
更多技术文章分享及测试资料点此获取
单一职责
单一职责是设计原则 SOLD 中的 S ,英文是 Single Responsibility Principle。从名字上看,单一职责字面意思是任务专一,举个例子,如果一位后端程序员只开发后端,就可以说这个人职责单一,但后端程序员既做前端,又开发后端,还要维护服务器,那程序员的职责就不够单一。
单一职责表示类或者模块的责任应该单一。这里的类和模块就像大圆和小圆,类是小圆,代表细粒度的代码,比如函数,类,甚至是变量名等等。职责不够单一表现是:
- 函数设计的大而全:数据读取函数既包括路径解析,又包括目录查找和数据检测。
- 类内的方法多而杂:动物类包括猫行走方法,猫奔跑方法,狗行走方法...。
- 变量名或函数名含义模糊:变量名或函数名全取 util , commmon 等通用名字。
模块是大圆,代表粗粒度的代码,比如一个文件(包含多个类)。职责不够单一表现是:
- 资源模块包含与资源无关的类:比如 resource 模块中包含日志提取类。

可以看出,不论大圆还是小圆,都在强调一件事:不要设计大而全(粗糙),要设计功能单一(精细)代码,只要设计的不够专一,就可以说违反了单一职责原则。但现实开发中,单一职责很难有清晰的判定标准,比如猫类,类内有关于猫的各种方法:小跑,快跑,吃鱼干,吃猫粮,喝白开水,喝纯净水,站立,躺着,睡觉。如果把与猫相关的动作都加进来,这个类显得有些臃肿。你可以思考一下如何修改,才能让猫类职责更单一:

比较合理的方法是拆分。可以把猫类拆分成三个小类,分而治之,分别是猫-动作,猫-吃喝和猫-静止。拆分后的三个类功能更单一,但这样拆分是否符合所有需求?
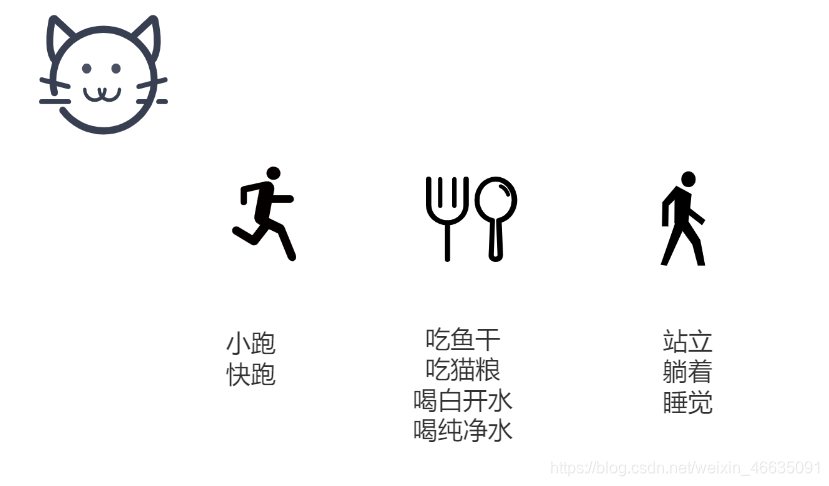
很遗憾,拆分后的类不能满足所有需求。宠物医院只关心猫的健康状态,他们会把猫类按照健康和非健康进行拆分。相对而言,经常运动是健康的,比如小跑,快跑,而吃猫粮,喝纯净水也是健康的。那宠物医院对单一职责的理解就像下图:
注意:以上关于猫的观点纯属虚构,没有任何参考价值!
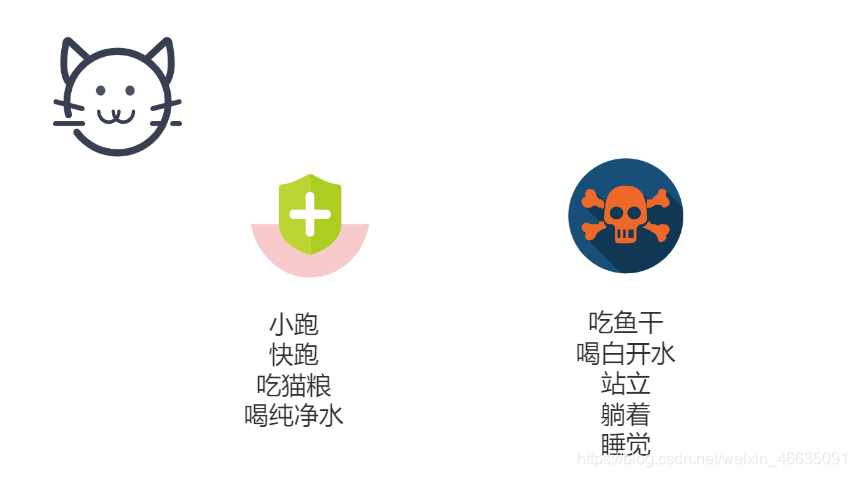
从上面得出结论:需求不同,对单一职责的理解也不同。单一职责就这么抽象?有没有一个放之四海而皆准的方法,来帮我们判断单一职责?很遗憾,并没有,这就是设计原则易懂难实施的原因。同一个方法,在 A 项目适用,在 B 项目就是过渡优化。下面介绍自己遇到的问题和解决方案,你可以作为参考来看,但是不要盲目模仿。
在编写测试框架时,需要加载指定目录下的 yaml 文件。为了让大家看懂,省略了代码细节(代码不可运行):
def load(path):
# 使用 yaml 读取函数,读取流中的 yaml 数据
data = yaml.load(path)
# 返回数据
return data
# 打印加载后的内容
load("tmp.yaml")
这段代码很简单,只需要用 yaml 库加载 path 路径传进来的 yaml 即可。随着调用次数增加,发现每次都要传路径,现加入新功能:自动遍历目录,找出符合要求的 yaml 文件。
def load(path, yaml_name="tmp.yaml"):
if os.path.isdir(path):
list = os.listdir(path) # 列出文件夹下所有的目录与文件
for i in range(0, len(list)):
# 递归遍历目录文件,找出和 yaml_name 相同的 yaml 文件
else:
# 使用 yaml 读取函数,读取流中的 yaml 数据
data = yaml.load(path)
# 返回数据
return data
# 打印加载后的内容,下列两种方式写法等价
load("c:/a/b/tmp/tmp.yaml")
load("c:/a", "tmp.yaml")
这段代码加入了目录遍历功能,通过 os.listdir 找出所有目录和文件,再进行递归遍历,直到遇到和 yaml_name 匹配的 yaml 文件为止。由于手动传入 path 还是不方便,现要求加入新的遍历方式:如果设置了环境变量 BASE_DIR ,那么 load 函数中的 path 参数就作废,按照环境变量 BASE_DIR 目录开始遍历,寻找 yaml_name 匹配的 yaml 文件。
def load(path=None, yaml_name=""):
if path is None:
# 从环境变量中找目录
path = os.getenv("BASE_DIR", default = "")
if os.path.isdir(path):
list = os.listdir(path) # 列出文件夹下所有的目录与文件
for i in range(0, len(list)):
# 递归遍历目录文件,找出和 yaml_name 相同的 yaml 文件
else:
# 使用 yaml 读取函数,读取流中的 yaml 数据
data = yaml.load(path)
# 返回数据
return data
# 打印加载后的内容,下列两种方式写法等价
load("c:/a/b/tmp/tmp.yaml")
load("c:/a", "tmp.yaml")
load(yaml_name="tmp.yaml")
上述代码加入了环境变量获取,目前还算简单。随着需求增加, load 函数会越来越复杂,未来可能支持正则匹配,目录黑名单,限制查找子目录的层级...。 load 函数会变得大而全,违反了单一职责,可以对 load 进行拆分:
def load_by_data(yaml_name):
# 使用 yaml 读取函数,读取流中的 yaml 数据
data = yaml.load(path)
return data
def load_by_dir(path=None, yaml_name=""):
if not os.path.isdir(path):
raise ValueError()
list = os.listdir(path) # 列出文件夹下所有的目录与文件
data = None
for i in range(0, len(list)):
# 递归遍历目录文件,找出和 yaml_name 相同的 yaml 文件
data = load_by_data(xxx)
return data
def load_by_env(yaml_name):
# 从环境变量中找目录
path = os.getenv("BASE_DIR")
# 复用 load_by_dir
return load_by_dir(path, yaml_name)
def load(path=None, yaml_name=""):
if path is None:
return load_by_env(yaml_name, default = "")
elif os.path.isdir(path):
return load_by_dir(path, yaml_name)
else:
return load_by_data(yaml_name)
# 打印加载后的内容,下列两种方式写法等价
load("c:/a/b/tmp/tmp.yaml")
load("c:/a", "tmp.yaml")
load(yaml_name="tmp.yaml")
load 函数被拆分成多个小函数,这些小函数功能更单一:
-
load_by_data:直接查找
-
load_by_dir:从目录中查找
-
oad_by_env:从环境变量中查找
-
oad:组合上述功能
上述拆分只是一个例子,并不是最优解。单一职责有多种理解方式,最核心的还是程序编写者如何衡量,编写代码要多思考职责设计是否合理,拆分或重构后会不会增加复杂度,从而得不偿失。比如上述例子,如果 load 函数需求很简单,完全没有必要进行拆分。
本文章不是银弹,如果你在编写代码时,能够主动思考职责问题,那我的目的就达到了。衡量单一职责需要对业务足够了解,只有不断思考,不满足现状以及持续重构才能找到自己的尺子。
总结
-
单一职责表示类或者模块的责任应该单一。要注意类和模块就像大圆和小圆,类是小圆,代表细粒度的代码,比如函数,类,甚至是变量命;模块是大圆,代表粗粒度的代码,比如一个文件(包含多个类)。
-
不同需求有不同的拆分方式。没有一个放之四海而皆准的方法帮我们判断单一职责,同一个方法,在 A 项目适用,在 B 项目就是过渡优化。
-
衡量单一职责需要对业务足够了解,只有不断思考,不满足现状以及持续重构才能找到自己的尺子。