11G R2环境:
--DISTINCT测试前的准备
drop table t purge;
create table t as select * from dba_objects;
update t set object_id=rownum;
alter table T modify OBJECT_ID not null;
update t set object_id=2;
update t set object_id=3 where rownum<=25000;
commit;
/****
在oracle10g的R2环境之后,DISTINCT由于其 HASH UNIQUE的算法导致其不会产生排序,其调整的 ALTER SESSION SET "_gby_hash_aggregation_enabled" = FALSE
****/
set linesize 1000
set autotrace traceonly
select distinct object_id from t ;
执行计划:
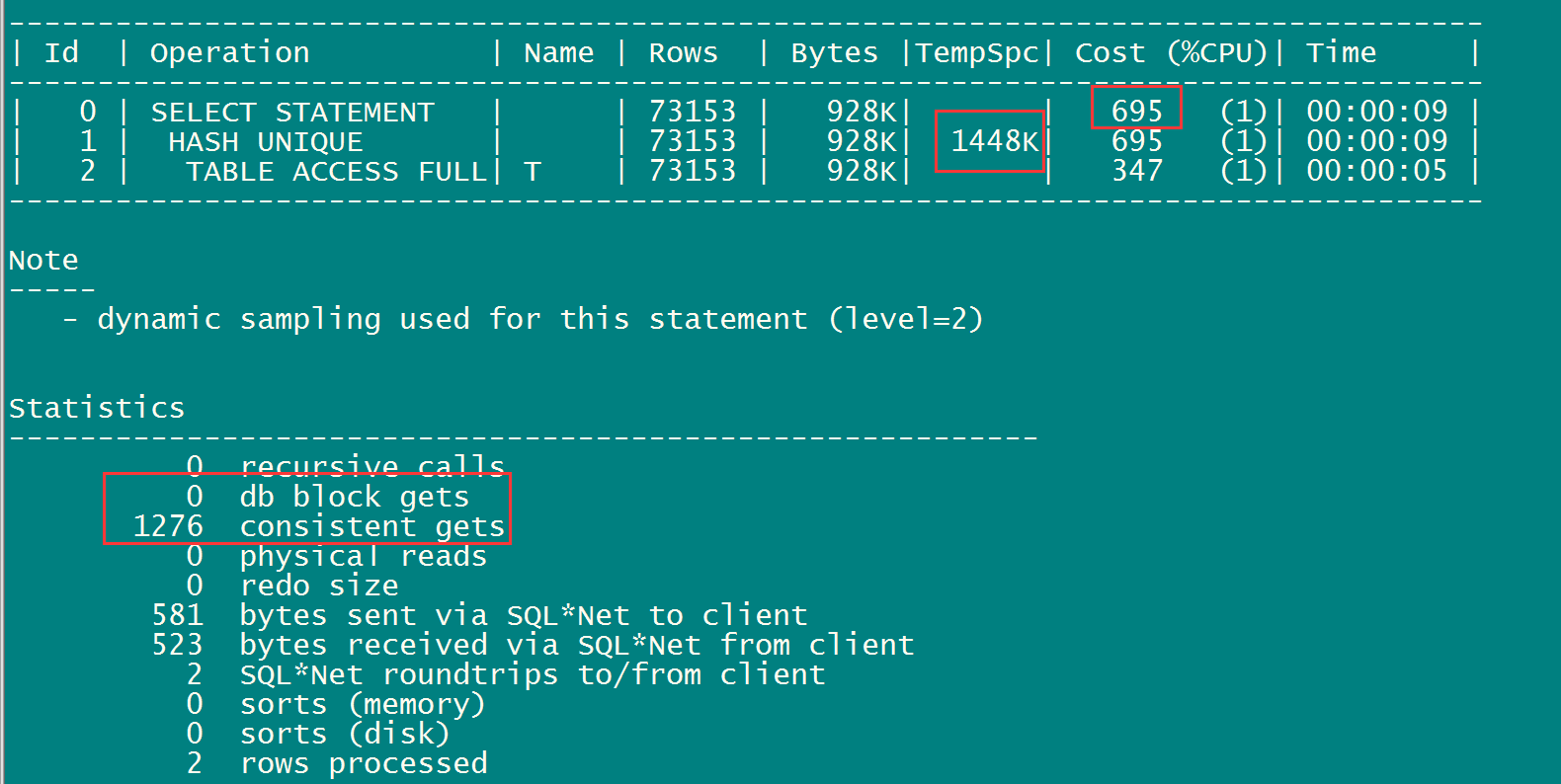
可以看出以上语句执行计划,占用内存1448k,逻辑读1276。
/*不过虽然没有排序,通过观察TempSpc可知distinct消耗PGA内存进行HASH UNIQUE运算,
接下来看看建了索引后的情况,TempSpc关键字立即消失,COST也立即下降许多,具体如下*/
--为T表的object_id列建索引
create index idx_t_object_id on t(object_id);
set linesize 1000
set autotrace traceonly
select /*+index(t)*/ distinct object_id from t ;

可以看出cost降低到525,走的索引,没有进行排序,逻辑读也降低了到176。