背景
数据库分区表数据越来越大,需要对过期话的数据进行迁移,以及大的分区表需要进行数据的清理和删除,达到释放磁盘空间的目的。
问题说明
环境:linux 6.X
数据库:oracle 11.2.0.4 (PSU为2016年6月份的)
问题说明:
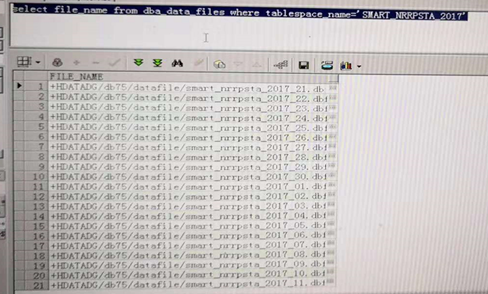
S_T_RTNRP_STATUS_2017是分区表,每天一个分区,且一共使用了2.5TB的空间,现在需要进行空间清理,操作步骤是先对表进行truncate,然后删除表,后对相应的表空间的每个数据文件进行resize成1g,在进行删除表空间语句
drop tablespace SMART_NRRPSTA_2017 including contents and datafiles。
但是,从2018.11.14 20:00一直到15日10:00,表空间没有删除,且数据字典中都能够查询得到数据文件,hang住。
如下:
处理过程
1) 初步怀疑(以为是上次遗留问题)
初步怀疑是ASM进程问题,因为之前我删除过一个大的表空间,是在业务期,业务用户在查询大的报表,IO开销很严重,中途暂停,表空间没有清理干净,后面再进行删除,表空间删除了,但是ASM磁盘组中数据文件有的没有进行删除,初步怀疑是上次遗留问题,认为是上次没有释放的ASM进程阻塞表空间的删除。
查看阻塞的等待事件:
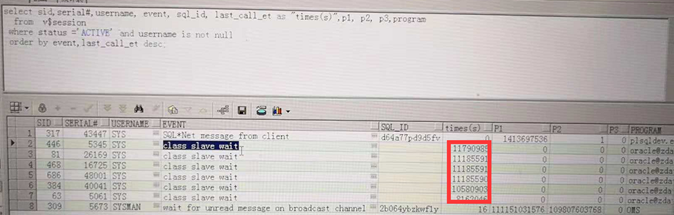
查看等待事件中,运行时间很长的是class slave wait这类等待事件,查看有关这类事件的进程号,以及信息:
ps -ef |grep 41751
ps -ef |grep 68563
ps -ef |grep 25232
ps -ef |grep 34478
ps -ef |grep 12445
ps -ef |grep 34699
ps -ef |grep 25217
ps -ef |grep 68559
ps -ef |grep 62666
ps -ef |grep 20972
ps -ef |grep 11554
ps -ef |grep 68590
看到的全是ora_o开头的进程,查询相关资料,百度到的盖国强老师的论坛:http://www.eygle.com/archives/2012/06/oracle_o001_o00n_cpu.html以及MOS账号里面的资料,说的大部分是Oracle ora_o进程 100% CPU占用的案例,但是事实的ora_o进程并没有占用很高的CPU,也没有进程阻塞,官方也没有对其进程进行详细说明。

后面我还是把相关进程杀掉(由于生产环境,不敢全部杀死,也不敢直接执行kil -9 操作系统命令,先在数据库层杀一个看看,发现杀掉后,系统自动启动一个新的进程,后面才全部执行)
alter system kill session '504,53407';
alter system kill session '599,61619';
alter system kill session '498,38267';
alter system kill session '366,62377';
alter system kill session '401,27591';
alter system kill session '446,5345 ';
alter system kill session '230,11603';
alter system kill session '81,26169 ';
alter system kill session '468,16725';
alter system kill session '686,48001';
alter system kill session '384,40041';
等了一会儿,发现drop tablespace语句仍然是无进展,一样的hang住,在support上查询,怀疑是BUG也发现情况不符合。
2) 柳暗花明
开始怀疑不是上一次遗留的问题,怀疑是其他进程导致表空间删除hang住。
进行AWR,生成的时间是删除hang住那段时间:
DB time如下

发现DB time/(DB time+Elapsed)时间比例并不是特别高,
查看TOP 10等待事件

占用第一个的是TT等待事件,查看整个会话的等待事件:
select event,count(1) from gv$session group by event order by 2;
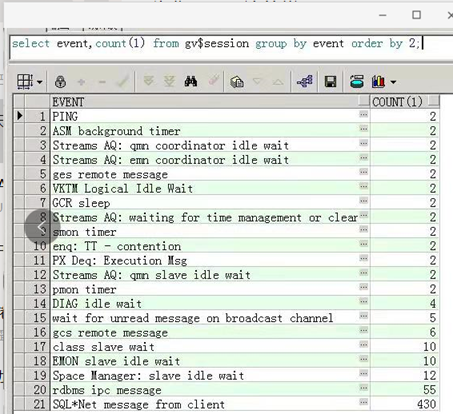
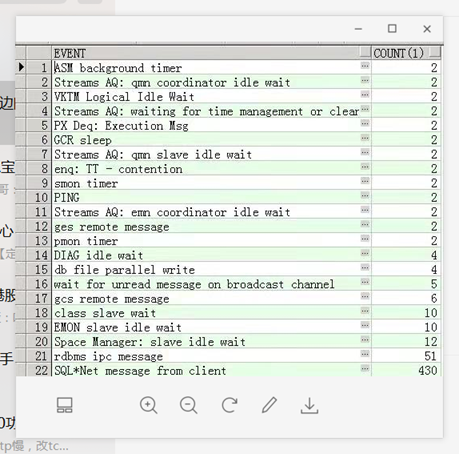
查看具体的TT - contention等待事件:

突然想起来了,自己搭建的一套OEM监控数据库,其中sysman用户登录,sys用户监控磁盘组,这两个会话阻塞导致drop tablespace hang住。
3) 处理措施
停止RAC两个节点的OEM agent
如下图:
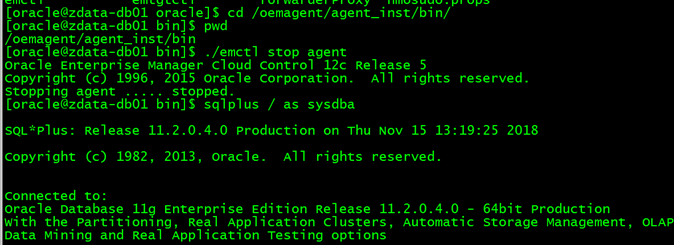
停止后,查看alert日志:
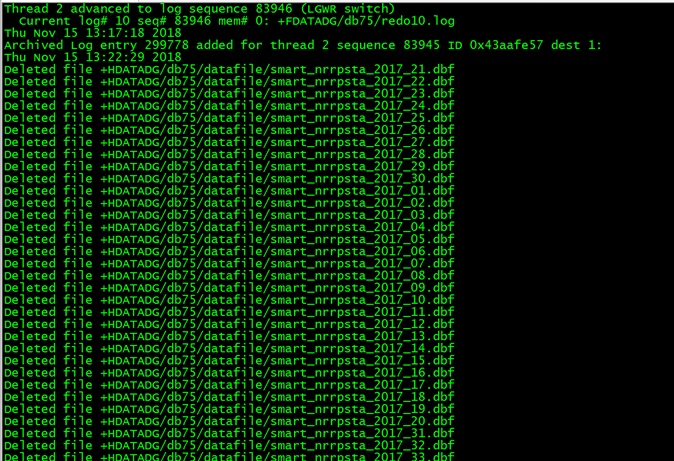
成功删除了表空间并释放了磁盘组的空间。
4) 总结
1、 遇到问题要根据实际情况解决。
2、 感谢阿里的周卫丰周大牛帮我一起解决故障(虽然是小问题)。