
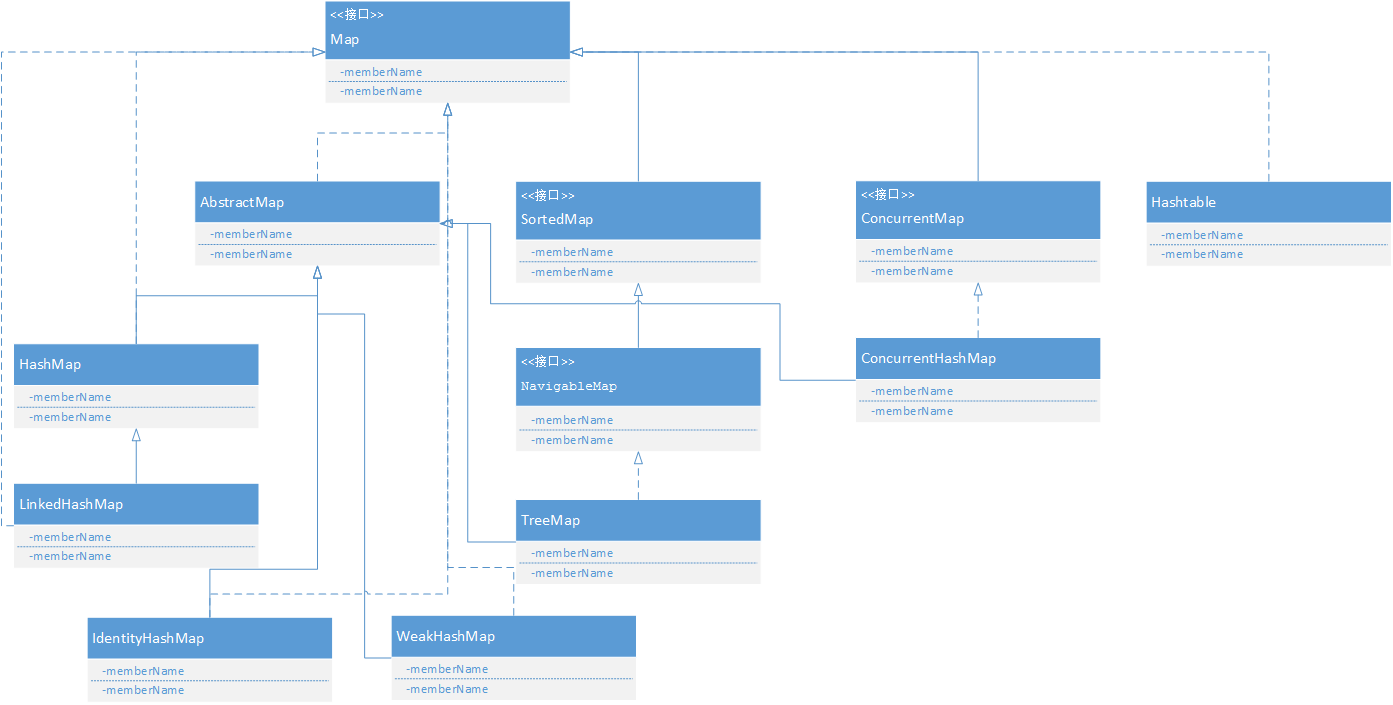
缩略图如下图所示:图中,实线边框的是实现类,折线边框的是抽象类,而点线边框的是接口
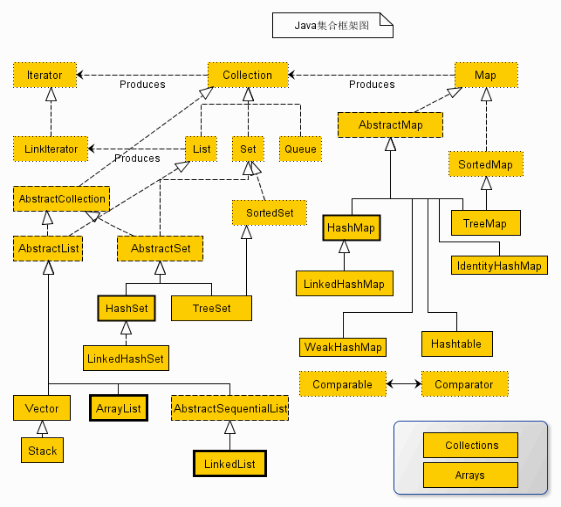
在JAVA的util包中有两个所有集合的父接口Collection和Map,它们的父子关系:
set --其中的值不允许重复,无序的数据结构
list --其中的值允许重复,因为其为有序的数据结构
map--成对的数据结构,健值必须具有唯一性(键不能同,否则值替换)
│├ ArreyList (Class 数组,随机访问,没有同步,线程不安全)
│├ Vector (Class 数组 同步 线程安全)
│├ LinkedList (Class 链表 插入删除 没有同步 线程不安全 底层是由链表实现的)
│└ Stack (Class)
└+Set(接口 不能含重复的元素。仅接收一次并做内部排序,集)
│├ HashSet (Class)
│├ LinkedHashSet (Class)
│└ TreeSet (Class)
+Map(接口)
├ +Map(接口 映射集合)
│ ├ HashMap (Class 不同步,线程不安全。除了不同和允许使用null 键值之外,与Hashtable大致相同)
│ ├ Hashtable (Class 同步 ,线程安全 。不允许实施null 键值)
│ ├ +SortedMap 接口
│ │ ├ TreeMap (Class)
│ ├ WeakHashMap (Class)
ArrayList , Vector , LinkedList 是 List 的实现类
Vector是线程安全的,效率肯定没有ArrayList高了。实际中一般也不怎么用Vector,可以自己做线程同步,也可以用Collections配合ArrayList实现线程同步。
前面多次提到扩容的代价很高,所以如果能确定容量的大致范围就可以在创建实例的时候指定,注意,这个仅限于ArrayList和Vector哟:
ArrayList arrayList = new ArrayList(100);
arrayList.ensureCapacity(200);
Vector vector = new Vector(100);
vector.ensureCapacity(200);
a.排序
List的排序的话就是使用Collections的sort方法,构造Comparator或者让List中的对象实现Comparaable都可以,这里就不贴代码了。
b.去重
第一种:用Iterator遍历,遍历出来的放到一个临时List中,放之前用contains判断一下。
第二种:利用set的不可重复性,只需三步走。
//第一步:用HashSet的特性去重
HashSet tempSet = new HashSet(arrayList);
//第二步:将arrayList清除
tempSet.clear();
//第三步:将去重后的重新赋给List
arrayList.addAll(tempSet);Stack
Stack呢,是继承自Vector的,所以用法啊,线程安全什么的跟Vector都差不多,只是有几个地方需要注意:
第一:add()和push(),stack是将最后一个element作为栈顶的,所以这两个方法对stack而言是没什么区别的,但是,它们的返回值不一样,add()返回boolean,就是添加成功了没有;push()返回的是你添加的元素。为了可读性以及将它跟栈有一丢丢联系,推荐使用push。
第二:peek()和pop(),这两个方法都能得到栈顶元素,区别是peek()只是读取,对原栈没有什么影响;pop(),从字面上就能理解,出栈,所以原栈的栈顶元素就没了。
HashSet和TreeSet
Set集合类的特点就是可以去重,它们的内部实现都是基于Map的,用的是Map的key,所以知道为什么可以去重复了吧。
既然要去重,那么久需要比较,既然要比较,那么久需要了解怎么比较的,不然它将1等于2了,你怎么办?
比较是基于hascode()方法和equals()方法的,所以必要情况下需要重新这两个方法。
HashMap效率高于HashTable。
多线程环境下,通常也不是用HashTable,因为效率低。HashMap配合Collections工具类使用实现线程安全。同时还有ConcurrentHashMap可以选择,该类的线程安全是通过Lock的方式实现的,所以效率高于Hashtable。