文档结构如下:
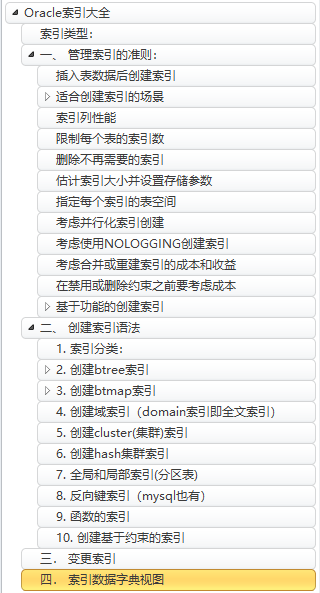
前言:
Oracle 官方文档对索引的描述真是弱透了,对索引的说明就是一坨……,support也没有很好的资料,下面还是用的官方上的内容经过自己的整理加上网上的资料;至于为什么用索引,以及索引的重要性,相信大家都知晓;如果把数据库所有的表比如成一本书,那么,索引就是书的目录,你不可能每一次查看书的内容从第一页读到最后一页,不用目录吧!!
索引类型:
索引是与表和群集关联的可选结构,可以使SQL查询对表执行得更快。正如本手册中的索引可以帮助您更快地找到信息(没有索引)一样,Oracle数据库索引提供了对表数据的更快访问路径。您可以使用索引而无需重写任何查询。结果是相同的,但是可以更快地看到它们。
Oracle数据库提供了几种索引方案,这些方案提供了互补的性能功能。这些是:
- B树索引:默认索引和最常见索引
- B树集群索引:专门为集群定义
- 哈希集群索引:专门为哈希集群定义
- 全局和局部索引:与分区表索引有关
- 反向键索引:对Oracle Real Application Clusters应用程序最有用
- 位图索引:紧凑;最适合具有少量值的列
- 基于函数的索引:包含函数/表达式的预先计算的值
- 域索引:特定于应用程序或盒带。
索引在逻辑上和物理上独立于关联表中的数据。作为独立的结构,它们需要存储空间。您可以创建或删除索引,而不会影响基表,数据库应用程序或其他索引。当您插入,更新和删除关联表的行时,数据库会自动维护索引。如果删除索引,所有应用程序将继续运行。但是,访问以前索引的数据可能会更慢。
一、 管理索引的准则:
- 插入表数据后创建索引
- 适合创建索引的场景
- 性能的订单索引列
- 限制每个表的索引数
- 删除不再需要的索引
- 估计索引大小并设置存储参数
- 指定每个索引的表空间
- 考虑并行化索引创建
- 考虑使用NOLOGGING创建索引
- 考虑合并或重建索引的成本和收益
- 在禁用或删除约束之前要考虑成本
插入表数据后创建索引
通常使用SQL * Loader或导入实用程序将数据插入或加载到表中。
适合创建索引的场景
索引适用场景:
使用以下准则确定何时创建索引:
- 如果您经常要检索大表中少于15%的行,则创建索引。根据表扫描的相对速度以及行数据相对于索引键的分布方式,百分比差异很大。表扫描越快,百分比越低;行数据越聚类,百分比越高。
- 为了提高多个表的联接性能,将索引列用于联接。
- 主键和唯一键自动具有索引。
- 小表不需要索引。如果查询花费的时间太长,则表可能已从小变大。
适用于索引的列(官方说的也不一定准确有的)
一些列很适合索引。具有以下一个或多个特征的列可作为索引的候选:
- 列中的值相对唯一。
- 值的范围很广(适用于常规索引)。
- 值的范围很小(适用于位图索引)。
- 该列包含许多空值,但查询通常选择具有值的所有行。在这种情况下,请使用以下短语:
WHERE COL_X > -9.99 * power(10,125) ;
WHERE COL_X IS NOT NULL ;
这是因为第一个使用索引作为索引COL_X(假设它COL_X是一个数字列)。
实验如下:
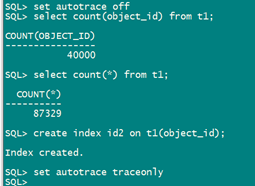
create table test as select * from dba_objects;
update test set OBJECT_ID=rownum;

update test set OBJECT_ID=null where OBJECT_ID >10000;
commit;
create index id_idx on test(OBJECT_ID) online;
begin
dbms_stats.gather_table_stats('sys','test',cascade=>true);
end;
/
set autotrace traceonly
select * from test where object_id is null;
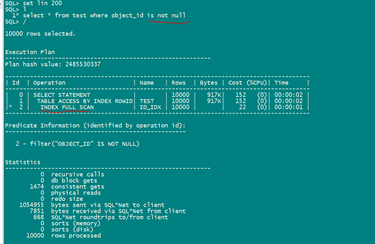
其实这个官方说的不是特别正确(IS NOT NULL这个范围还是在15%以内,所以还是走的索引)
以下是范围超过15%

begin
dbms_stats.gather_table_stats('sys','t1',cascade=>true);
end;
/
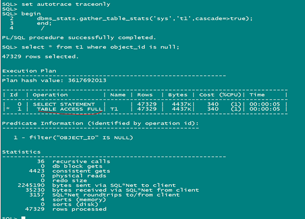
其实这个官方说的不是特别正确(IS NOT NULL这个范围还是在50%以内>15%,所以走的全表扫描)
索引列性能
CREATE INDEX语句中列的顺序可能会影响查询性能。通常,首先指定最常用的列。
如果要创建跨越,加快查询列单索引访问,例如col1,col2和col3; 然后,访问just col1或just col1和访问的查询col2也将加快。但是访问了just col2,just col3或just col2并且col3不使用索引的查询。
限制每个表的索引数
一个表可以有任意数量的索引。但是,索引越多,修改表的开销就越大。具体来说,当插入或删除行时,表上的所有索引也必须更新。此外,更新列时,必须更新包含该列的所有索引。
因此,在从表中检索数据的速度与更新表的速度之间需要权衡。例如,如果一个表主要是只读的,那么拥有更多的索引将很有用。但是如果表被大量更新,则最好使用较少的索引。
删除不再需要的索引
如果出现以下情况,请考虑删除索引:
- 它不会加快查询速度。该表可能很小,或者表中可能有很多行,但索引条目却很少。
- 您的应用程序中的查询不使用索引。
- 索引必须在重建之前被删除。
估计索引大小并设置存储参数
在创建索引之前估算索引的大小可以促进更好的磁盘空间规划和管理。您可以使用索引的组合估计大小以及表,撤消表空间和重做日志文件的估计,来确定保存目标数据库所需的磁盘空间量。根据这些估计,您可以做出正确的硬件购买和其他决策。
使用单个索引的估计大小可以更好地管理索引使用的磁盘空间。创建索引后,可以设置适当的存储参数并提高使用该索引的应用程序的I / O性能。例如,假设您在创建索引之前先估计其最大大小。如果随后在创建索引时设置存储参数,则会为表数据段分配较少的扩展区,并且所有索引数据都存储在磁盘空间的相对连续的部分中。这减少了涉及该索引的磁盘I / O操作所需的时间。
单个索引条目的最大大小约为数据块大小的一半。
可以通过以下两种方式来设置为索引创建的索引段的存储参数,该索引段用于执行主键或唯一键约束:
- 在or 语句的ENABLE... USING INDEX子句中CREATE TABLEALTER TABLE
- 在声明的STORAGE子句中ALTER INDEX
指定每个索引的表空间
可以在任何表空间中创建索引。可以在与其索引的表相同或不同的表空间中创建索引。如果为表及其索引使用相同的表空间,则执行数据库维护(如表空间或文件备份)或确保应用程序可用性会更方便。所有相关数据始终在线。
与在同一表空间中存储表和索引相比,对表及其索引使用不同的表空间(在不同的磁盘上)会产生更好的性能。减少磁盘争用。但是,如果您对一个表使用不同的表空间,并且该表的索引一个表空间处于脱机状态(包含数据或索引),则不能保证引用该表的语句可以正常工作。
考虑并行化索引创建
您可以并行化索引创建,与并行化表创建相同。因为多个进程一起创建索引,所以与单个服务器进程按顺序创建索引相比,数据库可以更快地创建索引。
并行创建索引时,每个查询服务器进程分别使用存储参数。因此,在索引创建期间,使用初始化的5M值和12的并行度创建的索引会消耗至少60M的存储空间。
考虑使用NOLOGGING创建索引
通过NOLOGGING在CREATE INDEX语句中指定,可以创建索引并生成最少的重做日志记录。
创建索引NOLOGGING具有以下好处:
- 空间保存在重做日志文件中。
- 创建索引所需的时间减少了。
- 并行创建大索引可提高性能。
通常,创建的较大索引的相对性能改进比较LOGGING小的索引要大。创建小的索引LOGGING对创建索引所花费的时间几乎没有影响。但是,对于较大的索引,性能改进可能非常显着,尤其是当您同时并行化索引创建时。
考虑合并或重建索引的成本和收益
大小不正确或增长增加会产生索引碎片。要消除或减少碎片,您可以重建或合并索引。但是在执行任何一项任务之前,请权衡每种选择的成本和收益,然后选择最适合您情况的选择。是与重建和合并索引相关的成本和收益的比较。

B树索引叶子块以供重用的情况下,可以使用以下语句合并这些叶子块:
ALTER INDEX vmoore COALESCE;

在禁用或删除约束之前要考虑成本
由于唯一键和主键具有关联的索引,因此在考虑禁用还是删除UNIQUE或PRIMARY KEY约束时,应考虑删除和创建索引的成本。如果UNIQUE键或PRIMARY KEY约束的关联索引非常大,则可以通过启用约束而不是删除并重新创建大索引来节省时间。您还可以选择在删除或禁用UNIQUE或PRIMARY KEY约束时明确指定要保留或删除索引。
基于功能的创建索引
创建一个在线索引(生产)
生产中比如说有一张大的分区表需要创建索引,要是直接执行create index 下去,估计直接就HANG住了,索引需要使用online关键字,在线创建和重建索引。可以在基础表上建立或重建索引的同时更新基础表,可以在建立索引的同时执行DML操作,但不允许DDL操作。在线创建或重建索引时,不支持并行执行。如下:
CREATE INDEX emp_name ON emp(mgr,emp1,emp2,emp3)online;
注意:
完成在线索引构建所需的时间与表的大小和并发执行的DML语句的数量成正比。因此,最好在DML活动较少时开始在线索引构建。
创建索引时收集附带统计信息(生产)
Oracle数据库为您提供了在创建或重建索引期间以极少的资源成本收集统计信息的机会。这些统计信息存储在数据字典中,供优化器在选择执行SQL语句的计划时继续使用。以下语句:
CREATE INDEX hr.last_name_idx ON hr.employees(LAST_NAME) ONLINE
COMPUTE STATISTICS;
大表的时候可以执行在线创建并收集统计信息
创建一个键压缩索引
使用键压缩创建索引使您可以消除重复出现的键列前缀值。
键压缩将索引键分为前缀和后缀条目。通过在索引块的所有后缀条目之间共享前缀条目来实现压缩。这种共享可以节省大量空间,使您可以为每个索引块存储更多键,同时提高性能。
密钥压缩在以下情况下很有用:
- 您具有一个非唯一索引,ROWID该索引后面附加了唯一索引。如果您在此处使用键压缩,则重复的键将作为前缀条目存储在索引块中,而不包含ROWID。其余的行成为仅包含的后缀条目ROWID。
- 您有一个唯一的多列索引。
您可以使用COMPRESS子句启用密钥压缩。还可以指定前缀长度(作为键列的数量),以标识如何将键列分为前缀和后缀条目。例如,以下语句压缩索引叶子块中重复出现的键:
CREATE INDEX emp_ename ON emp(ename)
TABLESPACE users
COMPRESS 1;
解压:
ALTER INDEX emp_ename REBUILD NOCOMPRESS;
创建不可见索引
从版本11 g开始,可以创建不可见索引。一个无形的指数是由优化忽略,除非你明确地设定一个指标OPTIMIZER_USE_INVISIBLE_INDEXES初始化参数TRUE在会话或系统级。使索引不可见是使其无法使用或删除它的替代方法。使用不可见索引,您可以执行以下操作:
- 在删除索引之前,请测试删除索引。
- 对应用程序的某些操作或模块使用临时索引结构,而不会影响整个应用程序。
与不可用的索引不同,在DML语句期间维护不可见的索引。
要创建不可见索引,请CREATE INDEX在INVISIBLE子句中使用SQL语句。以下语句创建一个以表emp_ename的ename列命名的不可见索引emp:
CREATE INDEX emp_ename ON emp(ename)
TABLESPACE users
STORAGE (INITIAL 20K
NEXT 20k
PCTINCREASE 75)
INVISIBLE;
二、 创建索引语法
1. 索引分类:
Oracle数据库提供了几种索引方案,这些方案提供了互补的性能功能。这些是:
- B树索引:默认索引和最常见索引
- B树集群索引:专门为集群定义
- 哈希集群索引:专门为哈希集群定义
- 全局和局部索引:与分区表和索引有关
- 反向键索引:对Oracle Real Application Clusters应用程序最有用
- 位图索引:紧凑;最适合具有少量值的列
- 基于函数的索引:包含函数/表达式的预先计算的值
- 域索引:特定于应用程序或盒带。
以下是网络上找到的相关分类
逻辑上:
Single column 单行索引
Concatenated 多行索引
Unique 唯一索引
NonUnique 非唯一索引
Function-based函数索引
Domain 域索引
物理上:
Partitioned 分区索引
NonPartitioned 非分区索引
B-tree
Normal 正常型B树
Rever Key 反转型B树
Bitmap 位图索引
全文索引
本节介绍如何创建索引。要在您自己的架构中创建索引,必须至少满足以下条件之一:
- 要建立索引的表或集群在您自己的模式中。
- 您INDEX对要编制索引的表具有特权。
- 您具有CREATE ANY INDEX系统特权。
要在另一个架构中创建索引,必须满足以下所有条件:
- 您具有CREATE ANY INDEX系统特权。
- 其他模式的所有者对表空间有一个配额,以包含索引或索引分区或UNLIMITED TABLESPACE系统特权。
2. 创建btree索引
语法如下:
create table table_index as select * from dba_objects;
UPDATE table_index SET object_id=ROWNUM;
下面是创建bitree索引
create index OBJECT_ID_idx on table_index(OBJECT_ID);
btree应用场景:
非常适合数据重复率低的字段,例如ID等唯一性约束这种字段。
3. 创建btmap索引
create bitmap index OBJECT_TYPE_idx on table_index(OBJECT_TYPE);
bitmap应用场景:
重复率很高的键值;位图索引由于只存储键值的起止Rowid和位图,占用的空间非常少,且在bitmap index中一个dml操作,影响的是一个位图段(同一键值)。严重影响频繁的DML(极其容易造成会话hang住),造成死锁。
限制位 图索引受到以下限制:
BITMAP创建全局分区索引时无法指定。- 您不能在索引组织的表上创建位图二级索引,除非索引组织的表具有与其关联的映射表。
- 您不能同时指定
UNIQUE和BITMAP。 - 您无法指定
BITMAP域索引。 - 一个位图索引最多可以包含30列。
4. 创建域索引(domain索引即全文索引)
要在自己的架构中创建域索引,除了创建常规索引的先决条件外,您还必须对索引类型具有EXECUTE对象特权。如果要在另一个用户的架构中创建域索引,则索引所有者还必须对索引EXECUTE类型及其基础实现类型具有对象特权。在创建域索引之前,应首先定义索引类型。
b-tree,bitmap无法发挥作用的场景,like '%string%'模糊匹配;占用过大的磁盘空间(全文索引大约是原表的1.5倍,重建成本很高)、维护成本高。
Oracle10g 里面支持四种类型的索引:
context、ctxcat、ctxrule、ctxxpath

以下只用context索引。
CREATE INDEX text_idx ON table_index(object_name) indextype is ctxsys.context;

SELECT * FROM TABLE_INDEX WHERE contains(OBJECT_NAME,'ACCOUNT') >1;
查看执行计划:

查看执行计划,走的是domian全文索引,如果是其它用户,在建立文本索引的时候,需要授权(详细步骤不演练了)。
5. 创建cluster(集群)索引
创建语法如下:
一下是例子:
由于这个不是普通便(堆表),我们一般使用的普通便是堆表,而集群索引是基于cluster表的创建cluster语句:
创建集群:
示例创建cluster
下面的语句创建一个以personnelcluster key column 命名的集群department,512字节的集群大小和存储参数值:
CREATE CLUSTER personnel
(department NUMBER(4)) SIZE 512 STORAGE (initial 100K next 50K);
示例创建cluster index在cluster key上
CREATE INDEX idx_personnel ON CLUSTER personnel;
将表添加到集群:
CREATE TABLE dept_10
CLUSTER personnel (department_id)
AS SELECT * FROM hr.employees WHERE department_id = 10;
CREATE TABLE dept_20
CLUSTER personnel (department_id)
AS SELECT * FROM hr.employees WHERE department_id = 20;
要说cluster使用环境,只能是cluster 表,以下是什么环境使用cluster表:
如果一组表有一些共同的列,则将这样一组表存储在相同的数据库块中;聚簇还表示把相关的数据存储在同一个块上。利用聚簇,一个块可能包含多个表的数据。概念上就是如果两个或多个表经常做连接操作,那么可以把需要的数据预先存储在一起。聚簇还可以用于单个表,可以按某个列将数据分组存储。
什么时候不应该使用聚簇:
1) 如果预料到聚簇中的表会大量修改:必须知道,索引聚簇会对DML的性能产生某种负面影响(特别是INSERT语句)。管理聚簇中的数据需要做更多的工作。
2) 如果需要对聚簇中的表执行全表扫描:不只是必须对你的表中的数据执行全面扫描,还必须对(可能的)多个表中的数据进行全面扫描。由于需要扫描更多的数据,所以全表扫描耗时更久。
3) 如果你认为需要频繁地TRUNCATE和加载表:聚簇中的表不能截除。这是显然的,因为聚簇在一个块上存储了多个表,必须删除聚簇表中的行。
因此,如果数据主要用于读(这并不表示“从来不写”;聚簇表完全可以修改),而且要通过索引来读(可以是聚簇键索引,也可以是聚簇表上的其他索引),另外会频繁地把这些信息联结在一起,此时聚簇就很适合。
6. 创建hash集群索引
跟5比较类似:
CREATE CLUSTER language (cust_language VARCHAR2(3))
SIZE 512 HASHKEYS 10
STORAGE (INITIAL 100k next 50k);
CREATE CLUSTER address
(postal_code NUMBER, country_id CHAR(2))
HASHKEYS 20
HASH IS MOD(postal_code + country_id, 101);
单个hash案例:
CREATE CLUSTER cust_orders (customer_id NUMBER(6))
SIZE 512 SINGLE TABLE HASHKEYS 100;
7. 全局和局部索引(分区表)
这个应该用过oracle 分区表的都知道把,我的专门说明全局索引和本地索引的博客地址:
https://www.cnblogs.com/hmwh/p/11964022.html(主要是组合索引)
8. 反向键索引(mysql也有)
1.反向索引应用场合
1)发现索引叶块成为热点块时使用
通常,使用数据时(常见于批量插入操作)都比较集中在一个连续的数据范围内,那么在使用正常的索引时就很容易发生索引叶子块过热的现象,严重时将会导致系统性能下降。
2)在RAC环境中使用
当RAC环境中几个节点访问数据的特点是集中和密集,索引热点块发生的几率就会很高。如果系统对范围检索要求不是很高的情况下可以考虑使用反向索引技术来提高系统的性能。因此该技术多见于RAC环境,它可以显著的降低索引块的争用。
2.使用反向索引的优点
最大的优点莫过于降低索引叶子块的争用,减少热点块,提高系统性能。
3.使用反向索引的缺点
由于反向索引结构自身的特点,如果系统中经常使用范围扫描进行读取数据的话(例如在where子句中使用“between and”语句或比较运算符“>”“<”等),那么反向索引将不适用,因为此时会出现大量的全表扫描的现象,反而会降低系统的性能。
create index on <TABLE_NAME> (<COLUMN_NAME>, <COLUMN_NAME>)
REVERSE
create index emp_reverse_idx on scott.EMP (mgr) REVERSE;
SELECT * FROM scott.EMP WHERE mgr =7902;

SELECT * FROM scott.EMP WHERE mgr > 7902;
当执行范围查询的时候,走的是全表扫描。
9. 函数的索引
基于函数的索引有助于查询限定函数或表达式返回的值的查询。函数或表达式的值已预先计算并存储在索引中。
除了创建常规索引的前提条件之外,如果索引基于用户定义的函数,则必须标记这些函数。另外,如果基于函数的索引由另一个用户拥有,则仅具有对这些用户定义函数使用的对象特权。
此外,要使用基于函数的索引:
- 创建索引后必须分析该表。
- 必须确保查询不需要NULL来自索引表达式的任何值,因为NULL值未存储在索引中。
索引标记为无效,必须使用该ANALYZE INDEX...VALIDATE STRUCTURE语句来验证此索引。
比如:
CREATE INDEX EMP_SUM_IDX ON hr.EMPLOYEES (SUBSTR(PHONE_NUMBER, 0, 3));
ANALYZE INDEX EMP_SUM_IDX VALIDATE STRUCTURE; --查看索引是否有效
SELECT * FROM user_indexes WHERE index_name='EMP_SUM_IDX';
SELECT t.FIRST_NAME,SUBSTR(PHONE_NUMBER, 1, 3) FROM hr.EMPLOYEES t WHERE t.FIRST_NAME='Susan';
10. 创建基于约束的索引
单独创建一个唯一索引:
CREATE UNIQUE INDEX dept_unique_index ON dept (dname)
TABLESPACE indx;
创建基于唯一约束的索引:
以下案例为1,2,3:
CREATE TABLE a (
a1 INT PRIMARY KEY USING INDEX (create index ai on a (a1)));
CREATE TABLE b(
b1 INT,
b2 INT,
CONSTRAINT bu1 UNIQUE (b1, b2)
USING INDEX (create unique index bi on b(b1, b2)),
CONSTRAINT bu2 UNIQUE (b2, b1) USING INDEX bi);
CREATE TABLE c(c1 INT, c2 INT);
CREATE INDEX ci ON c (c1, c2);
ALTER TABLE c ADD CONSTRAINT cpk PRIMARY KEY (c1) USING INDEX ci;
三. 变更索引
索引变更包括以下:
要更改索引,您的架构必须包含索引,或者您必须具有ALTER ANY INDEX系统特权。使用该ALTER INDEX语句,您可以:
- 重建或合并现有索引
- 释放未使用的空间或分配新的扩展区
- 指定并行执行(或不指定)并更改并行度
- 更改存储参数或物理属性
- 指定
LOGGING或NOLOGGING - 启用或禁用按键压缩
- 将索引标记为不可用
- 使索引不可见
- 重命名索引
- 开始或停止监视索引使用情况
其它的应该比较常见,不常见的是最后一个,开启或者停止监视索引使用情况。
ALTER INDEX index MONITORING USAGE;
比如:
ALTER INDEX hr.EMP_DEPARTMENT_IX MONITORING USAGE;
select * from V$OBJECT_USAGE;
ALTER INDEX index NOMONITORING USAGE;
ALTER INDEX hr.EMP_DEPARTMENT_IX NOMONITORING USAGE;
select * from V$OBJECT_USAGE;
可以在视图中查询正在监视的索引,以查看是否已使用该索引。该视图包含一列,其值是或,取决于在监视的时间段内是否已使用索引。该视图还包含监视周期的开始和停止时间,
每次指定MONITORING USAGE,V$OBJECT_USAGE都会为指定的索引重置视图。先前的使用信息将被清除或重置,并记录新的开始时间。当您指定时NOMONITORING USAGE,将不执行进一步的监视,并且将记录监视时间的结束时间。在ALTER INDEX...MONITORING USAGE发出下一条语句之前,视图信息将保持不变。
四. 索引数据字典视图
没有设计到分区表的相关索引
|
视图 |
注释 |
|
DBA_INDEXES ALL_INDEXES USER_INDEXES |
|
|
DBA_IND_COLUMNS ALL_IND_COLUMNS USER_IND_COLUMNS |
这些视图描述了表上的索引列。这些视图中的某些列包含由 |
|
DBA_IND_EXPRESSIONS ALL_IND_EXPRESSIONS USER_IND_EXPRESSIONS |
这些视图描述了表上基于函数的索引的表达式。 |
|
DBA_IND_STATISTICS ALL_IND_STATISTICS USER_IND_STATISTICS |
这些视图包含索引的优化器统计信息。 |
|
INDEX_STATS |
存储来自最后一条ANALYZE INDEX...VALIDATE STRUCTURE语句的信息。 |
|
INDEX_HISTOGRAM |
存储来自最后一条 |
|
V$OBJECT_USAGE |
包含该 |
资料来自官方:
https://docs.oracle.com/cd/B28359_01/server.111/b28310/indexes001.htm#ADMIN11709
https://docs.oracle.com/database/121/SQLRF/statements_5013.htm#SQLRF01209
五. 生产中的索引处理
这个是我这段时间补写的,适当的说一下,很多面试中的问题或者生产会遇到的坑,比如说什么时候分区表什么时候使用全局索引,什么时候使用本地索引,以及大表怎么创建索引,以及分区表的分区进行truncate,drop,spit等操作时,全局索引失效怎么处理保证不影响业务性能!
1.大表建索引
建索引是一个表锁的过程,如果该表是频繁dml操作,建议 create index index_name on table_name online; 操作不影响update等操作
2.分区表什么时候用全局索引,什么时候用本地索引
其实很多网上的说的不太好,一来就是执行计划,什么逻辑读一致性获取等;
这个先是要基于业务需求,比如说我要再一张大的分区表查询用户名,但是不知道该用户创建的时间,显然是全表找用户名,这样分区表的分区段本地索引就不适用了(分区范围扫描用不到,全表扫),这种只能用全局索引;
如果我需要查询这两天某个值多少,即在某段时间内查找分区范围扫描,能够用上这段分区时间的本地建的索引段,这种适合本地索引,即分区的范围了在利用本地索引,如果这种用全局索引,时间分区就没有任何意义,全表索引快速扫描,性能大大折扣。
3.分区表drop/truncate/spit等操作,全局索引失效怎么办?
生产上24*7全局索引失效会引起业务报错甚至是hang住。
在我另外一篇博客也提到,自动更新索引(尤其是全局索引)
即 alter table table_name drop/truncate/spit partition/subpartiton (partition/subpartition)_name update (global) indexes;
他是直接在基表操作,不影响DML以及全局索引状态。