( 这篇博文为原创,如需转载本文请email我: leizhao.mail@qq.com, 并注明来源链接,THX!)
本文主要分享了一篇来自CVPR 2018的论文,A Closer Look at Spatiotemporal Convolutions for Action Recognition。这篇论文主要介绍了Video Classification、Action Recognition方面的工作,包括2D、3D以及混合卷积等多种方法,最重要的贡献在于提出(2+1)D的结构。
1. Related Work

图1 视频领域深度学习方法发展
在静态图像任务(Object Detection、Image Classification等)中,深度学习的引入产生了巨大影响。但在视频领域,深度网络在引入之初显得有些乏力,于是针对2D网络对视频任务适应性改进的工作开始成为流行。一种思路是保留2D网络用于空间推理,另外通过2D对Optical Flow或者3D对RGB进行时间推理,比如Two-Stream就属于前者,ARTNet属于后者。另一种思路是将2D核换成3D核,直接时空混合卷积,C3D是这种思路的体现。而后的P3D将时空操作分解,ARTNet和FstNet也是出于同样的考虑。I3D另辟蹊径,使得之前的2D网络在视频领域仍然能发挥pre-train的作用。更重要的是,我认为2017年提出的Kinetics数据集可以称为“视频领域的ImageNet”,极大地扩充了数据量。今年,研究人员开始关注Relationship,很多Long-term的结构被提出。
2. Motivation
在Section 1,我阐述了在视频任务中出现的几种思路,本文是对其中“时空分解”的研究。单独的2D网络对于视频任务能力有限,3D网络的主要问题体现在参数量上(比如ResNet-18 2D的参数量为11.4M,同样结构的3D网络参数量为33.4M,如果50或者101会更多),这会带来很多问题,诸如过拟合、更难训练等。既然单纯的2D或者3D都不太好,时空分解或许值得尝试,作者提出的时空分解具体分为混合卷积(Mixed Convolution)和(2+1)D。
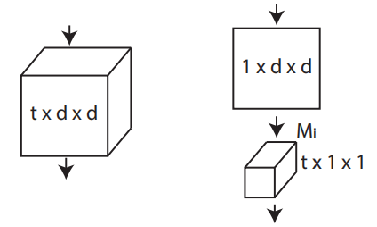
图2 作者提出的(2+1)D模块
(图2来自:D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri.
A Closer Look at Spatiotemporal Convolutions for Action Recognition.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.)
根据论文中作者的描述,他提出的MCx、rMCx和(2+1)D,是2D与3D的Middle Ground,混合卷积可以用更少的参数量取得与3D相当的Performance。(2+1)D对时空表达做了解构,这样可以获得额外的非线性(由于Factorization可以增加一个额外的ReLU层)。
3. Detail
上一部分中提到了3D模型参数量大的问题,使用(2+1)D可以有效减少参数量。但是参数量少了,模型的复杂度与表达能力会相应减弱,为了在同等参数量的前提下比较融合的时空信息与分解的时空信息的有效性,作者提出可以通过一个超参数M,将时空分解后的参数量恢复至分解前,如公式1所示。
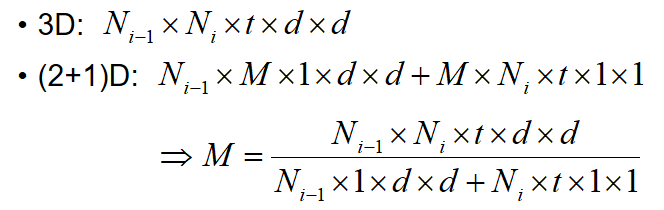
公式1 用于参数恢复的超参数M
4. Experiment
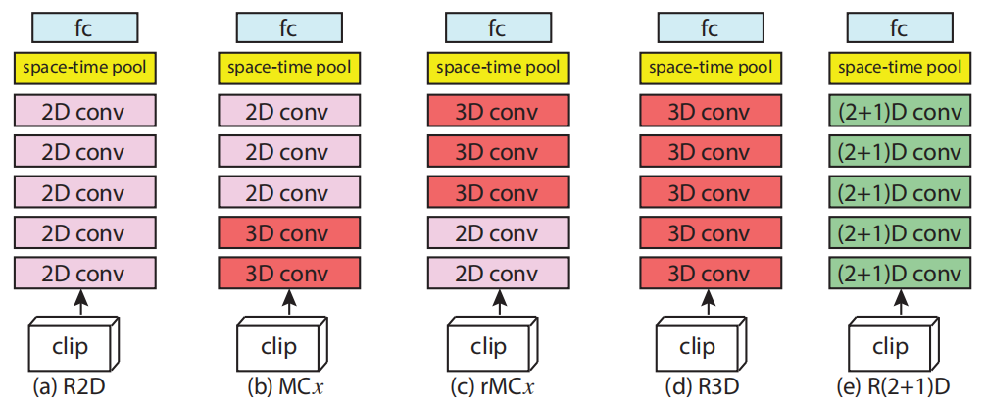
图3 原文实验的几种结构
(a)R2D结构示意图;(b)Mixed Convolution(MC)结构示意图,x指明2D与3D卷积层的分界点;
(c)reversed Mixed Convolution(MC),x的意义与(b)相同;(d)R3D结构示意图;(e)R(2+1)D结构示意图。
(图3来自:D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri.
A Closer Look at Spatiotemporal Convolutions for Action Recognition.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.)
作者使用了五种网络结构用于对比实验(图3),MC结构的提出是基于这样一种Hypothesis:对于Motion/Temporal这种信息的提取,应该在网络的底层进行,因为到了高层之后的信息是高度抽象的,而非具体的。实验的结果如表1所示,R2D的表现最差,但是从绝对角度而言,这种几乎完全舍弃时间信息的结构能够达到58.9,也说明了空间信息对于行为理解、场景理解的重要作用。3D模型的表现相比较2D大约有5个百分点的提升,但是参数量增加了两倍。混合卷积的各种Variant都表现良好,但是却无法印证之前的假设,似乎参数量更为重要。(2+1)D结构,通过将参数恢复到与3D模型一致后,其结果比3D高3.8个百分点,这说明了时空分解确实产生了作用。
总结:
(1)在视频任务中,3D模型比2D模型更适用;
(2)3D模型参数量比较大,使用参数量更小的混合卷积,可以取得与3D模型相当的成绩;
(3)时空信息分解后,会带来更好的表现。
表 1 实验结果
(表中数据来自:D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri.
A Closer Look at Spatiotemporal Convolutions for Action Recognition.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.)

如有疑惑或发现错误,欢迎邮件联系:leizhao.mail@qq.com
本文所分享的这篇论文来自CVPR 2018:
D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun and M. Paluri. A Closer Look at Spatiotemporal Convolutions for Action Recognition. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.