作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
Hadoop的起源
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
总结起来,Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变关系
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
Hadoop发展史
Hadoop大事记
2004年— 最初的版本(现在称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
2005年12月— Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
2006年1月— Doug Cutting加入雅虎。
2006年2月— Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年2月— 雅虎的网格计算团队采用Hadoop。
2006年4月— 标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
2006年5月— 雅虎建立了一个300个节点的Hadoop研究集群。
2006年5月— 标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
2006年11月— 研究集群增加到600个节点。
2006年12月— 标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
2007年1月— 研究集群到达900个节点。
2007年4月— 研究集群达到两个1000个节点的集群。
2008年4月— 赢得世界最快1TB数据排序在900个节点上用时209秒。
2008年7月— 雅虎测试节点增加到4000个
2008年9月— Hive成为Hadoop的子项目
2008年11月— Google宣布其MapReduce用68秒对1TB的程序进行排序
2008年10月— 研究集群每天装载10TB的数据。
2008年— 淘宝开始投入研究基于Hadoop的系统–云梯。云梯总容量约9.3PB,共有1100台机器,每天处理18000道作业,扫描500TB数据。
2009年3月— 17个集群总共24 000台机器。
2009年3月— Cloudera推出CDH(Cloudera’s Dsitribution Including Apache Hadoop)
2009年4月— 赢得每分钟排序,雅虎59秒内排序500 GB(在1400个节点上)和173分钟内排序100 TB数据(在3400个节点上)。
2009年5月— Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
2009年7月— Hadoop Core项目更名为Hadoop Common;
2009年7月— MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
2009年7月— Avro 和 Chukwa 成为Hadoop新的子项目。
2009年9月— 亚联BI团队开始跟踪研究Hadoop
2009年12月—亚联提出橘云战略,开始研究Hadoop
2010年5月— Avro脱离Hadoop项目,成为Apache顶级项目。
2010年5月— HBase脱离Hadoop项目,成为Apache顶级项目。
2010年5月— IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2010年9月— Hive( Facebook) 脱离Hadoop,成为Apache顶级项目。
2010年9月— Pig脱离Hadoop,成为Apache顶级项目。
2011年1月— ZooKeeper 脱离Hadoop,成为Apache顶级项目。
2011年3月— Apache Hadoop获得Media Guardian Innovation Awards 。
2011年3月— Platform Computing 宣布在它的Symphony软件中支持Hadoop MapReduce API。
2011年5月— Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
2011年5月— HCatalog 1.0发布。该项目由Hortonworks 在2010年3月份提出,HCatalog主要用于解决数据存储、元数据的问题,主要解决HDFS的瓶颈,它提供了一个地方来存储数据的状态信息,这使得 数据清理和归档工具可以很容易的进行处理。
2011年4月— SGI( Silicon Graphics International )基于SGI Rackable和CloudRack服务器产品线提供Hadoop优化的解决方案。
2011年5月— EMC为客户推出一种新的基于开源Hadoop解决方案的数据中心设备——GreenPlum HD,以助其满足客户日益增长的数据分析需求并加快利用开源数据分析软件。Greenplum是EMC在2010年7月收购的一家开源数据仓库公司。
2011年5月— 在收购了Engenio之后, NetApp推出与Hadoop应用结合的产品E5400存储系统。
2011年6月— Calxeda公司(之前公司的名字是Smooth-Stone)发起了“开拓者行动”,一个由10家软件公司组成的团队将为基于Calxeda即将推出的ARM系统上芯片设计的服务器提供支持。并为Hadoop提供低功耗服务器技术。
2011年6月— 数据集成供应商Informatica发布了其旗舰产品,产品设计初衷是处理当今事务和社会媒体所产生的海量数据,同时支持Hadoop。
2011年7月— Yahoo!和硅谷风险投资公司 Benchmark Capital创建了Hortonworks 公司,旨在让Hadoop更加鲁棒(可靠),并让企业用户更容易安装、管理和使用Hadoop。
2011年8月— Cloudera公布了一项有益于合作伙伴生态系统的计划——创建一个生态系统,以便硬件供应商、软件供应商以及系统集成商可以一起探索如何使用Hadoop更好的洞察数据。
2011年8月— Dell与Cloudera联合推出Hadoop解决方案——Cloudera Enterprise。Cloudera Enterprise基于Dell PowerEdge C2100机架服务器以及Dell PowerConnect 6248以太网交换机
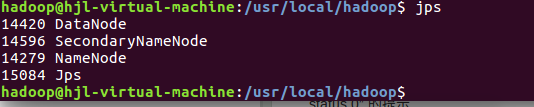
截图: