总体流程
下图展示了通过Hystirx向依赖发送请求的流程:
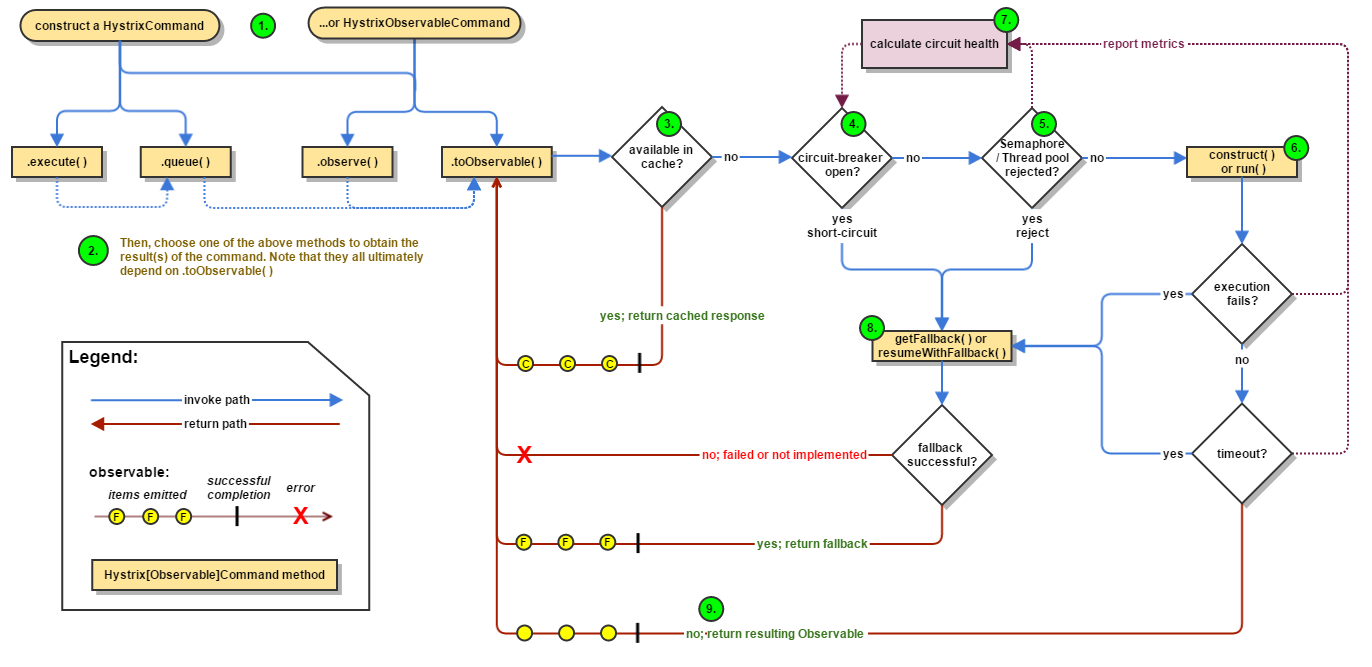
1.构造HystrixCommand或HystrixObservableCommand实例;
2.执行命令(command),有四种执行方式,execute()会调用queue().get(),queue()会调用toObservable().toBlocking().toFuture():
K value = command.execute(); Future<K> fValue = command.queue(); Observable<K> ohValue = command.observe(); //hot observable Observable<K> ocValue = command.toObservable(); //cold observable
3.如果Request cache开启,且该请求在缓存中有对应的响应,则直接返回该缓存响应;
4.熔断器是否打开,如果打开,则进入8,即getFallback;
5.如果熔断器未打开,则检查线程池(或信号量)是否可用(如果有队列则判断队列是否满,如果无队列则判断是否有空闲线程),如果不可用则进入8;
6.如果线程池(或信号量)可用,则执行用户逻辑(run或construct,如果使用线程池,则在线程池中执行),如果执行失败或超时,则进入8;
7统计环路(这里就是把用户请求/响应比作了电路环路)健康数据,包括请求超时、失败、成功、线程池不可用(或信号量)等数据,这些数据可以用作“熔断器”开关依据;
8.getFallback;
9如果执行正常,则返回成功响应。
熔断器
下图展示了HystrixCommand或HystrixObservableCommand与HystrixCircuitBreaker的交互过程:

熔断器有3个重要参数:
HystrixCommandProperties.metricsRollingStatisticalWindowInMilliseconds()指定滑动窗口统计周期;
HystrixCommandProperties.circuitBreakerRequestVolumeThreshold()指定在滑动窗口统计周期内的请求阈值;
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage()指定在滑动窗口统计周期内,请求数量达到阈值后,请求失败的百分比;
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds()指定熔断器开启时长,在该时长后会进行一次半开启测试(尝试让一个请求走主流程,如果成功则关闭熔断器,如果失败则重新计时)。
allowRequest会首先判断熔断器是否强制开启,如果未被强制开启,则判断熔断器是否被强制关闭,如果也未被强制关闭,则使用isOpen正常判断熔断器开关;
markSuccess和markFailure都会将结果计入window中bucket内,每一个bucket都会记录Success、Failure、timeout、rejection等数据,一个滑动窗口周期后就会新创建一个bucket,并丢弃最老的bucket。markSuccess表示请求成功,所以其还会尝试关闭熔断器(即如果熔断器开启,则关闭)。
隔离
Hystirx使用舱壁模式(bulkhead pattern)来隔离依赖,并限制了每个依赖的并发访问。Hystrix提供了两种舱壁模式的实现,一种是线程池,另一种是信号量。
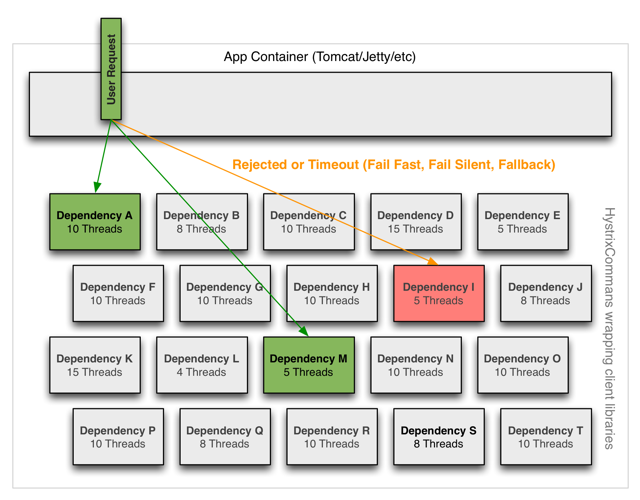
线程池方案由于提供了与应用线程相独立的线程池,可以使依赖相对独立的在应用中运行,其还可以提供超时、异步等操作。但其缺点也是很明显的,即由于需要提供额外的线程,而系统中过多的线程意味着频繁的上下文切换开销,性能方面就会受到影响,但在netflix提供的测试报告中,其性能损耗还是可以接受的:

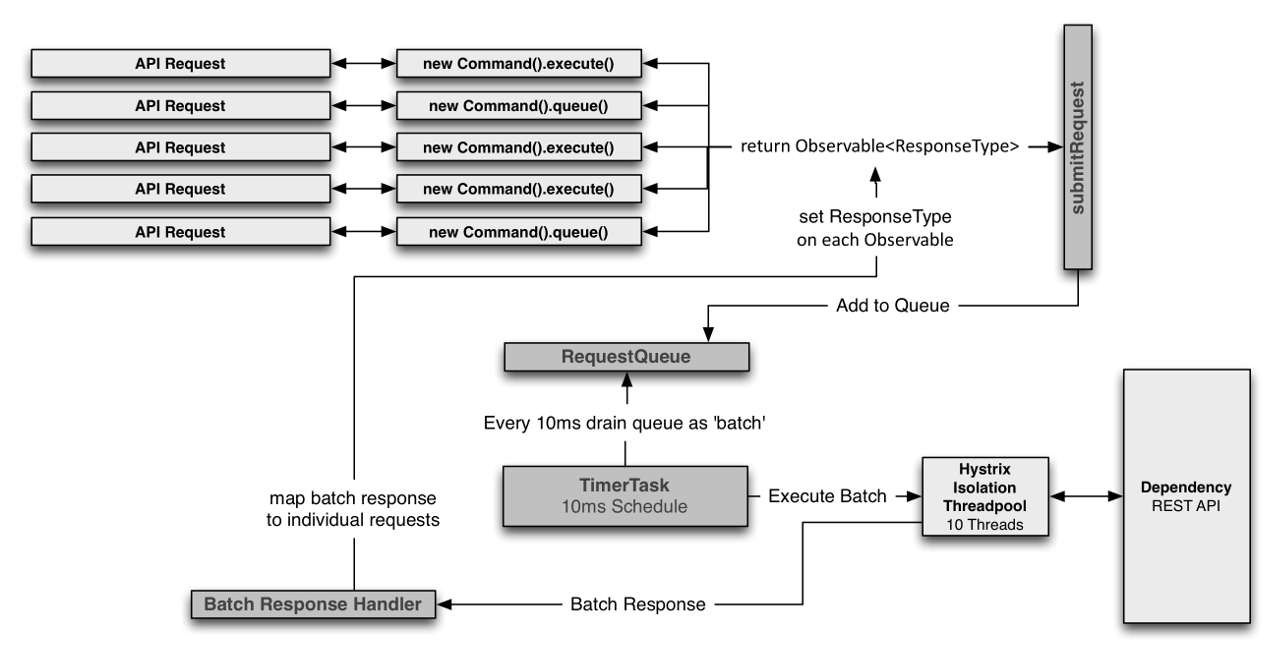
Request Collapsing(请求折叠)
Request Collapsing即将多个请求合并为一个请求来执行,这里的一个请求并非网络协议层面的一个请求,而是将原本在多个线程或多个连接中执行的请求,折叠成在一个线程或一个连接中执行的请求。
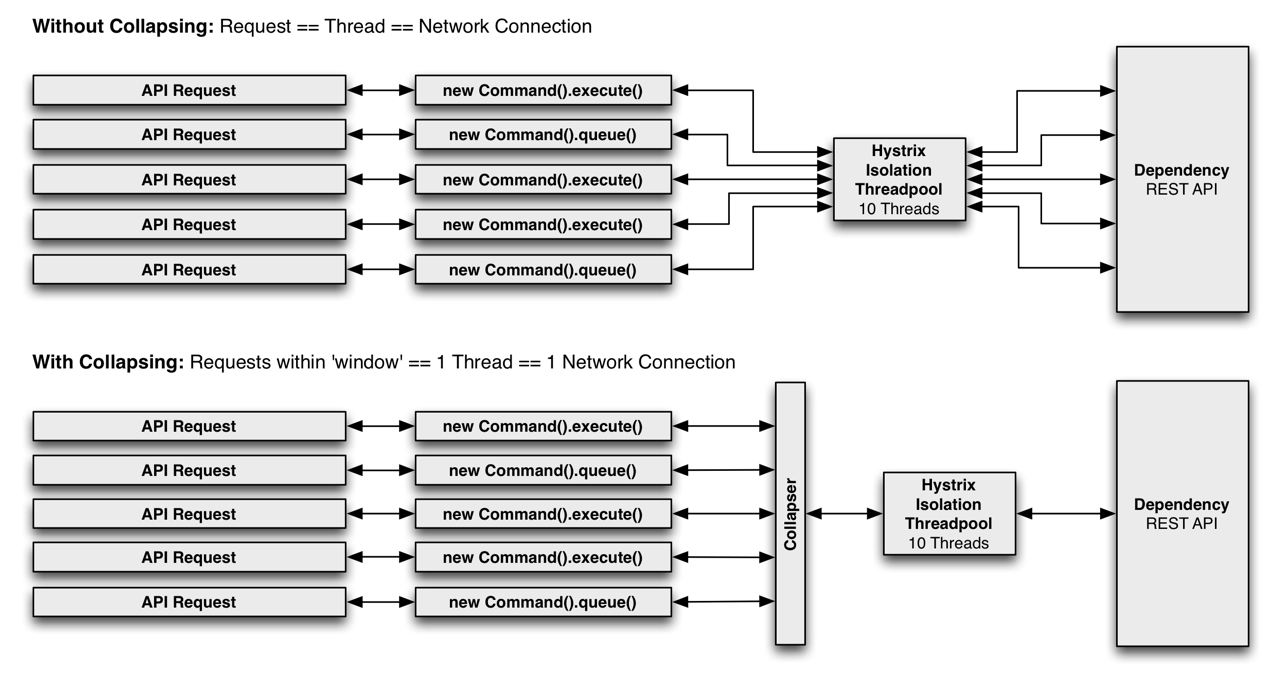
如应用提供一个查询用户信息的接口(根据id查询user),该接口会调用一个依赖服务,用户在请求该接口时,Hystrix可以先将其放入一个等待队列,有一个定时任务扫描该队列,每次扫描都会取出队列中的等待任务,并批量执行(在一个HystrixCommand中执行)。
HystrixCollapser提供了两个抽象方法:
HystrixCommand<List<User>> createCommand(Collection<CollapsedRequest<User, Long>> collapsedRequests),定时任务定时扫描等待队列,collapsedRequests就包含了扫描结果集合;
mapResponseToRequests(List<User> batchResponse, Collection<CollapsedRequest<User, Long>> collapsedRequests),当批量执行完成后,会返回一个批量响应(batchResponse),该方法就需要将批量响应映射到collapsedRequests中(collapsedRequest.setResponse(user))。
Request Caching(请求缓存)
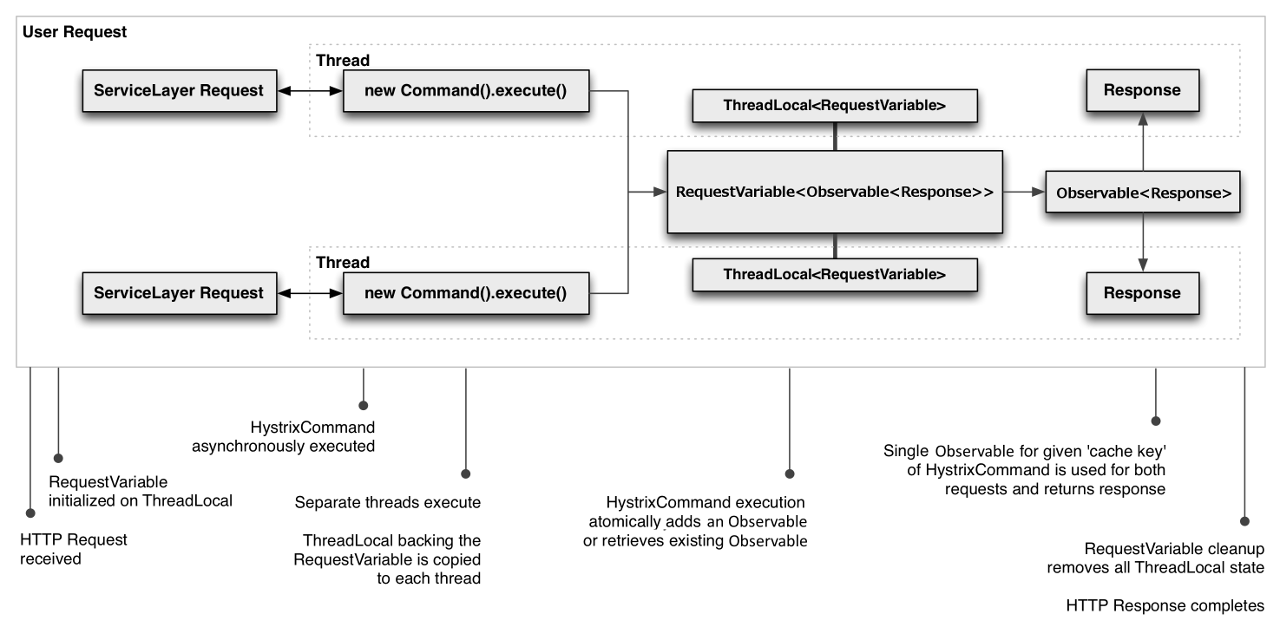
继承HystrixCommand或HystrixObservableCommand,覆盖getCacheKey()方法(默认返回null,表示关闭)可以开启缓存功能。Request Caching通常用于一个请求,而不适用于跨请求的情况。分析下图,可以看出Hystrix使用ThreadLocal实现了请求缓存,Hystrix应该维护着一个全局(static)map,map的key即为getCacheKey(),value为一个ThreadLocal。虽然缓存机制会在HystrixCommand线程执行前生效(总体流程3),但仍无法避免开发者自己在一个请求内使用多线程的情况。