- 配置items.py文件
8 import scrapy 9 10 11 class DoubandyItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 title = scrapy.Field() 15 bd = scrapy.Field()
16 star = scrapy.Field() 17 quote = scrapy.Field() - 配置setting.py文件
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, lik e Gecko) Chrome/17.0.963.56 Safari/535.11' ROBOTSTXT_OBEY = False COOKIES_ENABLED = False ITEM_PIPELINES = { 'doubandy.pipelines.DoubandyPipeline': 300, }
- 配置srapy.py文件
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from doubandy.items import DoubandyItem 4 5 class DbdySpider(scrapy.Spider): 6 name = 'dbdy' 7 allowed_domains = ['douban.com'] 8 offset = 0 9 url = 'https://movie.douban.com/top250?start=' 10 start_urls = [url + str(offset)] 11 12 def parse(self, response): 13 item = DoubandyItem() 14 movies = response.xpath("//div[@class='info']") 15 16 for each in movies: 17 18 item['title'] = each.xpath(".//span[@class='title'][1]/text()").extract()[0] 19 20 item['bd'] = each.xpath(".//div[@class='bd']/p/text()").extract()[0] 21 22 item['star'] = each.xpath(".//div[@class='star']/span[@class='rating_num']/text ()").extract()[0]
24 quote = each.xpath(".//p[@class='quote']/span/text()").extract()
25 if len(quote) != 0:
26 item['quote'] = quote[0]
27
28
29 yield item
30
31 if self.offset < 225:
32 self.offset += 25
33 yield scrapy.Request(self.url + str(self.offset),callback = self.parse) - 配置pipelines.py文件
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 8 import pymongo 9 from scrapy.conf import settings 10 11 class DoubandyPipeline(object): 12 def __init__(self): 13 host = '127.0.0.1' 14 port = 27017 15 dbname = 'douban' 16 sheetname = 'doubanmovies' 17 18 client = pymongo.MongoClient(host = host, port = port) 19 20 mydb = client[dbname] 21 22 self.post = mydb[sheetname] 23 24 def process_item(self, item, spider): 25 data = dict(item) 26 self.post.insert(data) 27 28 return item
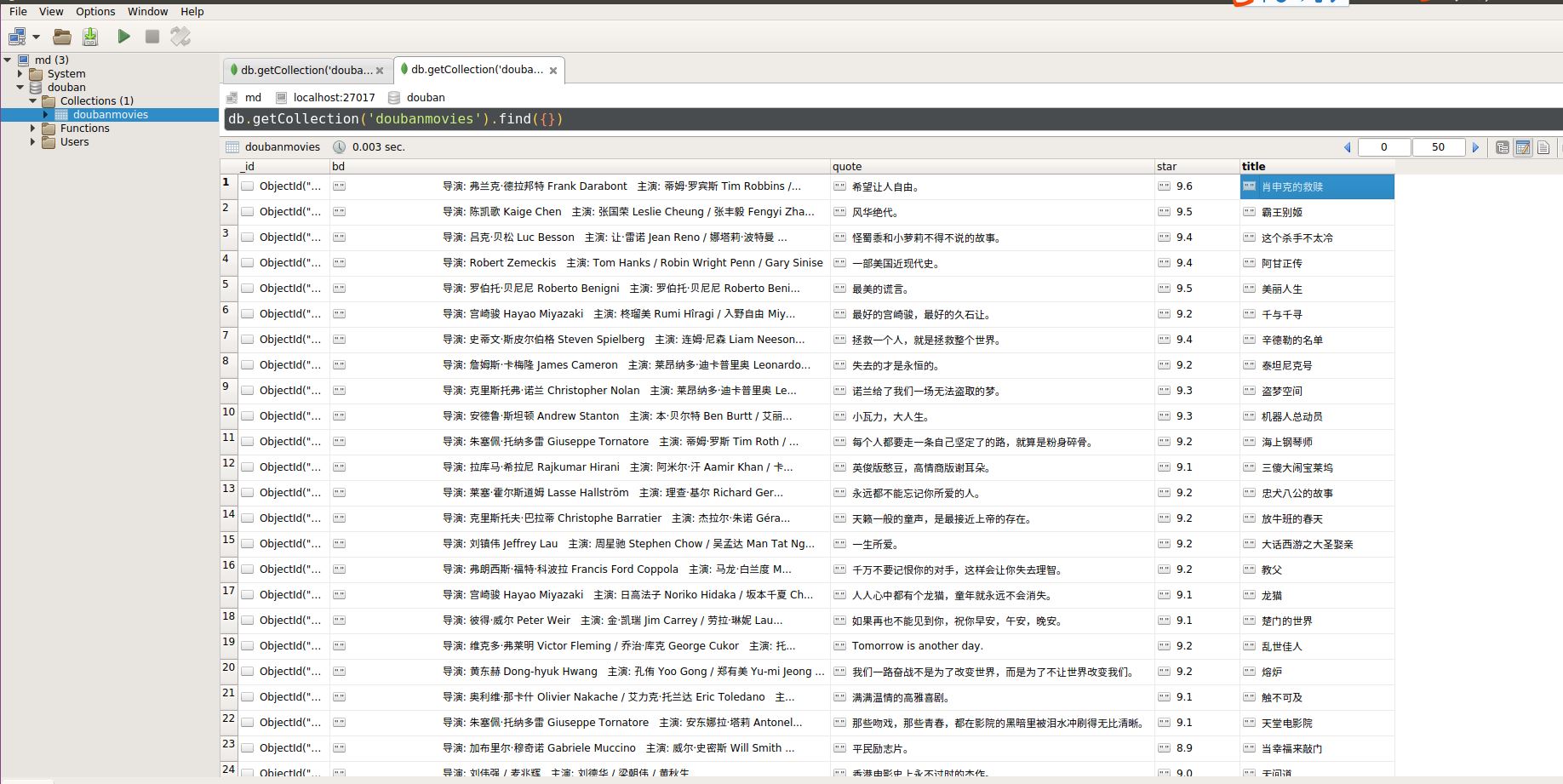
数据展示: