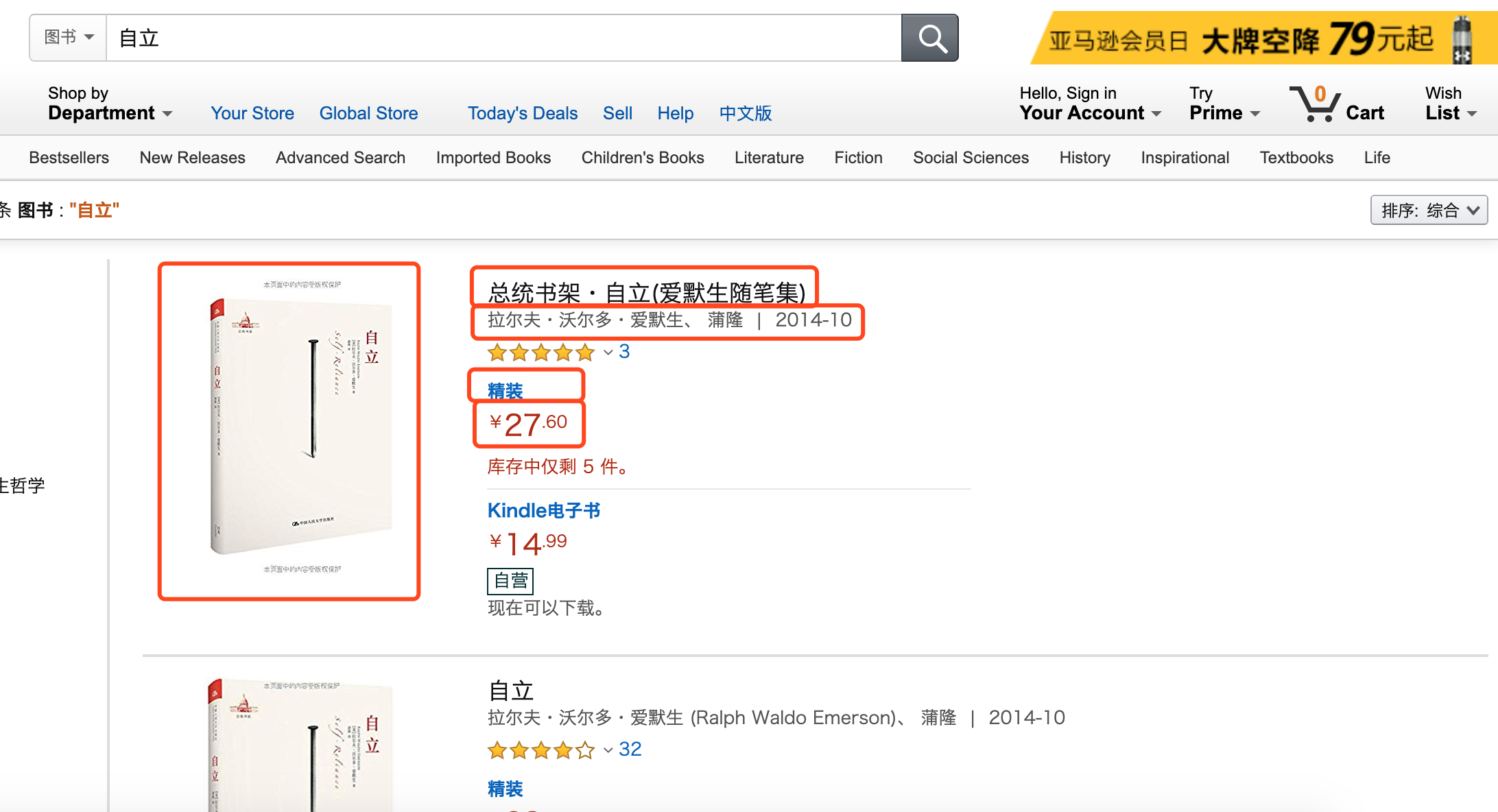
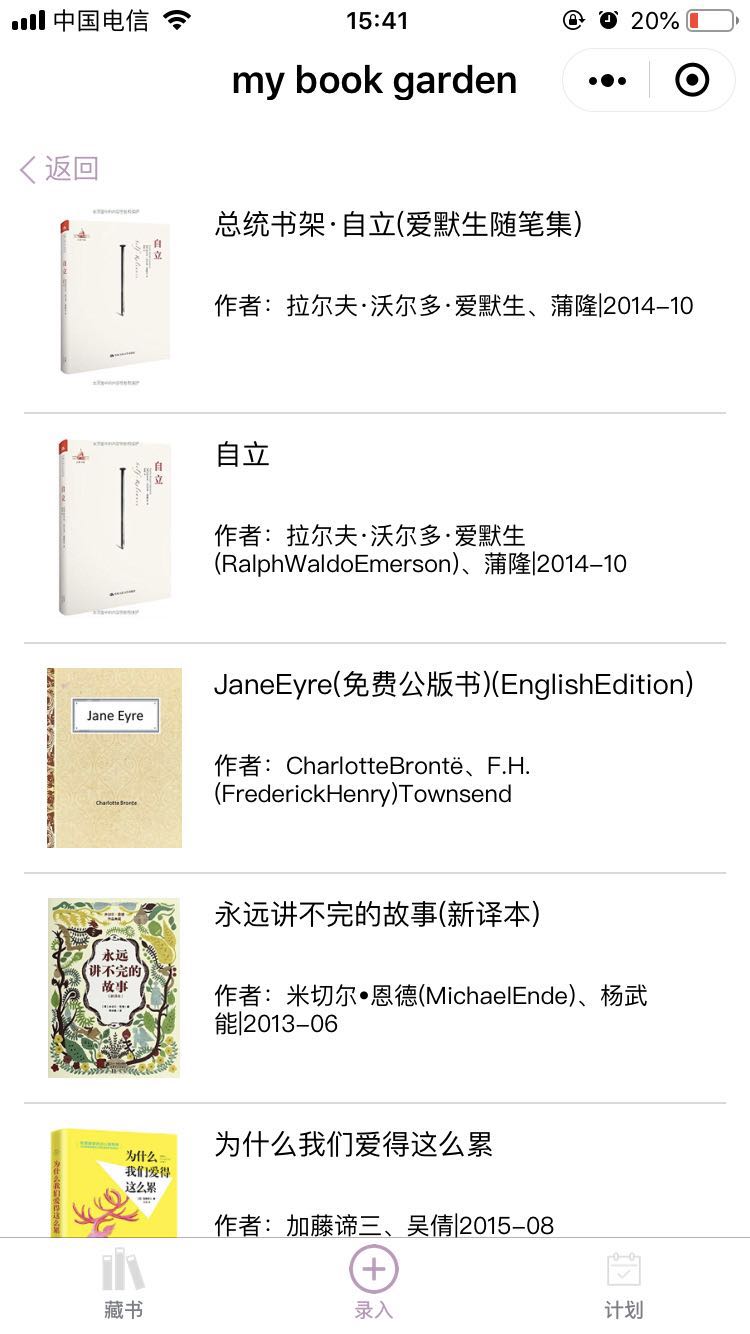
左边为亚马逊的图书列表,其中红线框中的信息为需要提取的图书信息;右边为提取相关信息后,在小程序端展现的搜索结果列表。
通过分析结果页的dom结构,来提取相关信息,代码:
let bookHtmlList = [];
if (htmlString) {
let $ = cheerio.load(htmlString);
$('.s-search-results .s-result-item').each((i, e) => {
let href = $(e).find("[data-component-type='s-product-image'] a").attr('href');
let logo = $(e).find(".s-image").attr('src');
let name = $(e).find("h2").text();
let price = ($(e).find(".a-spacing-top-small .a-offscreen").text() || '').replace(/[^0-9|.]/ig,"");
bookHtmlList.push({......}); // 省略
})
}
return bookHtmlList;
使用cheerio来解析html串,其使用jquery的核心实现,可在服务端,直接像jquery一样使用。在列表页提取了href,为书本详情页的跳转做准备。
step2:详情页爬虫
书本详情的结果如图所示:
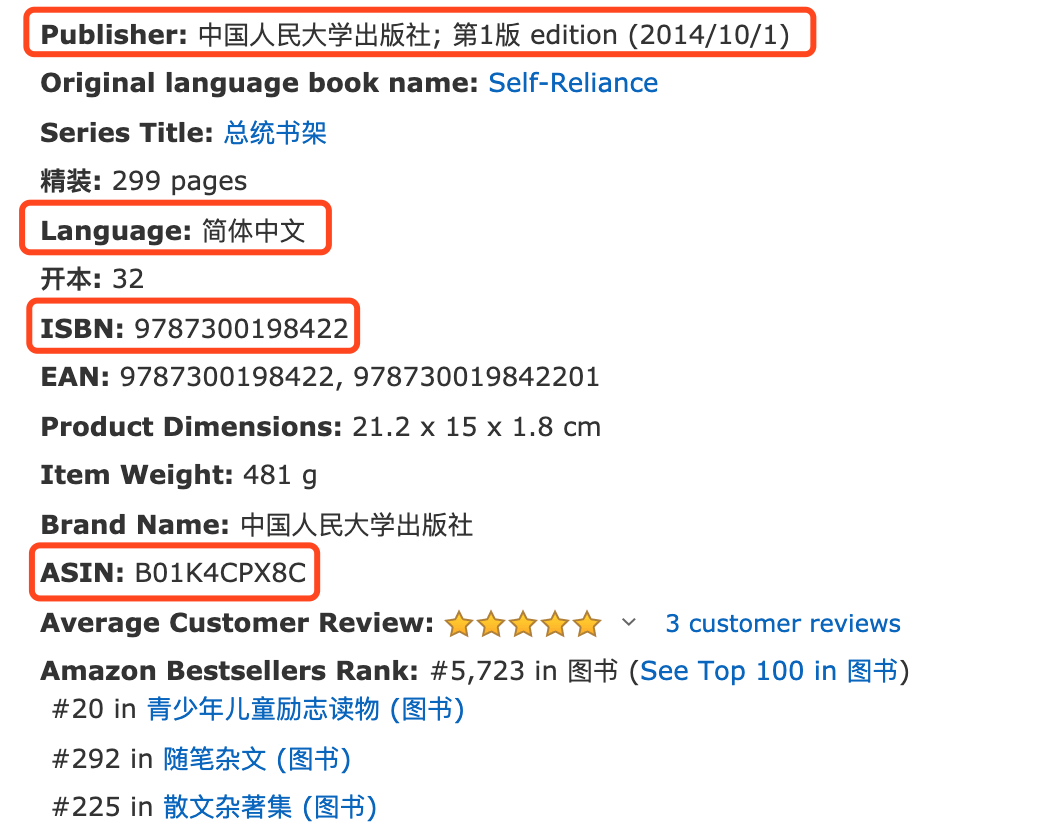

左图为亚马逊的图书列表,右图为小程序收集到相关信息的展示页:
总结:爬虫的重点为 找到核心、有效信息的网页,再使用cheerio进行解析,最后按照需要,使用类jquery api提取信息即可。
4.3、数据录入数据库中
这里提供了两种服务提供方式:
- a、本地nodejs + mongodb
- b、小程序自带云服务
本地nodejs + mongodb
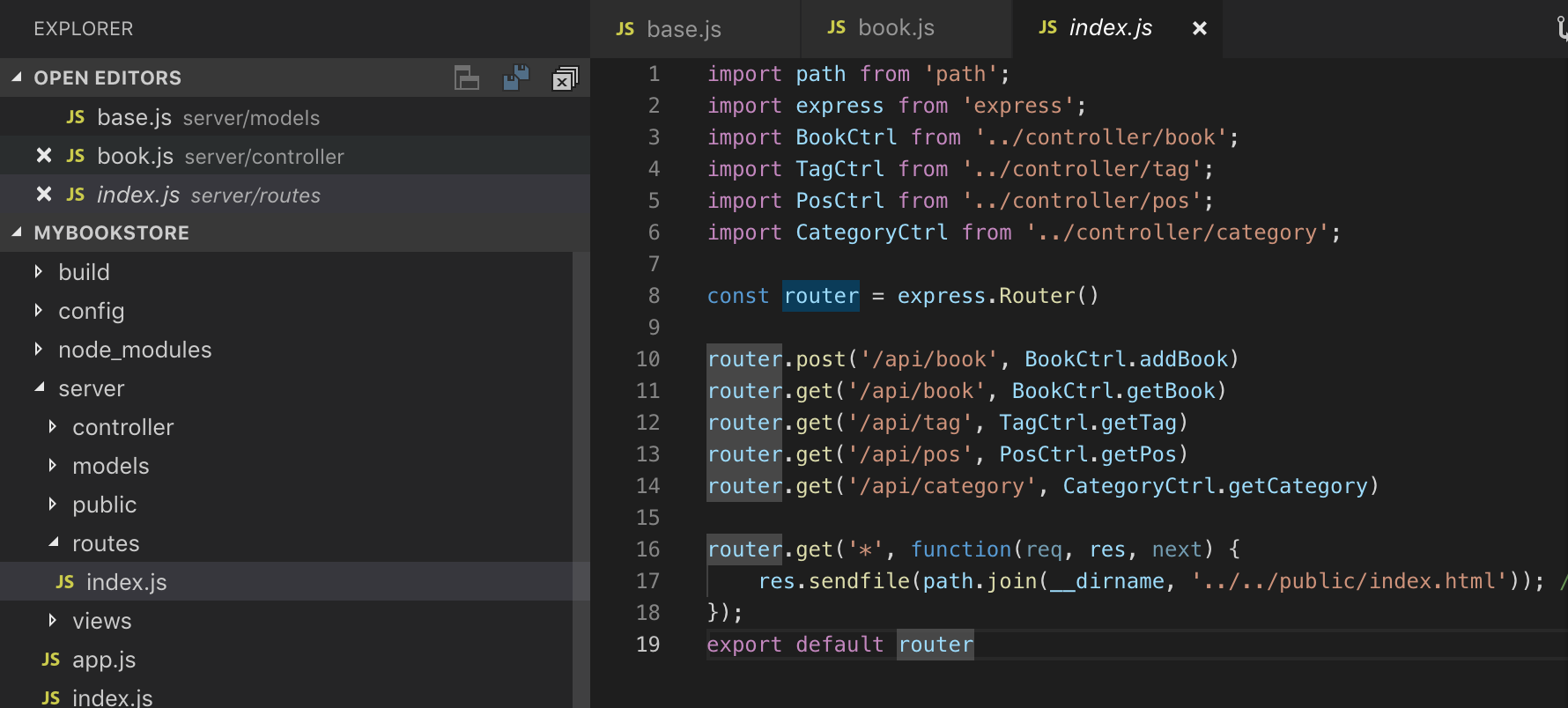
如上图,为nodejs + mongodb的服务端代码结构,通过提供api的方式,提供数据服务。当然,上线之后,需要提供ssh证书,仅https协议的访问才被允许;在小程序的配置当中,需要将相关的服务域名进行配置(另外,小程序没有cookie、session的机制,如果服务端是做迁移的,需要在这方面做下融合)。
小程序自带云服务
云服务的部署、运维,现在就看看具体如何操作:
-
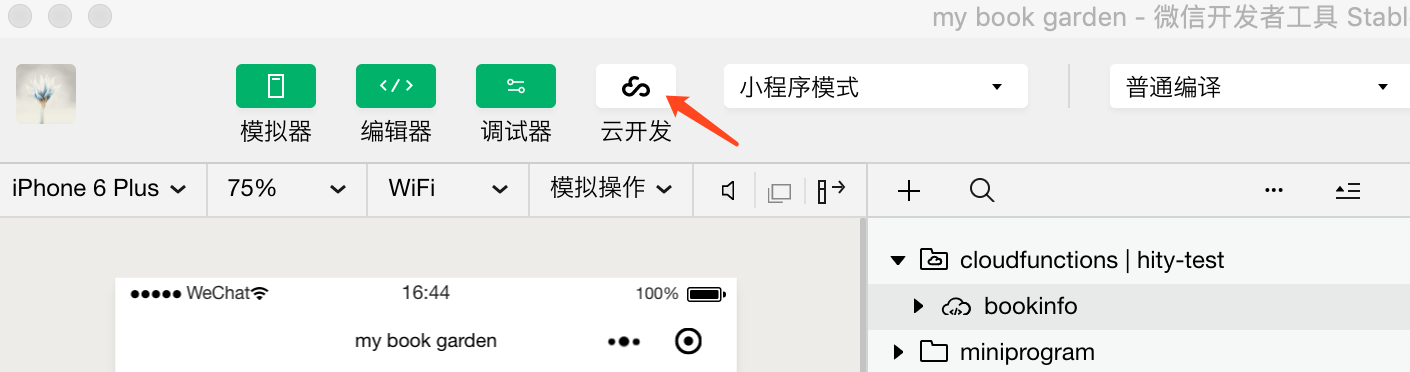
step1:生成云开发的账号,通过小程序的devtools,点击"云开发"去生成,如下图所示;
-
step2:创建云开发目录,一般与小程序项目同级;
-
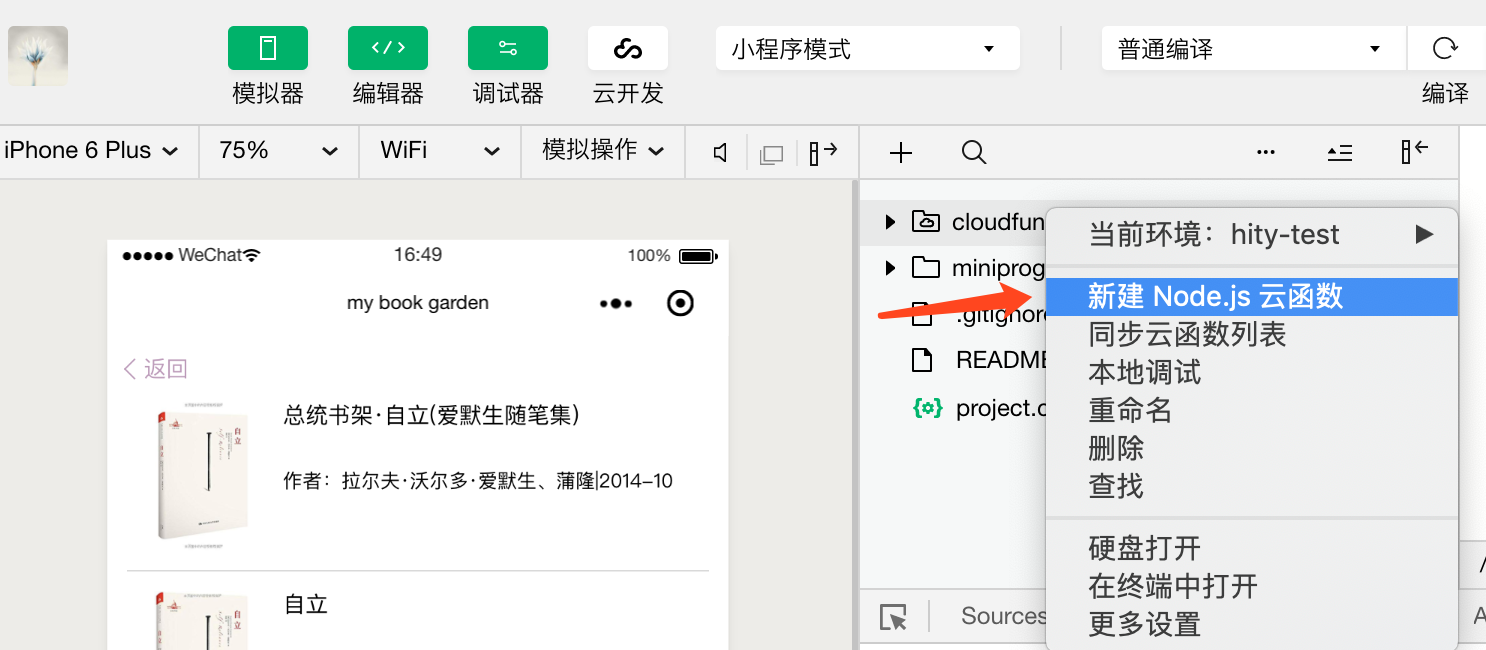
step3:新建云函数,在生成的云函数目录内(该目录为云函数的名称),进行npm install,安装相关的组件;(小程序通过云函数,与云服务进行交互)
-
step4:进行相关云开发的配置,配置方法如下:
a、project.config.json里添加:
{"cloudfunctionRoot": "cloudfunctions/",}b、app.js的配置
// 进行云服务的初始化 onLaunch: function () { if (!wx.cloud) { console.error('请使用 2.2.3 或以上的基础库以使用云能力') } else { wx.cloud.init({ traceUser: true, }) } ...... } -
step5: 云函数使用
a、调用云函数
// 亚马逊查找相应的书本 wx.cloud.callFunction({ name: 'bookinfo', data: { type: 'search', params: { searchValue } }, success: data => { ...... }, fail: err => { ...... } })b、云函数接收
// 云函数入口函数 exports.main = async (event, context) => { ...... return rst; }其中event的属性与data一样,可通过event,使用data中传递的值信息。
-
step6: 数据库的使用
const bookStoreDb = cloud.database(); const bookCollection = bookStoreDb.collection('book'); const _ = bookStoreDb.command let whereInfo = {}; if (event.params.searchValue) { whereInfo = _.or([ { author: {$regex: '.*'+ event.params.searchValue} }, { isbn: {$regex: '.*'+ event.params.searchValue} }, { name: {$regex: '.*'+ event.params.searchValue} }, ]) } // 一次最多查询100个记录,total大于100,需要多次请求,拼合 rst = await bookCollection.where(whereInfo).get().then(res => { ...... }); return rst;
5、其他
- 基础布局方法flex
阮一峰的博客:flex布局介绍 http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html - js事件循环机制
之前有写过相关博客: https://www.cnblogs.com/hity-tt/p/6733062.html - 样式库
小程序的ui组件库比较多,相关的介绍如下:
https://www.jianshu.com/p/4182f4a18cb6
其中的weUI是微信团队开发的,相关使用说明如下:
https://www.jianshu.com/p/010cea4202b8