经过索引优化,重构TSQL后你的数据库还存在性能问题吗?完全有可能,这时必须得找另外的方法才行。SQL Server在索引方面还提供了某些高级特性,可能你还从未使用过,利用高级索引会显著地改善系统性能,本文将从高级索引技术谈起,另外还将介绍反范式化技术。
第六步:应用高级索引
实施计算列并在这些列上创建索引
你可能曾经写过从数据库查询一个结果集的应用程序代码,对结果集中每一行进行计算生成最终显示输出的信息。例如,你可能有一个查询从数据库检索订单信息,在应用程序代码中你可能已经通过对产品和销售量执行算术操作计算出了总的订单价格,但为什么你不在数据库中执行这些操作呢?
请看下面这张图,你可以通过指定一个公式将一个数据库表列作为计算列,你的TSQL在查询清单中包括这个计算列,SQL引擎将会应用这个公式计算出这一列的值,在执行查询时,数据库引擎将会计算订单总价,并为计算列返回结果。
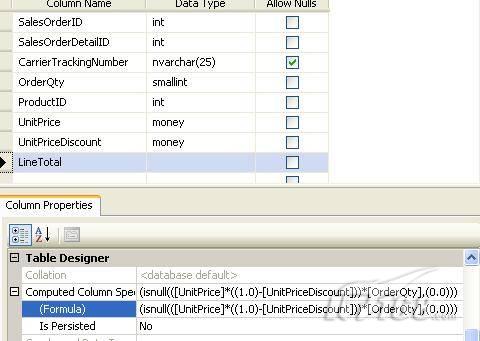
图 1 计算列
使用计算列你可以将计算工作全部交给后端执行,但如果表的行数太多可能计算性能也不高,如果计算列出现在Select查询的where子句中情况会更糟,在这种情况下,为了匹配where子句指定的值,数据库引擎不得不计算表中所有行中计算列的值,这是一个低效的过程,因为它总是需要全表扫描或全聚集索引扫描。
因此问题就来了,如何提高计算列的性能呢?解决办法是在计算列上创建索引,当计算列上有索引后,SQL Server会提前计算结果,然后在结果之上构建索引。此外,当对应列(计算列依赖的列)的值更新时,计算列上的索引值也会更新。因此,在执行查询时,数据库引擎不会为结果集中的每一行都执行一次计算公式,相反,通过索引可直接获得计算列预先计算出的值,因此在计算列上创建一个索引将会加快查询速度。
提示:如果你想在计算列上创建索引,必须确保计算列上的公式不能包括任何“非确定的”函数,例如getdate()就是一个非确定的函数,因为每次调用它,它返回的值都是不一样的。
创建索引视图
你是否知道可以在视图上创建索引?OK,不知道没关系,看了我的介绍你就明白了。
为什么要使用视图?
大家都知道,视图本身不存储任何数据,只是一条编译的select语句。数据库会为视图生成一个执行计划,视图是可以重复使用的,因为执行计划也可以重复使用。
视图本身不会带来性能的提升,我曾经以为它会“记住”查询结果,但后来我才知道它除了是一个编译了的查询外,其它什么都不是,视图根本记不住查询结果,我敢打赌好多刚接触SQL的人都会有这个错误的想法。
但是现在我要告诉你一个方法让视图记住查询结果,其实非常简单,就是在视图上创建索引就可以了。
如果你在视图上应用了索引,视图就成为索引视图,对于一个索引视图,数据库引擎处理SQL,并在数据文件中存储结果,和聚集表类似,当基础表中的数据发生变化时,SQL Server会自动维护索引,因此当你在索引视图上查询时,数据库引擎简单地从索引中查找值,速度当然就很快了,因此在视图上创建索引可以明显加快查询速度。
但请注意,天下没有免费的午餐,创建索引视图可以提升性能,当基础表中的数据发生变化时,数据库引擎也会更新索引,因此,当视图要处理很多行,且要求和,当数据和基础表不经常发生变化时,就应该考虑创建索引视图。
如何创建索引视图?
1)创建/修改视图时指定SCHEMABINDING选项:
WITH SCHEMABINDING
AS
SELECT…
2)在视图上创建一个唯一的聚集索引;
3)视需要在视图上创建一个非聚集索引。
不是所有视图上都可以创建索引,在视图上创建索引存在以下限制:
1)创建视图时使用了SCHEMABINDING选项,这种情况下,数据库引擎不允许你改变表的基础结构;
2)视图不能包含任何非确定性函数,DISTINCT子句和子查询;
3)视图中的底层表必须由聚集索引(主键)。
如果你发现你的应用程序中使用的TSQL是用视图实现的,但存在性能问题,那此时给视图加上索引可能会带来性能的提升。
为用户定义函数(UDF)创建索引
在用户定义函数上也可以创建索引,但不能直接在它上面创建索引,需要创建一个辅助的计算列,公式就使用用户定义函数,然后在这个计算列字段上创建索引。具体步骤如下:
1)首先创建一个确定性的函数(如果不存在的话),在函数定义中添加SCHEMABINDING选项,如:
(
-- Add the parameters for the function here
@UnitPrice [money],
@UnitPriceDiscount [money],
@OrderQty [smallint]
)
RETURNS money
WITH SCHEMABINDING
AS
BEGIN
return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty))
END
2)在目标表上增加一个计算列,使用前面定义的函数作为该列的计算公式,如图2所示。
(
-- Add the parameters for the function here
@UnitPrice [money],
@UnitPriceDiscount [money],
@OrderQty [smallint]
)
RETURNS money
WITH SCHEMABINDING
AS
BEGIN
return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty))
END
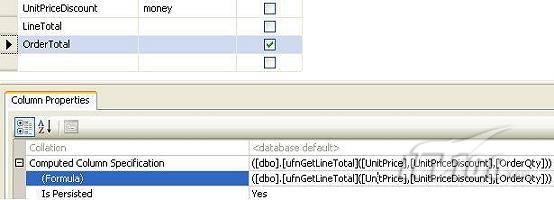
图 2 指定UDF为计算列的结算公式
3)在计算列上创建索引
当你的查询中包括UDF时,如果在该UDF上创建了以计算列为基础的索引,特别是两个表或视图的连接条件中使用了UDF,性能都会有明显的改善。
在XML列上创建索引
在SQL Server(2005和后续版本)中,XML列是以二进制大对象(BLOB)形式存储的,可以使用XQuery进行查询,但如果没有索引,每次查询XML数据类型时都非常耗时,特别是大型XML实例,因为SQL Server在运行时需要分隔二进制大对象评估查询。为了提升XML数据类型上的查询性能,XML列可以索引,XML索引分为两类。
主XML索引
创建XML列上的主索引时,SQL Server会切碎XML内容,创建多个数据行,包括元素,属性名,路径,节点类型和值等,创建主索引让SQL Server更轻松地支持XQuery请求。下面是创建一个主XML索引的示例语法。
index_name
ON <object> ( xml_column )
次要XML索引
虽然XML数据已经被切条,但SQL Server仍然要扫描所有切条的数据才能找到想要的结果,为了进一步提升性能,还需要在主XML索引之上创建次要XML索引。有三种次要XML索引。
1)“路径”(Path)次要XML索引:使用.exist()方法确定一个特定的路径是否存在时它很有用;
2)“值”(Value)次要XML索引:用于执行基于值的查询,但不知道完整的路径或路径包括通配符时;
3)“属性”(Secondary)次要XML索引:知道路径时检索属性的值。
下面是一个创建次要XML索引的示例:
index_name
ON <object> ( xml_column )
USING XML INDEX primary_xml_index_name
FOR { VALUE | PATH | PROPERTY }
请注意,上面讲的原则是基础,如果盲目地在表上创建索引,不一定会提升性能,因为有时在某些表的某些列上创建索引时,可能会致使插入和更新操作变慢,当这个表上有一个低选中性列时更是如此,同样,当表中的记录很少(如<500)时,如果在这样的表上创建索引反倒会使数据检索性能降低,因为对于小表而言,全表扫描反而会更快,因此在创建索引时应放聪明一点。
第七步:应用反范式化,使用历史表和预计算列
反范式化
如果你正在为一个OLTA(在线事务分析)系统设计数据库,主要指为只读查询优化过的数据仓库,你可以(和应该)在你的数据库中应用反范式化和索引,也就是说,某些数据可以跨多个表存储,但报告和数据分析查询在这种数据库上可能会更快。
但如果你正在为一个OLTP(联机事务处理)系统设计数据库,这样的数据库主要执行数据更新操作(包括插入/更新/删除),我建议你至少实施第一、二、三范式,这样数据冗余可以降到最低,数据存储也可以达到最小化,可管理性也会好一点。
无论我们在OLTP系统上是否应用范式,在数据库上总有大量的读操作(即select查询),当应用了所有优化技术后,如果发现数据检索操作仍然效率低下,此时,你可能需要考虑应用反范式设计了,但问题是如何应用反范式化,以及为什么应用反范式化会提升性能?让我们来看一个简单的例子,答案就在例子中。
假设我们有两个表OrderDetails(ID,ProductID,OrderQty) 和 Products(ID,ProductName)分别存储订单详细信息和产品信息,现在要查询某个客户订购的产品名称和它们的数量,查询SQL语句如下:
FROM OrderDetails INNER JOIN Products
ON OrderDetails.ProductID = Products.ProductID
WHERE SalesOrderID = 47057
如果这两个都是大表,当你应用了所有优化技巧后,查询速度仍然很慢,这时可以考虑以下反范式化设计:
1)在OrderDetails表上添加一列ProductName,并填充好数据;
2)重写上面的SQL语句
FROM OrderDetails
WHERE SalesOrderID = 47057
注意在OrderDetails表上应用了反范式化后,不再需要连接Products表,因此在执行SQL时,SQL引擎不会执行两个表的连接操作,查询速度当然会快一些。
为了提高select操作性能,我们不得不做出一些牺牲,需要在两个地方(OrderDetails 和 Products表)存储相同的数据(ProductName),当我们插入或更新Products 表中的ProductName字段时,不得不同步更新OrderDetails表中的ProductName字段,此外,应用这种反范式化设计时会增加存储资源消耗。
因此在实施反范式化设计时,我们必须在数据冗余和查询操作性能之间进行权衡,同时在应用反范式化后,我们不得不重构某些插入和更新操作代码。有一个重要的原则需要遵守,那就是只有当你应用了所有其它优化技术都还不能将性能提升到理想情况时才使用反范式化。同时还需注意不能使用太多的反范式化设计,那样会使原本清晰的表结构设计变得越来模糊。
历史表
如果你的应用程序中有定期运行的数据检索操作(如报表),如果涉及到大表的检索,可以考虑定期将事务型规范化表中的数据复制到反范式化的单一的历史表中,如利用数据库的Job来完成这个任务,并对这个历史表建立合适的索引,那么周期性执行的数据检索操作可以迁移到这个历史表上,对单个历史表的查询性能肯定比连接多个事务表的查询速度要快得多。
例如,假设有一个连锁商店的月度报表需要3个小时才能执行完毕,你被派去优化这个报表,目的只有一个:最小化执行时间。那么你除了应用其它优化技巧外,还可以采取以下手段:
1)使用反范式化结构创建一个历史表,并对销售数据建立合适的索引;
2)在SQL Server上创建一个定期执行的操作,每隔24小时运行一次,在半夜往历史表中填充数据;
3)修改报表代码,从历史表获取数据。
创建定期执行的操作
按照下面的步骤在SQL Server中创建一个定期执行的操作,定期从事务表中提取数据填充到历史表中。
1)首先确保SQL Server代理服务处于运行状态;
2)在SQL Server配置管理器中展开SQL Server代理节点,在“作业”节点上创建一个新作业,在“常规”标签页中,输入作业名称和描述文字;
3)在“步骤”标签页中,点击“新建”按钮创建一个新的作业步骤,输入名字和TSQL代码,最后保存;
4)切换到“调度”标签页,点击“新建”按钮创建一个新调度计划;
5)最后保存调度计划。
在数据插入和更新中提前执行耗时的计算,简化查询
大多数情况下,你会看到你的应用程序是一个接一个地执行数据插入或更新操作,一次只涉及到一条记录,但数据检索操作可能同时涉及到多条记录。
如果你的查询中包括一个复杂的计算操作,毫无疑问这将导致整体的查询性能下降,你可以考虑下面的解决办法:
1)在表中创建额外的一列,包含计算的值;
2)为插入和更新事件创建一个触发器,使用相同的计算逻辑计算值,计算完成后更新到新建的列;
3)使用新创建的列替换查询中的计算逻辑。
实施完上述步骤后,插入和更新操作可能会更慢一点,因为每次插入和更新时触发器都会执行一下,但数据检索操作会比之前快得多,因为执行查询时,数据库引擎不会执行计算操作了。
小结
至此,我们已经应用了索引,重构TSQL,应用高级索引,反范式化,以及历史表加速数据检索速度,但性能优化是一个永无终点的过程,最下一篇文章中我们将会介绍如何诊断数据库性能问题。