为解决关系型数据库面对海量数据由于数据量过大而导致的性能问题时,将数据进行分片是行之有效的解决方案,而将集中于单一节点的数据拆分并分别存储到多个数据库或表,称为分库分表。
分库可以有效分散高并发量,分表虽然无法缓解并发量,但仅跨表仍然可以使用数据库原生的ACID事务。而一旦跨库,涉及到事务的问题就会变得无比复杂。
1.使用
pom.xml添加依赖:
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.0.0.M1</version>
</dependency>
基于Spring Boot的规则配置:
sharding.jdbc.datasource.names=ds_0,ds_1 sharding.jdbc.datasource.ds_0.type=org.apache.commons.dbcp.BasicDataSource sharding.jdbc.datasource.ds_0.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds_0.url=jdbc:mysql://localhost:3306/demo_ds_0 sharding.jdbc.datasource.ds_0.username=root sharding.jdbc.datasource.ds_0.password=hongda$123456 sharding.jdbc.datasource.ds_1.type=org.apache.commons.dbcp.BasicDataSource sharding.jdbc.datasource.ds_1.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds_1.url=jdbc:mysql://localhost:3306/demo_ds_1 sharding.jdbc.datasource.ds_1.username=root sharding.jdbc.datasource.ds_1.password=hongda$123456 sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds_$->{user_id % 2} sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds_$->{0..1}.t_order_$->{0..1} sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2} sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=order_id sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds_$->{0..1}.t_order_item_$->{0..1} sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item_$->{order_id % 2} sharding.jdbc.config.sharding.tables.t_order_item.key-generator-column-name=order_item_id
使用上来说的话,这样就可以了
上面的配置是根据user_id取模分库, 且根据order_id取模分表的两库两表的配置
总的来说,Sharding-jdbc是个非常轻量级的框架,使用并不困难。
其余框架的使用,可以查看官方提供的sharding-sphere-example测试案例
2.Sharding-jdbc分布式id:
在使用官方提供的测试案例使用时,发现一个问题,就是Sharding-jdbc生成的分布式id全是偶数
sharding-jdbc的分布式ID采用twitter开源的snowflake算法,不需要依赖任何第三方组件,这样其扩展性和维护性得到最大的简化;
但是snowflake算法的缺陷(强依赖时间,如果时钟回拨,就会生成重复的ID),sharding-jdbc没有给出解决方案,如果用户想要强化,需要自行扩展;
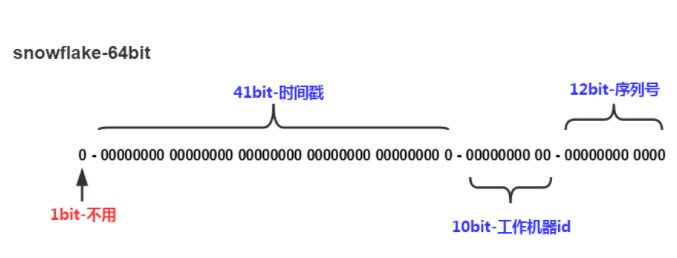
1 符号位 等于 0 41 时间戳 从 2016/11/01 零点开始的毫秒数,支持 2 ^41 /365/24/60/60/1000=69.7年 10 工作进程编号 支持 1024 个进程 12 序列号 每毫秒从 0 开始自增,支持 4096 个编号
Sharding-jdbc分布式id核心源码:
public final class DefaultKeyGenerator implements KeyGenerator { public static final long EPOCH; // 自增长序列的长度(单位是位时的长度) private static final long SEQUENCE_BITS = 12L; // workerId的长度(单位是位时的长度) private static final long WORKER_ID_BITS = 10L; private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1; private static final long WORKER_ID_LEFT_SHIFT_BITS = SEQUENCE_BITS; private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS + WORKER_ID_BITS; // 位运算计算workerId的最大值(workerId占10位,那么1向左移10位就是workerId的最大值) private static final long WORKER_ID_MAX_VALUE = 1L << WORKER_ID_BITS; @Setter private static TimeService timeService = new TimeService(); private static long workerId; // EPOCH就是起始时间,从2016-11-01 00:00:00开始的毫秒数 static { Calendar calendar = Calendar.getInstance(); calendar.set(2016, Calendar.NOVEMBER, 1); calendar.set(Calendar.HOUR_OF_DAY, 0); calendar.set(Calendar.MINUTE, 0); calendar.set(Calendar.SECOND, 0); calendar.set(Calendar.MILLISECOND, 0); EPOCH = calendar.getTimeInMillis(); } private long sequence; private long lastTime; /** * 得到分布式唯一ID需要先设置workerId,workId的值范围[0, 1024) * @param workerId work process id */ public static void setWorkerId(final long workerId) { // google-guava提供的入参检查方法:workerId只能在0~WORKER_ID_MAX_VALUE之间; Preconditions.checkArgument(workerId >= 0L && workerId < WORKER_ID_MAX_VALUE); DefaultKeyGenerator.workerId = workerId; } /** * 调用该方法,得到分布式唯一ID * @return key type is @{@link Long}. */ @Override public synchronized Number generateKey() { long currentMillis = timeService.getCurrentMillis(); // 每次取分布式唯一ID的时间不能少于上一次取时的时间 Preconditions.checkState(lastTime <= currentMillis, "Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastTime, currentMillis); // 如果同一毫秒范围内,那么自增,否则从0开始 if (lastTime == currentMillis) { // 如果自增后的sequence值超过4096,那么等待直到下一个毫秒 if (0L == (sequence = ++sequence & SEQUENCE_MASK)) { currentMillis = waitUntilNextTime(currentMillis); } } else { sequence = 0; } // 更新lastTime的值,即最后一次获取分布式唯一ID的时间 lastTime = currentMillis; // 从这里可知分布式唯一ID的组成部分; return ((currentMillis - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (workerId << WORKER_ID_LEFT_SHIFT_BITS) | sequence; } // 获取下一毫秒的方法:死循环获取当前毫秒与lastTime比较,直到大于lastTime的值; private long waitUntilNextTime(final long lastTime) { long time = timeService.getCurrentMillis(); while (time <= lastTime) { time = timeService.getCurrentMillis(); } return time; } }
EPOCH = calendar.getTimeInMillis(); 计算 2016/11/01 零点开始的毫秒数。
#generateKey() 实现逻辑
校验当前时间小于等于最后生成编号时间戳,避免服务器时钟同步,可能产生时间回退,导致产生重复编号
获得序列号。当前时间戳可获得自增量到达最大值时,调用 #waitUntilNextTime() 获得下一毫秒
设置最后生成编号时间戳,用于校验时间回退情况
位操作生成编号
根据代码可以得出,如果一个毫秒内只产生一个id,那么12位序列号全是0,所以这种情况生成的id全是偶数。
3.怎么解决工作进程编号分配?
Twitter Snowflake 算法实现上是相对简单易懂的,较为麻烦的是怎么解决工作进程编号的分配?
超过 1024 个怎么办? 怎么保证全局唯一?
第一个问题,将分布式主键生成独立成一个发号器服务,提供生成分布式编号的功能。
第二个问题,通过 Zookeeper、Consul、Etcd 等提供分布式配置功能的中间件。当然 Sharding-JDBC 也提供了不依赖这些服务的方式,我们一个一个往下看。
获取workerId的三种方式
sharding-jdbc的sharding-jdbc-plugin模块中,提供了三种方式获取workerId的方式,并提供接口获取分布式唯一ID的方法–generateKey(),接下来对各种方式如何生成workerId进行分析;
HostNameKeyGenerator
根据hostname获取,源码如下(HostNameKeyGenerator.java):
/** * 根据机器名最后的数字编号获取工作进程Id.如果线上机器命名有统一规范,建议使用此种方式. * 例如机器的HostName为:dangdang-db-sharding-dev-01(公司名-部门名-服务名-环境名-编号) * ,会截取HostName最后的编号01作为workerId. * * @author DonneyYoung **/ static void initWorkerId() { InetAddress address; Long workerId; try { address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!"); } // 先得到服务器的hostname,例如JTCRTVDRA44,linux上可通过命令"cat /proc/sys/kernel/hostname"查看; String hostName = address.getHostName(); try { // 计算workerId的方式: // 第一步hostName.replaceAll("\d+$", ""),即去掉hostname后纯数字部分,例如JTCRTVDRA44去掉后就是JTCRTVDRA // 第二步hostName.replace(第一步的结果, ""),即将原hostname的非数字部分去掉,得到纯数字部分,就是workerId workerId = Long.valueOf(hostName.replace(hostName.replaceAll("\d+$", ""), "")); } catch (final NumberFormatException e) { throw new IllegalArgumentException(String.format("Wrong hostname:%s, hostname must be end with number!", hostName)); } DefaultKeyGenerator.setWorkerId(workerId); }
IPKeyGenerator
根据ip获取:
/** * 根据机器IP获取工作进程Id,如果线上机器的IP二进制表示的最后10位不重复,建议使用此种方式 * ,列如机器的IP为192.168.1.108,二进制表示:11000000 10101000 00000001 01101100 * ,截取最后10位 01 01101100,转为十进制364,设置workerId为364. */ static void initWorkerId() { InetAddress address; try { // 首先得到IP地址,例如192.168.1.108 address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!"); } // IP地址byte[]数组形式,这个byte数组的长度是4,数组0~3下标对应的值分别是192,168,1,108 byte[] ipAddressByteArray = address.getAddress(); // 由这里计算workerId源码可知,workId由两部分组成: // 第一部分(ipAddressByteArray[ipAddressByteArray.length - 2] & 0B11) << Byte.SIZE:ipAddressByteArray[ipAddressByteArray.length - 2]即取byte[]倒数第二个值,即1,然后&0B11,即只取最后2位(IP段倒数第二个段取2位,IP段最后一位取全部8位,总计10位),然后左移Byte.SIZE,即左移8位(因为这一部分取得的是IP段中倒数第二个段的值); // 第二部分(ipAddressByteArray[ipAddressByteArray.length - 1] & 0xFF):ipAddressByteArray[ipAddressByteArray.length - 1]即取byte[]最后一位,即108,然后&0xFF,即通过位运算将byte转为int; // 最后将第一部分得到的值加上第二部分得到的值就是最终的workId DefaultKeyGenerator.setWorkerId((long) (((ipAddressByteArray[ipAddressByteArray.length - 2] & 0B11) << Byte.SIZE) + (ipAddressByteArray[ipAddressByteArray.length - 1] & 0xFF))); }
IPSectionKeyGenerator
根据 ip段获取:
/** * 浏览 {@link IPKeyGenerator} workerId生成的规则后,感觉对服务器IP后10位(特别是IPV6)数值比较约束. * * <p> * 有以下优化思路: * 因为workerId最大限制是2^10,我们生成的workerId只要满足小于最大workerId即可。 * 1.针对IPV4: * ....IP最大 255.255.255.255。而(255+255+255+255) < 1024。 * ....因此采用IP段数值相加即可生成唯一的workerId,不受IP位限制。 * 2.针对IPV6: * ....IP最大ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff * ....为了保证相加生成出的workerId < 1024,思路是将每个bit位的后6位相加。这样在一定程度上也可以满足workerId不重复的问题。 * </p> * 使用这种IP生成workerId的方法,必须保证IP段相加不能重复 * * @author DogFc */ static void initWorkerId() { InetAddress address; try { address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!"); } // 得到IP地址的byte[]形式值 byte[] ipAddressByteArray = address.getAddress(); long workerId = 0L; //如果是IPV4,计算方式是遍历byte[],然后把每个IP段数值相加得到的结果就是workerId if (ipAddressByteArray.length == 4) { for (byte byteNum : ipAddressByteArray) { workerId += byteNum & 0xFF; } //如果是IPV6,计算方式是遍历byte[],然后把每个IP段后6位(& 0B111111 就是得到后6位)数值相加得到的结果就是workerId } else if (ipAddressByteArray.length == 16) { for (byte byteNum : ipAddressByteArray) { workerId += byteNum & 0B111111; } } else { throw new IllegalStateException("Bad LocalHost InetAddress, please check your network!"); } DefaultKeyGenerator.setWorkerId(workerId); }
参考:
http://shardingsphere.io/document/current/cn/overview/
https://blog.csdn.net/tianyaleixiaowu/article/details/70242971
https://blog.csdn.net/clypm/article/details/54378502