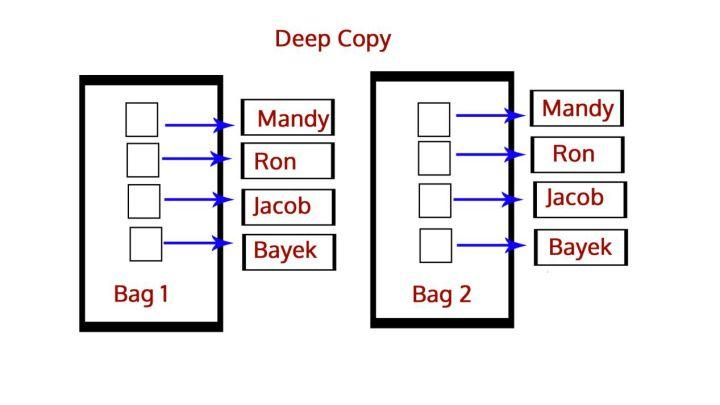
JS数据类型
Q:前端面试常问,JS的基本数据类型有哪些呀?
A:JS数据类型分为基本数据类型和引用数据类型,详细分类如下:

Q:基本数据类型和引用数据类型的储存方式有什么不同?
A:
基本数据类型:变量名和值都储存在栈内存中,例如:
var num=10;num变量在内存中储存如下:

引用数据类型:变量名储存在栈内存中,值储存在堆内存中,但是堆内存中会提供一个引用地址指向堆内存中的值,而这个地址是储存在栈内存中的,例如:
var arr=[1,2,3,4,5];arr变量在内存中的储存如下:

对这几个概念有了初步了解之后,接下来正式开始讲深浅拷贝。
什么是浅拷贝和深拷贝
在讲两者概念之前我们先看一个需求:现在有一个对象A,需求是将A拷贝一份到B对象当中?
浅拷贝
当B拷贝了A的数据,且当B的改变会导致A的改变时,此时叫B浅拷贝了A,例如:
//浅拷贝
var A={
name:"martin",
data:{num:10}
}
var B={}
var B=A;
B.name="lucy";
console.log(A.name); //lucy
A直接赋值给B后,B中name属性的改变导致了A中name属性也发生了变化。

其实是因为这种赋值方式只是将A的堆内存地址赋值给了B,A和B储存的是同一个地址,指向的是同一个内容,因此B的改变当然会引起A的改变。
浅拷贝的方式
- 直接赋值
第一种方式就是上面所写代码中的将对象地址直接进行赋值。
var A={
name:"martin",
data:{num:10}
};
var B={};
B=A;
B.name="lucy";
console.log(A.name); //"lucy",A中name属性已改变- Object.assign(target,source)
这是ES6中新增的对象方法,对它不了解的见ES6对象新增方法,它可以实现第一层的“深拷贝”,但无法实现多层的深拷贝。
以当前A对象进行说明
第一层“深拷贝”:就是对于A对象下所有的属性和方法都进行了深拷贝,但是当A对象下的属性如data是对象时,它拷贝的是地址,也就是浅拷贝,这种拷贝方式还是属于浅拷贝。
多层深拷贝:能将A对象下所有的属性,及时属性是对象,也能够深拷贝出来,让A和B相互独立,这种叫才叫深拷贝。
var A={
name:"martin",
data:{num:10},
say:function(){
console.log("hello world")
}
}
var B={}
Object.assign(B,A); //将A拷贝到B
B.name="lucy";
console.log(A.name); //martin,发现A中name并没有改变
B.data.num=5;
console.log(A.data.num); //5,发现A中data的num属性改变了,说明data对象没有被深拷贝
- 浅拷贝总结
直接赋值:这种方式实现的就是纯粹的浅拷贝,B的任何变化都会反映在A上。
Object.assign():这种方式实现的实现的是单层“深拷贝”,但不是意义上的深拷贝,对深层还是实行的浅拷贝。
深拷贝
当B拷贝了A的数据,且当B的改变不会导致A的改变时,此时叫B深拷贝了A,例如:
//深拷贝
var A={
name:"martin",
data:{num:10},
say:function(){
console.log("hello world")
}
} //开辟了一个新的堆内存地址,假设为placaA
var B={}; //又开辟了一个新的堆内存地址,假设为placeB
B=JSON.parse(JSON.stringfy(A));
B.name="lucy";
console.log(A.name); //martin
通过JSON对象方法实现对象的深拷贝,我们可以看到其中B.name值的改变并没有影响A.name的值,因为A和B分别指向不同的堆内存地址,因此两者互不影响。
深拷贝的方式
理解了深浅拷贝,接下来说一下深拷贝的几种方式。
首先假设一个已知的对象A,然后需要把A深拷贝到B。
var B={};
- 递归赋值
function deepCopy(A,B) {
for(item in A){//for in……如果遍历数组则会返回下标,如果遍历对象则返回属性Key值,所以数组下A[item]是一个值,对象B[item]是value值
if(typeof A[item]=="object"){
deepCopy(A[item],B[item]);
}else{
B[item]=A[item];
}
}
}
deepCopy(A,B);
B.data.num=5;
console.log(A.data.num); //10,A中属性值并没有改变,说明是深拷贝
//上面代码本该正常运行,但是运行了一下,还是没有进行深拷贝 因为需要在递归处,有一处:B['data']['num']=A['num'],此处由于B['num']还没生成,所以出错,修改后:
自己封装一个判别类型的函数可以代替typeof功能,可以采用object.prototype.tostring进行判断,具体这个是什么玩意,可以看看这个https://www.cnblogs.com/hmy-666/p/14439886.html
扩展开始:
/* 说说它们的输出情况 */ function checkType(target) { //因为Object.prototype.toString.call(target)返回的是字符串类型[object 类型] //例子:[object arry],所以截取object后面的就是类型 return Object.prototype.toString.call(target).slice(8, -1); }
自己封装判断类型的函数在于比typeof更强大,因为typeof null ==object,但是checkType(null)=null
扩展结束:
通过这种方式能实现深层拷贝,而且能自由控制拷贝是如何进行的,如:当B中有和A同名的属性,要不要重新赋值?这些都可以进行控制,但是代码相对复杂一些。
- JSON.parse()和JSON.stringify
var B=JSON.parse(JSON.stringify(A));
B.data.num=5;
console.log(A.data.num); //10,A中属性值并没有改变,说明是深拷贝
用这种方式实现深拷贝的时候要 , ,上述代码中B也并没有拷贝出A中的say函数,这和JSON.stringify方法的规则有关系,它在序列化的时候会直接忽略函数,因此最后A中的say函数没有被拷贝到B,关于JSON.stringify序列化的具体规则见JSON.stringify指南。
这里说一下JSON.stringify为什么处理不了函数对象,因为JSON提供的方法目的是为了转化为前后台交互的Json数据格式,因为这种数据格式只有普通对象类型和数组,所以JSON.stringify只能传入普通对象和数组。函数这种特殊对象它会直接忽略。
- 深拷贝总结
递归:使用递归进行深拷贝时比较灵活,但是代码较为复杂;
JSON对象:JSON对象方法实现深拷贝时比较简单,但是当拷贝对象包含方法时,方法会被丢失;
因此使用者可按自身的使用场景来选择拷贝方式。
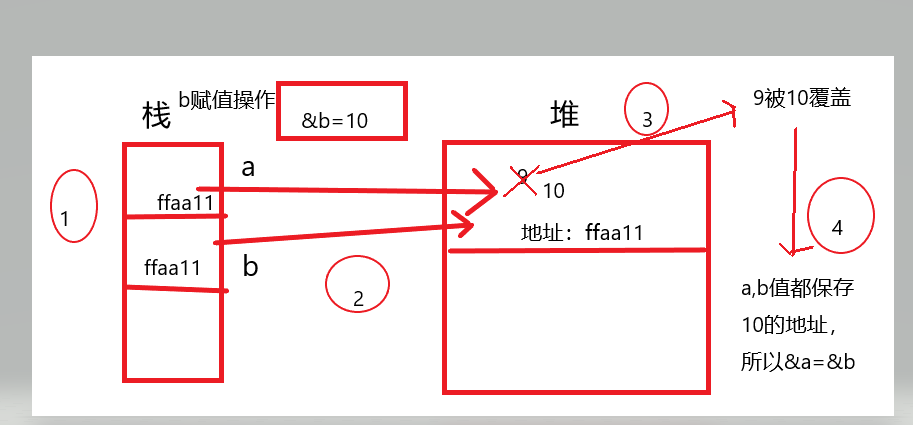
再讲一下赋值:
int a =9;
int b =10;
b = a;
赋值仅仅是进行值复制操作而以,没有开辟内存,准确来说没有在堆中开辟内存,因为ab变量初始化时已经在栈中开辟了内存,所以ab属于两个不同内存的变量。
基本数据类型内存创建:

引用数据类型创建内存:
int *a = 10;
int *b = &a;
b = 9
打印a:9
打印b:9
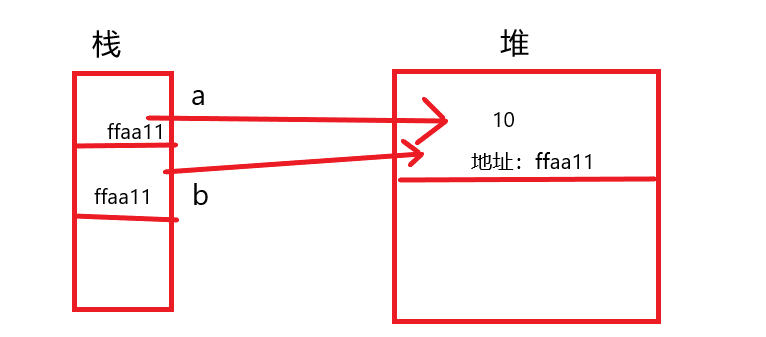
引用对象在栈中只保存地址,数据保存于堆中;
其实深拷贝也运用了赋值的思想,就是先开辟新的内存,再直接复制数据。
//深拷贝 var A={ name:"martin", data:{num:10}, say:function(){ console.log("hello world") } } //开辟了一个新的堆内存地址,假设为placaA var B={}; //又开辟了一个新的堆内存地址,假设为placeB B=JSON.parse(JSON.stringfy(A));//首先A先转为字符串,那么A已经转为基本数据类型,则必定A会重新开辟新的内存空间,再将A转为对象,此时A对象的数据的地址和原始A的地址不一样了。 B.name="lucy"; console.log(A.name); //martin

-----------------------------------------------------------------------
最后总结:赋值没有开辟内存,而拷贝有开辟新内存。而拷贝分为深拷贝,浅拷贝。比如A浅拷贝了某B引用对象,那么修改A的属性值,B也会改变。深拷贝:重新开辟内存,比如A深拷贝了某B引用对象,则栈中A保存的地址是堆新开辟的内存,这个新内存保存着B的所有数据,那么修改A的属性值,B不会改变。
浅拷贝:拷贝的某对象的引用地址,修改会互相影响。
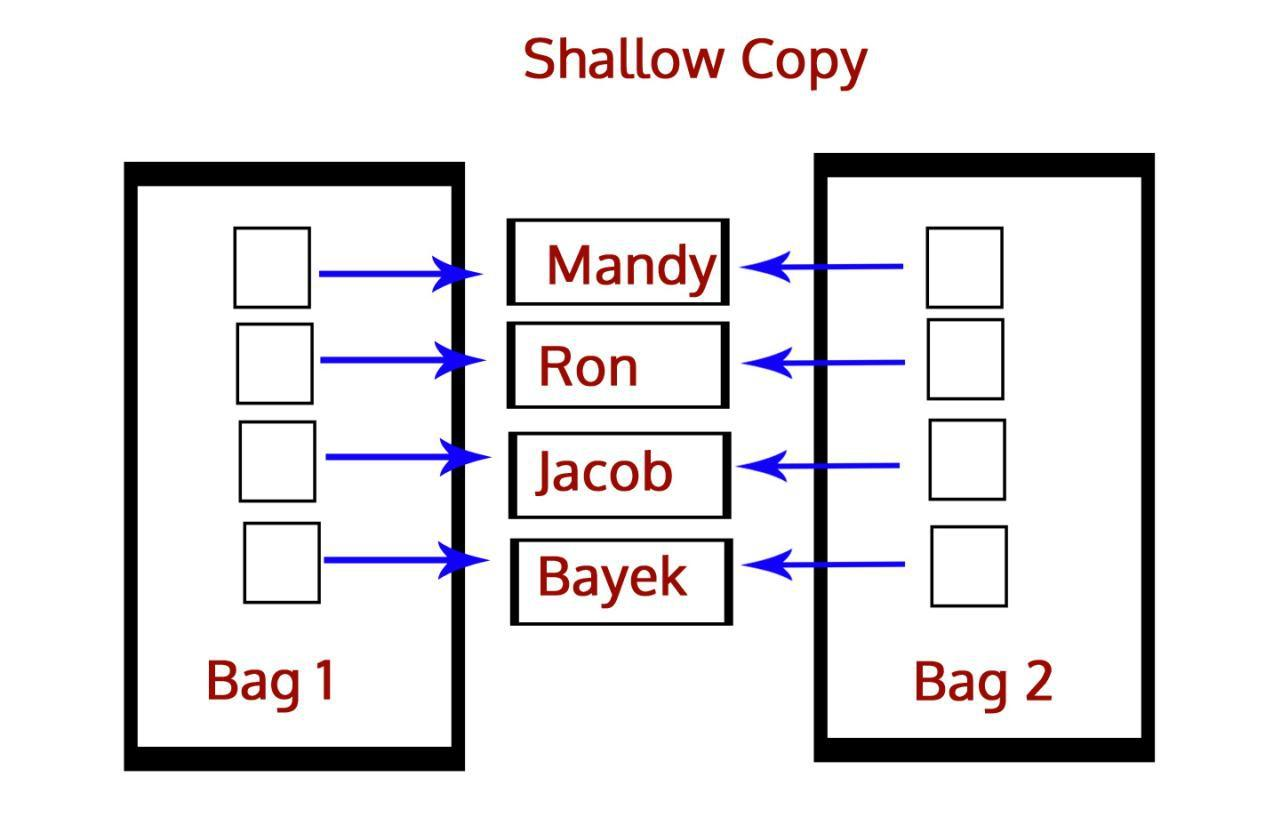
深拷贝:重新开辟内存空间,并复制一样的数据内容,修改不会互相影响。