文档操作依据来自官方网址:https://docs.oracle.com/cd/E11882_01/server.112/e41134/scenarios.htm#SBYDB4888
闪回FAILOVER失败的物理备库的前提:
1、物理备库FAILOVER前设置db_recovery_file_dest_size足够大
2、物理备库AILOVER前设置db_recovery_file_dest路径
3、开启物理备库闪回数据库(创建一致性还原点和开启闪回数据库都可以,但是开启闪回数据库闪回空间不够的话,日志会覆盖,所以db_recovery_file_dest_size足够大)
The following steps assume that a failover has been performed to a physical standby database and that Flashback Database was enabled on the old primary database at the time of the failover. This procedure brings the old primary database back into the Data Guard configuration as a physical standby database.
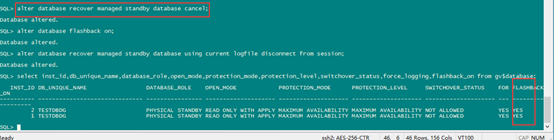
查看主备库状态:
set lin 200
set pages 50
select inst_id,db_unique_name,database_role,open_mode,protection_mode,protection_level,switchover_status,force_logging,flashback_on from gv$database;
主:

备:

开启主备库闪回:(主库可以不用开启)
需要设置reco
show parameter recov;
alter system set db_recovery_file_dest_size=1g scope=both;
alter system set db_recovery_file_dest='+data' scope=both;
alter database flashback on;
主:

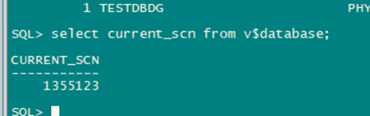
查看主库SCN(可以直接查看备库SCN,不用看主库SCN,如果DG是同步状态):
select current_scn from v$database;

Step 1 Determine the SCN at which the old standby database became the primary database.
On the new primary database, issue the following query to determine the SCN at which the old standby database became the new primary database:
select current_scn from v$database;
查看备库SCN:
SQL> SELECT TO_CHAR(STANDBY_BECAME_PRIMARY_SCN) FROM V$DATABASE;
Step 2 Flash back the failed primary database.
备库failover 之后:

Shut down the old primary database (if necessary), mount it, and flash it back
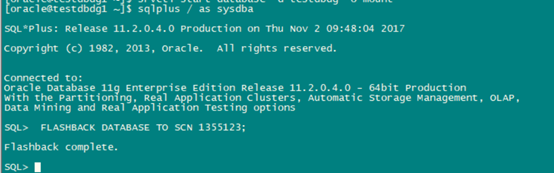
Shut down the old primary database (if necessary), mount it, and flash it back to the value for STANDBY_BECAME_PRIMARY_SCN that was determined in Step 1.
SQL> SHUTDOWN IMMEDIATE;

建议只开启节点1,后面转换成备库需要关闭节点2
SQL> STARTUP MOUNT;--只开启节点1,节点2开启了后面也需要shutdown
SQL> FLASHBACK DATABASE TO SCN standby_became_primary_scn;

Step 3 Convert the database to a physical standby database.
Perform the following steps on the old primary database:
- Issue the following statement on the old primary database:
建议只开启节点1,关闭节点2,如果不关闭其他节点,后续报错如后图(step 4)。
SQL> ALTER DATABASE CONVERT TO PHYSICAL STANDBY; 闪回后,执行如下语句。
This statement will dismount the database after successfully converting the control file to a standby control file.
- Shut down and restart the database:
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP MOUNT;
Step 4 Start transporting redo to the new physical standby database.
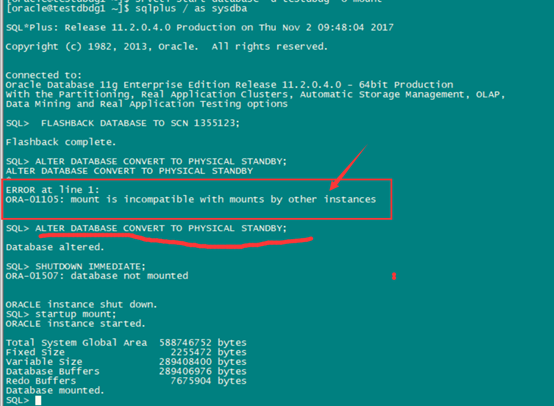
上图中需要关闭节点2实例,节点1mount 状态,convert成功后,后执行应用日志即可(Step 5 ):
Perform the following steps on the new primary database:
- Issue the following query to see the current state of the archive destinations:
SQL> SELECT DEST_ID, DEST_NAME, STATUS, PROTECTION_MODE, DESTINATION, ERROR,SRL FROM V$ARCHIVE_DEST_STATUS;
- If necessary, enable the destination:
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_n=ENABLE;
- Perform a log switch to ensure the standby database begins receiving redo data from the new primary database, and verify it was sent successfully. Issue the following SQL statements on the new primary database:
SQL> ALTER SYSTEM SWITCH LOGFILE;
SQL> SELECT DEST_ID, DEST_NAME, STATUS, PROTECTION_MODE, DESTINATION,ERROR,SRL FROM V$ARCHIVE_DEST_STATUS;
On the new standby database, you may also need to change the LOG_ARCHIVE_DEST_n initialization parameters so that redo transport services do not transmit redo data to other databases.
Step 5 Start Redo Apply on the new physical standby database.
Issue the following SQL statement on the new physical standby database:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT;
Redo Apply automatically stops each time it encounters a redo record that is generated as the result of a role transition, so Redo Apply will need to be restarted one or more times until it has applied beyond the SCN at which the new primary database became the primary database. Once the failed primary database is restored and is running in the standby role, you can optionally perform a switchover to transition the databases to their original (pre-failure) roles. See Section 8.2.1, "Performing a Switchover to a Physical Standby Database" for more information.
闪回并转换为物理备库后后应用日志,并做同步测试

闪回后 备库追日志初始化一会儿后:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT;


附带几句查看主备库状态以及同步语句:
查看主备库状态
set lines 150;
col db_unique_name for a10
select inst_id,db_unique_name,database_role,open_mode,protection_mode,protection_level,switchover_status,force_logging from gv$database;
查看日志序列号:
set lin 200
select thread#,max(sequence#) from v$archived_log group by thread#;
select pid,process,client_process,client_pid,thread#,sequence#,status,DELAY_MINS from v$managed_standby;
查看备库STANDBY REDO LOG状态
set pages 100
set lines 200
select group#,thread#,sequence#,bytes/1024/1024,archived,used,status,first_change#,last_change# from v$standby_log;