| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 学习程序开发流程 |
| 学号 | 20188437 |
1.Gitee项目地址
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| Planning | 计划 | 15 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 15 | 10 |
| Development | 开发 | 770 | 785 |
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 120 |
| • Design Spec | • 生成设计文档 | 60 | 60 |
| • Design Review | • 设计复审 | 10 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 300 | 360 |
| • Code Review | • 代码复审 | 30 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 90 | 100 |
| • Test Repor | • 测试报告 | 30 | 60 |
| • Size Measurement | • 计算工作量 | 30 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 875 | 895 |
3.解题思路
-
需求分析
- 1.输入参数为输入文本文件路径和输出文本文件路径。
- 2.读取输入文本内容。
- 3.统计文件的字符数。
- 4.统计文件的单词总数。
- 5.统计文件的有效行数。
- 6.统计文件中各单词的出现次数。
- 7.将统计结果输出到output.txt。
-
解题思路
- 1.输入参数从主函数变量中获取。
- 2.用字节流读入文本数据转字符并设置编码格式。
- 3.直接获取字符串长度。
- 4.正则表达式匹配单词。
- 5.正则表达式匹配换行符。
- 6.用Map集合,改进4中的思路,将找到的单词放在Map中匹配,匹配失败则存储进Map中,匹配成功则相应key值+1。
- 7.用打印流输出到ouput.txt文件。
4.代码规范
5.计算模块接口的设计与实现过程
- Lib类
- countLine()
Matcher m = Pattern.compile("(^|
)\s*\S+").matcher(text);
lines = 0;
while (m.find())
{
lines ++;
}
用正则表达式:(^| )s*S+ 匹配非空白字符的行累加统计。
- countWord()
调用setWordMap(),返回记录单词数量的变量的值。 - setWordMap()
用正则表达式:(|[A-Za-z0-9])([a-zA-Z]{4}[a-zA-Z0-9]*) 匹配符合题意的单词,如果该单词不存在于Map集合内,就要保存进去并计数。 - getWordsTop10()
wordsMap =
wordsMap
.entrySet()
.stream()
.sorted(Map.Entry.<String, Integer> comparingByValue() //按值降序
.reversed()
.thenComparing(Map.Entry.comparingByKey()))//按key字典序升序
.limit(10)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e2, LinkedHashMap::new));
调用setWordMap(),对Map集合内的单词根据统计的数量进行降序排序,再对数量相同的单词进行字典序排序,用limit函数取前10个对象,最后返回Map集合。
-
countChar()
直接用text.length()得到字符串长度并返回。 -
WordCount类
- input()
FileInputStream in=new FileInputStream(file);
// size 为字串的长度 ,这里一次性读完
int size=in.available();
byte[] buffer=new byte[size];
in.read(buffer);
in.close();
this.text=new String(buffer,"UTF-8");
一次性读入,加快读取速度。
- count()
负责调用Lib类中的方法进行统计。 - output()
将统计结果输出到指定文件中。 - main()
主函数入口。
Map集合结构Map<String,Integer>

6.计算模块接口部分的性能改进
文件读取方式是影响程序速度的关键因素之一,对以下几种方式进行了测试。
测试样例:
characters: 19489429
words: 218
lines: 110406
1.按一次1024byte读
File file=new File(inputFileName);
try
{
FileInputStream inStream=new FileInputStream(file);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] buffer=new byte[1024];
int length=-1;
while( (length = inStream.read(buffer)) != -1)
{
bos.write(buffer,0,length);
}
bos.close();
inStream.close();
text=bos.toString();
}catch (Exception e) {
e.printStackTrace();
}
平均运行时间:2400ms
2.按行读
File file=new File(inputFileName);
int len=0;
StringBuffer str=new StringBuffer("");
try {
FileInputStream is=new FileInputStream(file);
InputStreamReader isr= new InputStreamReader(is);
BufferedReader in= new BufferedReader(isr);
String line=null;
while( (line=in.readLine())!=null )
{
if(len != 0) // 处理换行符的问题
{
str.append("
"+line);
}
else
{
str.append(line);
}
len++;
}
in.close();
is.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
text=str.toString();
平均运行时间:2800ms
3.缓存流
BufferedReader inputBfd = null;
try {
inputBfd = new BufferedReader(new InputStreamReader(new FileInputStream(inputFileName), "UTF-8"));
int charIndex = 0;
StringBuilder stringBuilder = new StringBuilder();
while ((charIndex = inputBfd.read()) != -1) {
stringBuilder.append((char) charIndex);
}
text = stringBuilder.toString();
}
catch (Exception e)
{
System.out.print(e.getMessage());
System.out.print("
文件读出错!");
}
finally
{
if (inputBfd != null)
inputBfd.close();
}
平均运行时间:2700ms
4.一次读完
File file=new File(inputFileName);
try {
FileInputStream in=new FileInputStream(file);
// size 为字串的长度 ,这里一次性读完
int size=in.available();
byte[] buffer=new byte[size];
in.read(buffer);
in.close();
this.text=new String(buffer,"UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
平均运行时间:2200ms
根据测试结果可知,一次读完性能最优。
7.计算模块部分单元测试展示
统计文件的字符数(对应输出第一行):
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
测试样例:

测试结果:

统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
测试样例:
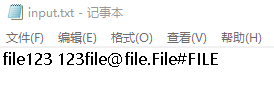
测试结果:

统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
测试样例:

测试结果:

统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
测试样例:

测试结果:

测试样例:
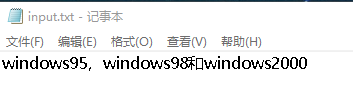
测试结果:

8.计算模块部分异常处理说明
- 读文件错误处理
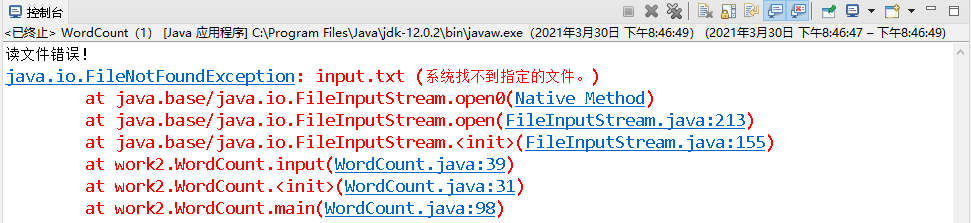
9.心路历程与收获
- 学习了git相关的知识
- 开发程序前的分析设计工作是非常重要的。
- PSP表格是一种新的接触到的开发文档。它能提高我们开发的效率。
- 了解了很多读写文件的方式,合理选择可以提高程序性能。
- 意识到了正则表达式的重要性,学到了一些正则表达式的语法。
- 先思考自己的解题思路,再去网上看看,说不定会有意想不到的技术供我使用学习。
- 要养成良好的编程习惯,规范代码。