背景:搭建了一套oracle 19c主备库(单实例非CDB,PDB),linux7.5在断电后(没有进行数据库关闭)重启数据库报错如下图,redo当前状态下进行不完全恢复主库后resetlogs 打开主库报错继续报错ORA-00600: internal error code, arguments: [4193], [227], [240],
这个相当于两个问题了,先是恢复主库,再解决ORA-00600: [4193]的问题。这种问题我不止遇见过一次了,多次的,断电后启动实例会报错。处理如下:
报错提示:
ORA-00742: Log read detects lost write in thread 1 sequence 52 block 398212
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/ORCL/redo03.log'
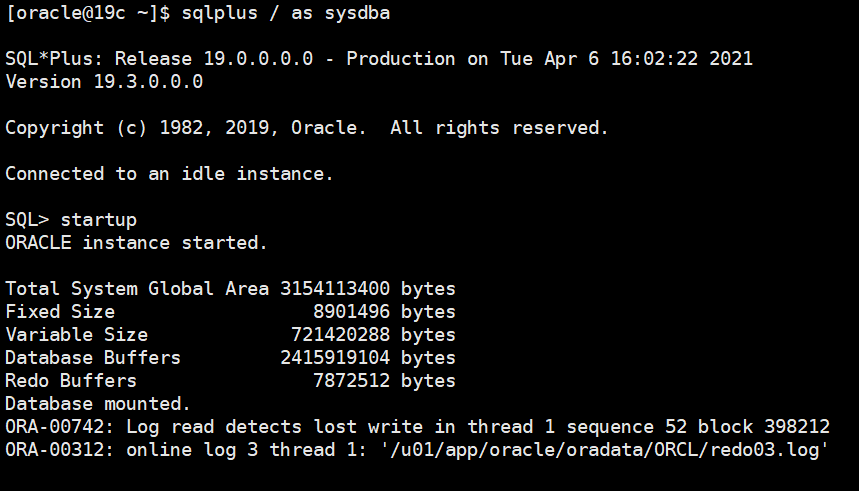
一.故障处理
1.1 current redo不完全恢复
查看redo情况:
set lin 200 pages 100
col MEMBER for a50
SELECT thread#,
a.sequence#,
a.group#,
TO_CHAR(first_change#, '9999999999999999') "SCN",
a.status,
MEMBER
FROM v$log a, v$logfile b
WHERE a.group# = B.GROUP#
ORDER BY a.sequence# DESC;
select * from v$log;

可以发现损坏的redo是第3组.
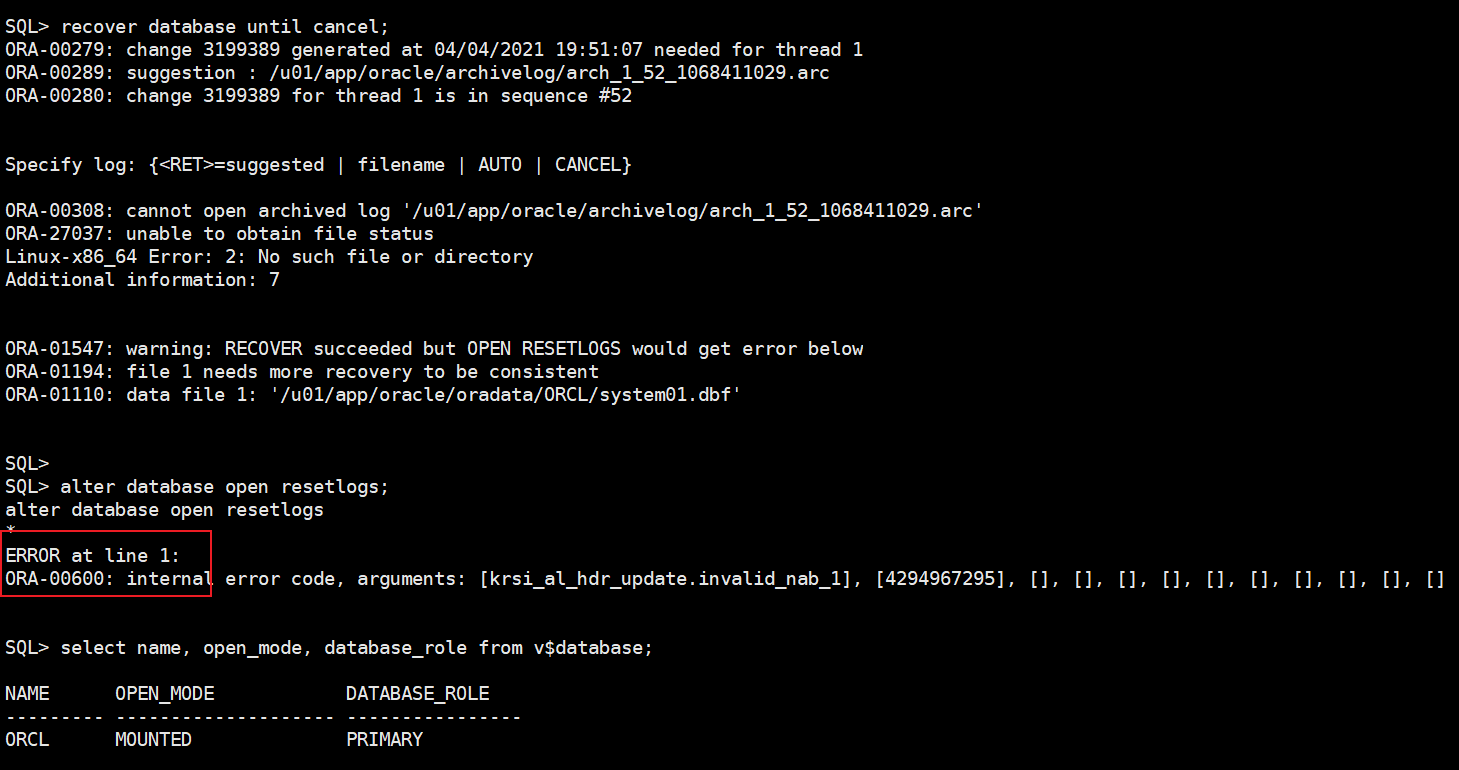
进行恢复:
recover database until cancel;
alter database open resetlogs;
select name, open_mode, database_role from v$database;
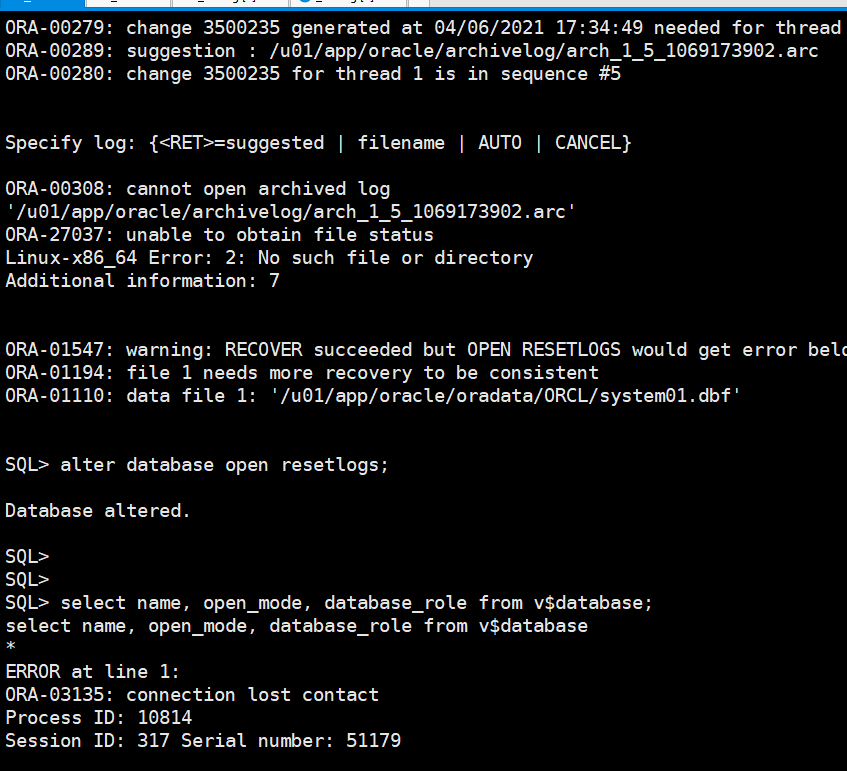
alter system set "_allow_resetlogs_corruption"=true scope=spfile;
shutdown immediate;
startup mount;
recover database until cancel;
alter database open resetlogs;
select name, open_mode, database_role from v$database;
通过恢复之后,进行resetlogs打开数据库报错:ORA-00600: internal error code, arguments: [krsi_al_hdr_update.invalid_nab_1], [4294967295], [], [], [], [], [], [], [], [], [], []
尝试过了,_allow_resetlogs_corruption方式打开,_allow_resetlogs_corruption = true是不受支持的参数,此参数导致数据和字典不一致,会造成数据的丢失。因此,这种情况下Oracle建议通过EXP方式导出数据库。重建新数据库后,再导入。
redo 的损坏,一般还容易伴随以下2种错误:ORA-600[2662](SCN有关)和 ORA-600[4000](回滚段有关)。
ORACLE 推荐的如下:
*注意:打开数据库后,必须导出重建数据库并导入。
*通过以这种方式强制打开数据库,有一个强大的功能*
*逻辑损坏的可能性,可能会影响数据字典。Oracle不保证所有数据都是可访问的,也不保证该方法已经打开了一个数据库, 并且该数据库用户将被允许继续工作。
所有这一切都提供了一种获取数据库内容以进行提取的方法,通常通过导出来进行提取。取决于确定丢失的数据量并纠正任何逻辑损坏问题。
1.2 ORA-00600: [4193] 处理
报警日志报错如下:
Block recovery completed at rba 4.147.16, scn 0x000000000033e225
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_j001_9677.trc (incident=113465):
ORA-00600: internal error code, arguments: [4194], [16], [29], [], [], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_113465/orcl_j001_9677_i113465.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
2021-04-06T17:33:42.003838+08:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_j003_9681.trc:
ORA-00600: internal error code, arguments: [4193], [203], [231], [], [], [], [], [], [], [], [], []
2021-04-06T17:33:42.004342+08:00
opidrv aborting process J003 ospid (9681) as a result of ORA-600
2021-04-06T17:33:42.257529+08:00
*****************************************************************
An internal routine has requested a dump of selected redo.
This usually happens following a specific internal error, when
analysis of the redo logs will help Oracle Support with the
diagnosis.
It is recommended that you retain all the redo logs generated (by
all the instances) during the past 12 hours, in case additional
redo dumps are required to help with the diagnosis.
*****************************************************************
2021-04-06T17:33:42.287915+08:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_j005_9685.trc:
ORA-00600: internal error code, arguments: [4193], [227], [240], [], [], [], [], [], [], [], [], []
ORA-00600: internal error code, arguments: [4193], [227], [240], [], [], [], [], [], [], [], [], []
2021-04-06T17:33:42.541633+08:00
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
2021-04-06T17:33:42.541798+08:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_j001_9677.trc:
ORA-00600: internal error code, arguments: [4194], [16], [29], [], [], [], [], [], [], [], [], []
2021-04-06T17:33:42.542337+08:00
opidrv aborting process J001 ospid (9677) as a result of ORA-600
2021-04-06T17:33:42.923918+08:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_j005_9685.trc (incident=115261):
ORA-00603: ORACLE server session terminated by fatal error
ORA-00600: internal error code, arguments: [4193], [227], [240], [], [], [], [], [], [], [], [], []
ORA-00600: internal error code, arguments: [4193], [227], [240], [], [], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_115261/orcl_j005_9685_i115261.trc
2021-04-06T17:33:42.924883+08:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_115261/orcl_j005_9685_i115261.trc:
ORA-00603: ORACLE server session terminated by fatal error
ORA-00600: internal error code, arguments: [4193], [227], [240], [], [], [], [], [], [], [], [], []
ORA-00600: internal error code, arguments: [4193], [227], [240], [], [], [], [], [], [], [], [], []
2021-04-06T17:33:42.981805+08:00
经过以上操作,设置了隐含参数_allow_resetlogs_corruption = true,很遗憾,我的数据库开启一会儿之后还是强制关闭了。
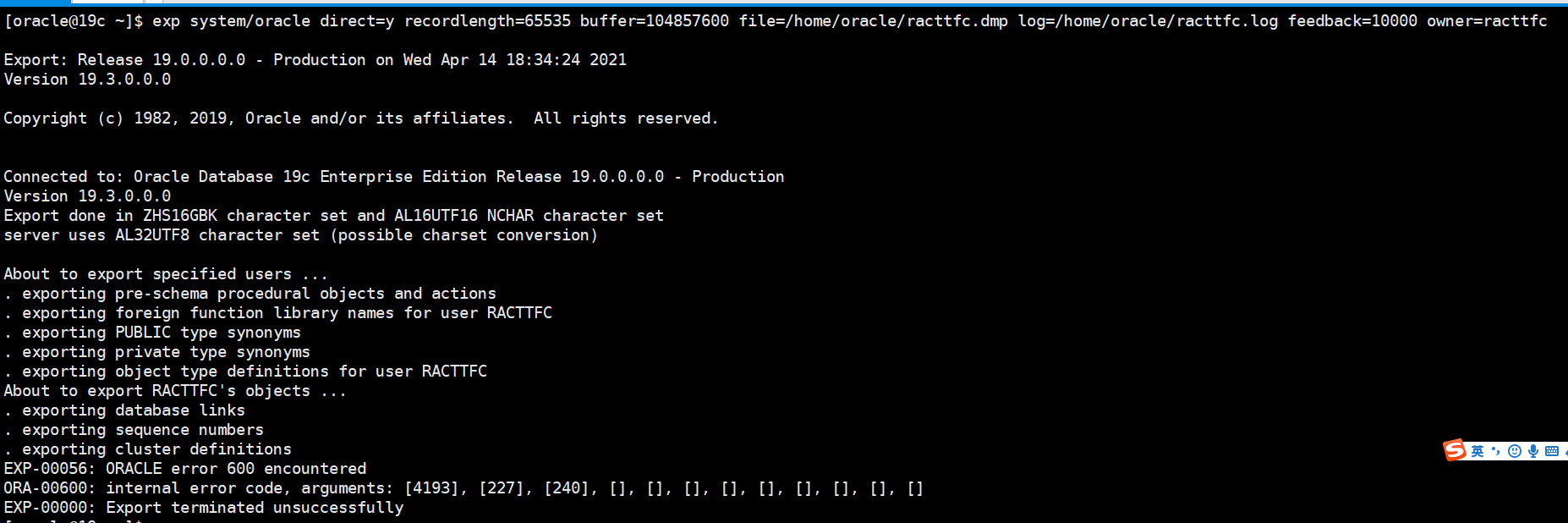
用导出方式也是行,这时需要看报错:

/u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_diag_3964.trc
oracle support 文档 1428786.1
https://support.oracle.com/epmos/faces/SearchDocDisplay?_adf.ctrl-state=cld99whp9_53&_afrLoop=278414555589218#SYMPTOM
引起的原因
收缩后可能会导致撤消损坏。相同的撤消块可能用于两个不同的事务,从而导致多个内部错误,例如:
ORA-600 [4193] / ORA-600 [4194]用于新事务
ORA-600 [4137]用于事务回滚
官方的解决文档步骤如下:
Best practice to create a new undo tablespace.
This method includes segment check.
1. Create pfile from spfile to edit
SQL> Create pfile='/tmp/initsid.ora' from spfile;
2. Shutdown the instance
3. set the following parameters in the pfile /tmp/initsid.ora
undo_management = manual
event = '10513 trace name context forever, level 2'
4. SQL>>startup restrict pfile='/tmp/initsid.ora'
5. SQL>select tablespace_name, status, segment_name from dba_rollback_segs where status != 'OFFLINE';
This is critical - we are looking for all undo segments to be offline - System will always be online.
If any are 'PARTLY AVAILABLE' or 'NEEDS RECOVERY' - Please open an issue with Oracle Support or update the current SR. There are many options from this moment and Oracle Support Analyst can offer different solutions for the bad undo segments.
If all offline then continue to the next step
6. Create new undo tablespace - example
SQL>create undo tablespace <new undo tablespace> datafile <datafile> size 2000M;
7. Drop old undo tablespace
SQL>drop tablespace <old undo tablespace> including contents and datafiles;
8. SQL>shutdown immediate;
9 SQL>startup nomount; --> Using your Original spfile
10. Modify the spfile with the new undo tablespace name
SQL> Alter system set undo_tablespace = '<new tablespace created in step 6>' scope=spfile;
11. SQL>shutdown immediate;
12. SQL>startup; --> Using spfile
处理:
cd $ORACLE_HOME/dbs
strings spfileorcl.ora
新建一个pfile
vi new.ora
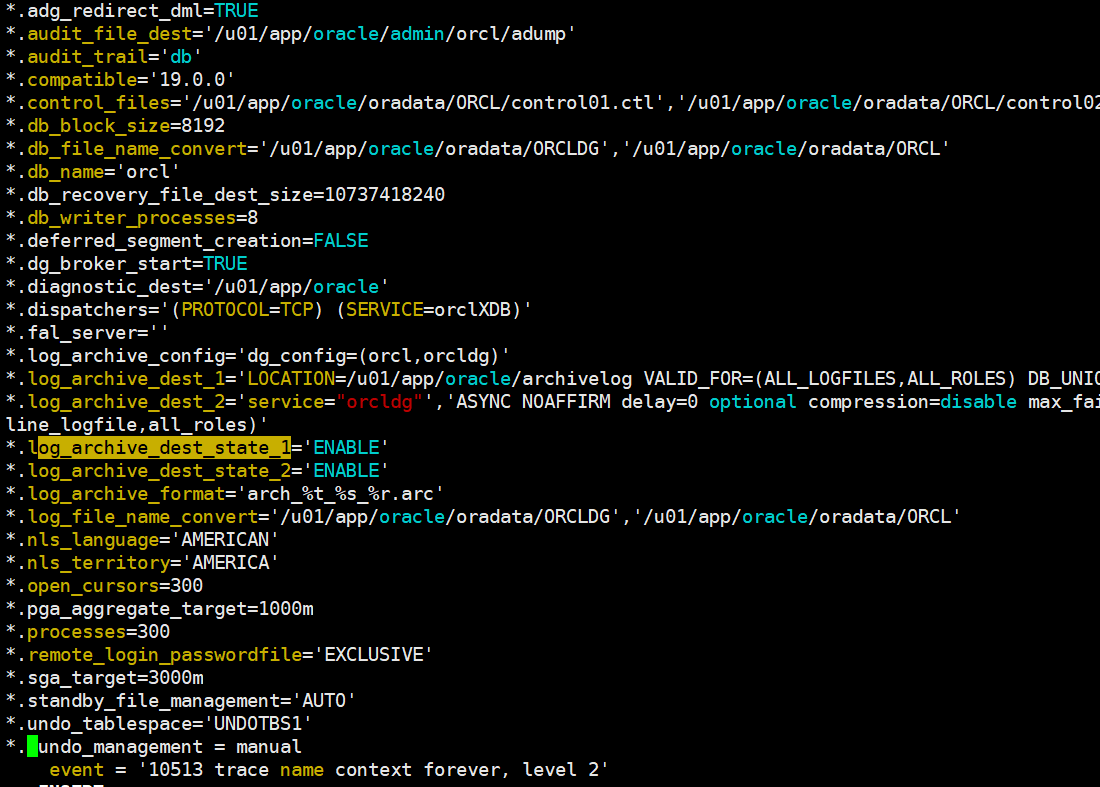
把下面这句话加入新的new.ora里头。
undo_management = manual event = '10513 trace name context forever, level 2'
利用新的参数文件启动数据库:
startup restrict pfile='/home/oracle/new.ora';
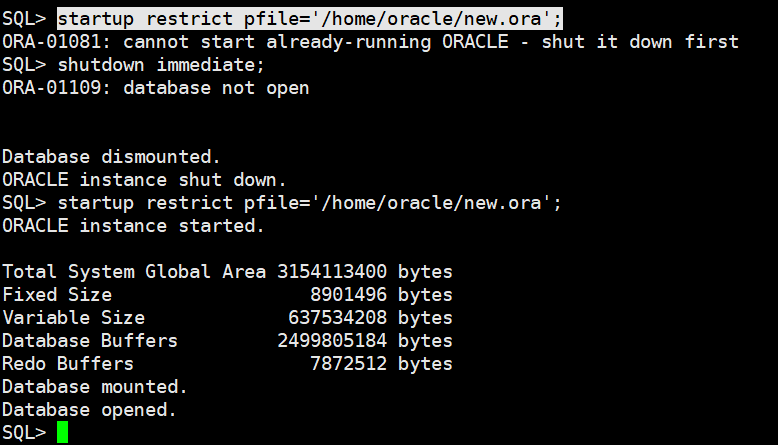
起来了:
select tablespace_name, status, segment_name from dba_rollback_segs where status != 'OFFLINE';

除了SYSTEM表空间,其他所有的表空间都是offline;
create undo tablespace undo_new datafile '/u01/app/oracle/oradata/ORCL/undo_new.dbf' size 256m;
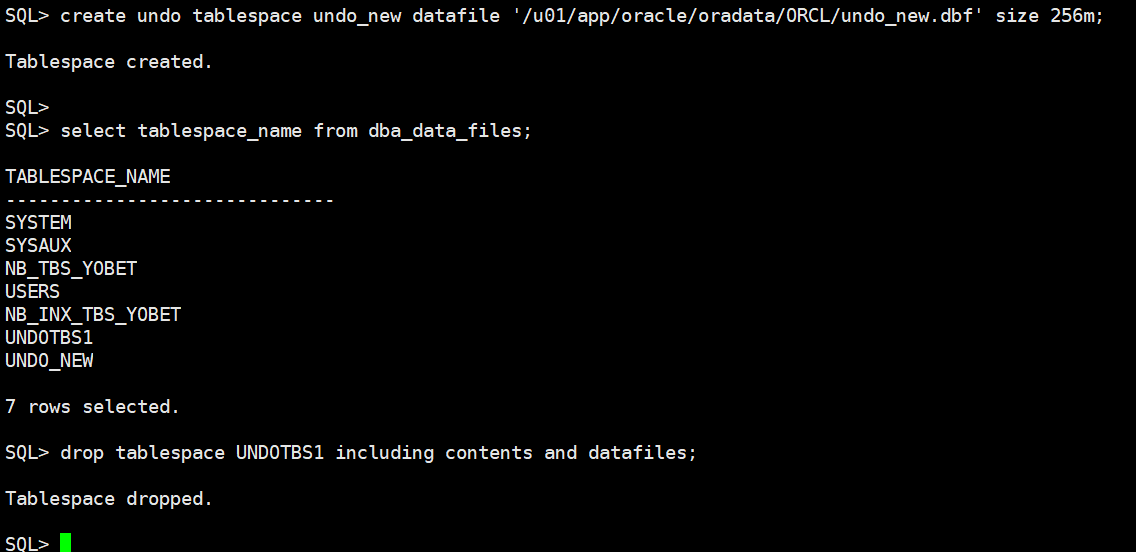
drop tablespace UNDOTBS1 including contents and datafiles;
alter system set undo_tablespace='undo_new' scope=spfile;
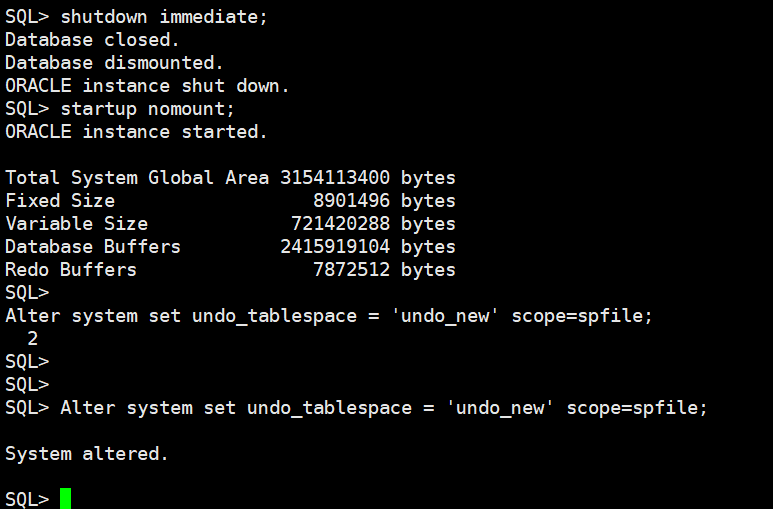
启动数据库:
startup
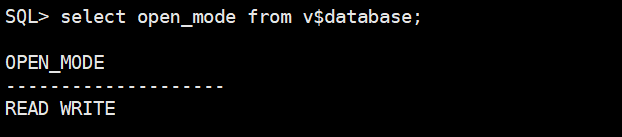
启动后数据库可以进行正常的读写和测试。
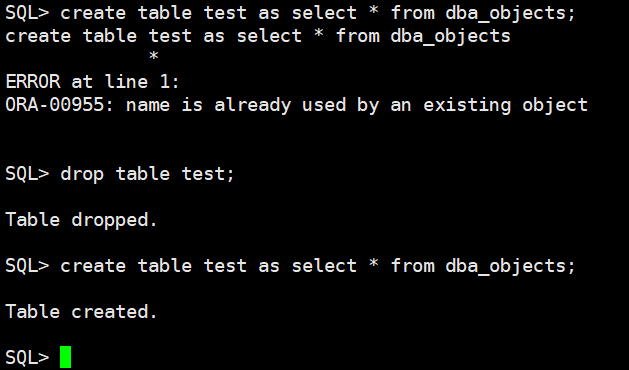
如果对这么修改的数据库不放心,可以导出后新建一个库,然后倒入进去。
二.问题分析
详细处理方式参考资料:https://www.modb.pro/db/29145
看下面trace 文件信息:
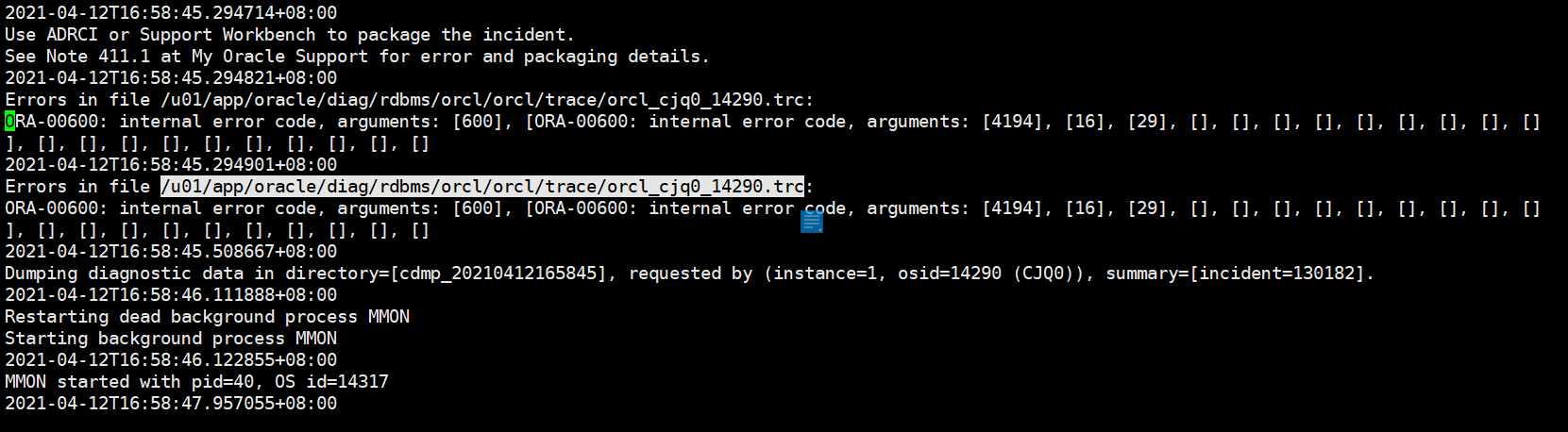
more /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_cjq0_14290.trc
ORA-00600: internal error code, arguments: [4194], [16], [29], [], [], [], [], [], [], [], [], []
Error 600 in redo application callback
Before image SCN: 0x000000000030ff74 SEQ: 0x02Dump of change vector:
CON_ID:0 TYP:0 CLS:28 AFN:4 DBA:0x0100030e OBJ:4294967295 SCN:0x000000000030ff74 SEQ:2 OP:5.1 ENC:0 RBL:0 FLG:0x0000
ktudb redo: siz: 136 spc: 4702 flg: 0x0012 seq: 0x0104 rec: 0x1d
xid: 0x0006.00a.00000517
ktubl redo: slt: 10 wrp: 1 flg: 0x0c08 prev dba: 0x00000000 rci: 0 opc: 11.1 [objn: 8842 objd: 8842 tsn: 1]
[Undo type ] Regular undo [User undo done ] No [Last buffer split] No
[Temp object] No [Tablespace Undo ] No [User only ] No
Begin trans
prev ctl uba: 0x0100030e.0104.15 prev ctl max cmt scn: 0x000000000030dc16
prev tx cmt scn: 0x000000000030dc38
txn start scn: 0xffffffffffffffff logon user: 0
prev brb: 0x0100030d prev bcl: 0x00000000
BuExt idx: 0 flg2: 0
KDO undo record:
KTB Redo
op: 0x04 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: L itl: xid: 0x000a.006.000004b1 uba: 0x0100011f.00bc.07
flg: C--- lkc: 0 scn: 0x00000000003a520e
KDO Op code: DRP row dependencies Disabled
xtype: XA flags: 0x00000000 bdba: 0x00c12665 hdba: 0x00c01262
itli: 2 ispac: 0 maxfr: 4858
tabn: 0 slot: 15(0xf)
Block after image is:
buffer rdba: 0x0100030e
scn: 0x30ff74 seq: 0x02 flg: 0x04 tail: 0xff740202
frmt: 0x02 chkval: 0x7dcf type: 0x02=KTU UNDO BLOCK
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x00000001121DA000 to 0x00000001121DC000
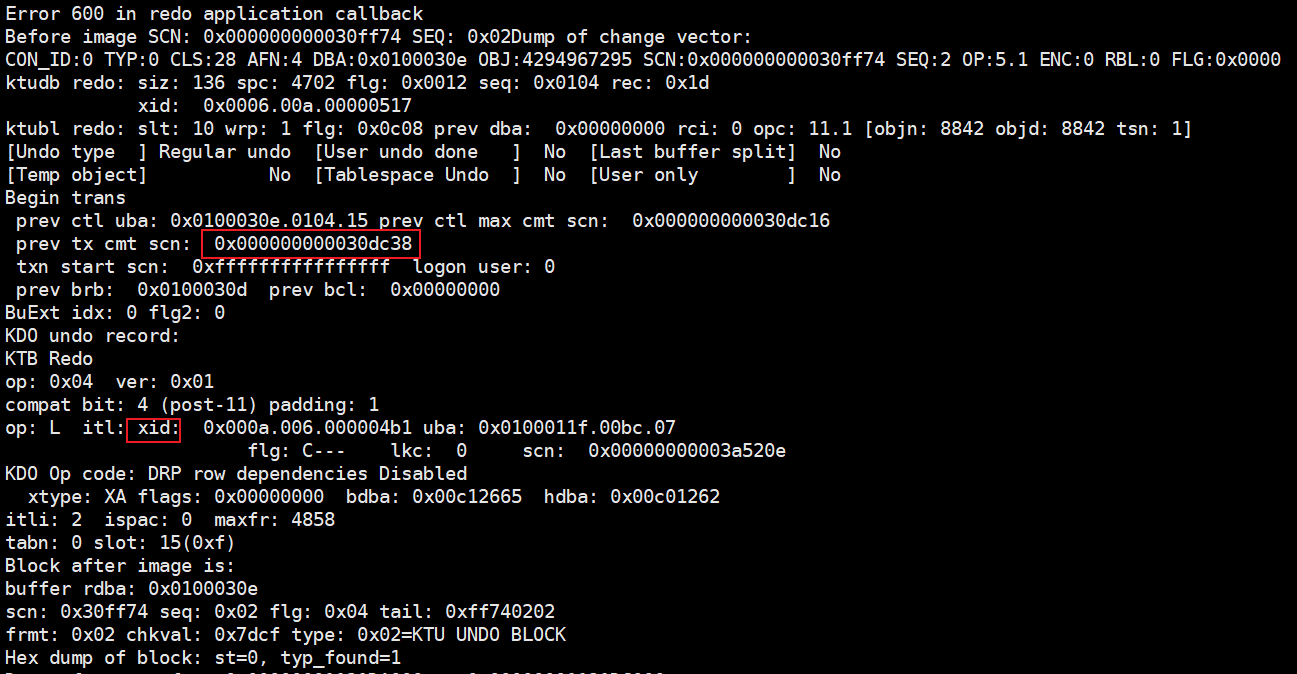
说明:
红色标记的XID,表示当前undo block所记录的事务xid,对应V$TRANSACTION.中的XID信息。
xid: 0x000a.006.000004b1
0x000a--回滚段编号,16进制的,说明该事务使用的回滚段是第10号回滚段
006--事务槽编号(slot),说明对应undo segment header中的transaction table记录中的index是6
000004b1 --序号(同一个事务可能具有多个SCN,用于区分一个事务中的多个操作)

Doing block recovery for file 4 block 782
Resuming block recovery (PMON) for file 4 block 782
Block recovery from logseq 4, block 95 to scn 0x0000000000000000
2021-04-12T16:58:44.619643+08:00
Recovery of Online Redo Log: Thread 1 Group 1 Seq 4 Reading mem 0
Mem# 0: /u01/app/oracle/oradata/ORCL/redo01.log
Block recovery completed at rba 0.0.0, scn 0x00000000003a51ae
Doing block recovery for file 4 block 208
Resuming block recovery (PMON) for file 4 block 208
Block recovery from logseq 4, block 95 to scn 0x00000000003a5213
2021-04-12T16:58:44.621585+08:00
Recovery of Online Redo Log: Thread 1 Group 1 Seq 4 Reading mem 0
Mem# 0: /u01/app/oracle/oradata/ORCL/redo01.log
Block recovery completed at rba 4.97.16, scn 0x00000000003a5214
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_cjq0_14290.trc (incident=130183):
ORA-00600: internal error code, arguments: [600], [ORA-00600: internal error code, arguments: [4194], [16], [29], [], [], [], [], [], [], [], [], []
], [], [], [], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_130183/orcl_cjq0_14290_i130183.trc
2021-04-12T16:58:44.950687+08:00
相当于恢复Doing block recovery for file 4 block 782,这里数据尝试去恢复这个块,这个块是undo数据
文件的块。