这篇文章里我们将要讨论一般的实现散列思想最重要的技术——散列函数的设计,这里会讨论一些常见的散列函数。但他们自存在之初就有一个固有的缺陷:无法杜绝的冲突,更糟糕的是从理论上讲这一缺陷无法根本地消除。所以在下一篇将深入讨论解决冲突的策略。
我们知道散列函数是一个映射,功能是将词条空间中的元素映射到散列表地址空间。而在通常的情况下,词条数目远远大于散列表空间,因此可能多个词条被映射到同一个地址上(鸽巢原理),这就绝不可能是一个单射。但我们要在把握规律的基础上发挥人的主观能动性,去做一个近似单射,这方面还是大有可为的。
为此我们需要做两件事 这也是实现散列的两项基本任务
- (震前预警)首先我们需要精心的设计散列表及其对应的散列函数,消除掉一些能够导致冲突的先天性因素,从而尽可能的压低日后发生冲突的概率,这也是本篇讨论的主题。
2. (灾后措施)既然无论如何都不可能从根本上消除冲突,所以我们也应该在事先准备好充分的预案,日后一旦发生冲突,我们就可照此预案及时予以排解,这是下一篇的事。
我们首先要界定一个标准:如何判断一个散列函数足够“好”?
- 确定性:同一个值总被映射到同一地址
- 快速:最好是O(1)
- 满射:尽可能充分覆盖整个散列空间
- 均匀:为了充分利用散列空间和降低冲突,要使映射到各个位置的概率接近。避免很多元素扎堆聚集的现象。
再说一些共识:如果输入的关键字是整数,一般合理的方法就是直接返回key%TableSize。通常关键字是字符串,这种情形下,散列函数就要仔细的选择。
下面就按照这些标准,介绍常用的散列函数,分析优劣并讨论适用场合。分为两大类,分别针对数值型和字符串型关键字的处理。
数值型处理方式
1.整数留余
Hash(key)=key%M,M通常是散列表规模。但有时候关键字碰巧具有某些不理想的性质,比如说啊,TableSize=10,而key都以0为个位,那这就凉了,全都扎堆到0那个地址了,到时候想取某一个数,结果拔出萝卜带出泥。好的办法通常是保证表的大小是素数,这时不仅数据对散列表的覆盖程度能够达到最充分,而且在散列表中的分布也将达到最均匀,这里借鉴了蝉的哲学。(数学证明就不上了吧,估计你们也不乐意看)
Index remainder(int key,int size){ return key%size; }
2.MAD(余数法的改进)
因为余数法还有缺陷,体现在两个方面。首先它存在不动点,总有hash(0)=0,这和均匀概率是相悖的。然后他是零阶均匀的,[0,R)的关键字虽然整体是均匀的,但是相邻的关键字一定会被散列到相邻的地址上。从这个意义上讲,余数法的均匀性是低阶的,我们更希望实现高阶的均匀,比如一阶均匀:临近的关键字被散列后地址不再相近,这就是MAD的任务了。
除了表长继续取做素数,我们还需要另外两个整数,整个散列的计算过程包括三步
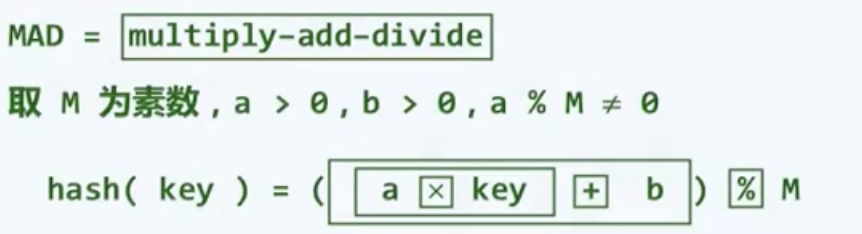
b可以视作偏移量,这就消除了不动点,a则扮演了步长,在经过散列变换之后,原本相邻的关键字将变成间隔为a,从而不再继续相邻。比如这样

实际上在不同的场合,散列的原则都有可能发生变换甚至反转。比如,在某些特殊的场合
未必需要高阶的乃至通常的均匀性,比如在一些几何计算的场合,需要处理的往往是来自于高维空间中的一系列点,为了将它们压缩到更加低维的空间,往往也需要借助散列。此时对散列的要求可能恰恰相反——也就是要尽可能使得临近的关键码被映射到临近的位置。
散列技术在当今的信息处理中之所以能够无处不在,恰恰在于它的这些准则是灵活的。再比如在我们这个课程中所讨论的主要技术多是旨在将一个相对而言更大的空间,通过散列映射 压缩至一个相对而言更小的空间,而实际上反过来也是大有用处的,这也就是所谓的密码学。
散列函数是一个庞大的家族,其中的成员形形色色,各有所长,这也是散列技术的趣味性和魅力所在,下面继续讨论更多的典型函数。
3.平方取中法
首先算出key2,截取中间若干数位作为地址,比如hash(123)=512,因为1232=15129,取中间三位。那为什么要倾向于保留居中的数位呢,这正是为了使得构成原关键码的各个数位,能够对最终的散列地址有尽可能接近的影响。

看这张图,它将一个数的平方运算分解为一系列的左移操作以及若干次加法(快速幂),底部是最终结果。
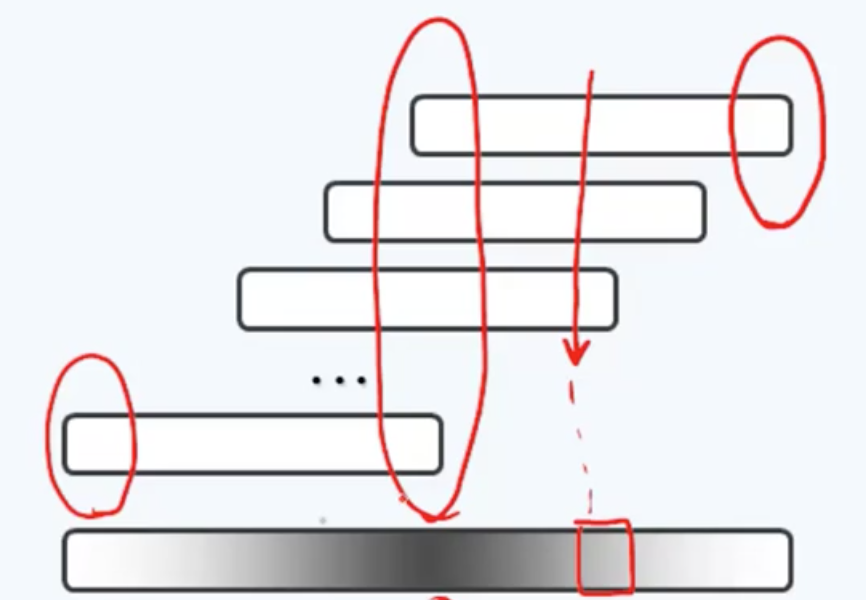
如果忽略进位,每一个数位都是由原关键码中的若干数位经求和得到的。因此两侧的数位是由更少的原数位累积而得,而越是居中的数位,则是由更多的原数位累积而得。因此截取居中的若干位,可以使得原关键码的各数位对最终地址的影响更大,扰动更多,彼此更为接近。
4.伪随机数
计算公式是Rand(x+1)=[ a* rand(x) ]%M,可以看到这里每一个所谓的随机数,实际上都是在前一个所谓随机数基础上,按照确定的计算规则递推而得的。因此更为准确的应该称之为 伪随机数发生器,就逻辑效果而言,这等同于将取值范围以内的所有整数按照这种规则,重新编排为一个貌似随机实则确定的序列,而这个发生器所返回的,只不过是在这个序列中对应于某个特定秩的那个元素。比如一种最常见的方法就是将这个秩取做系统当前的时间,就是测试数据时咱们经常写的那个srand(time(NULL))。
对散列函数以及伪随机数发生器函数做一对比,我们就会发现,二者惊人的相似。只不过前者是经统一散列转换之后所得的关键码,而后者只是伪随机数序列中的某个秩。因此我们不妨直接借助后者来实现前者:
![]()
有趣的是,如果反过来考察此前我们已经确立的那4条准则,无论是确定性、高效性、满射性还是均匀性——它们恰好同时也是评判随机数发生器的重要标准。这简直是天助我也,既然每一个伪随机数发生器都可视作为一个散列函数,我们也可以将散列函数的设计难题转交给伪随机数发生器的设计者(甩锅大法好2333),直接套用它们的工作成果。
但是这样做有一个缺点,难以移植。在不同的平台和环境中,提供的伪随机数发生器所采用的算法不尽相同,即便在同一个平台环境中 不同的历史版本也可能对应于不同的随机数发生算法。因此,我们在特定时间特定平台上所生成的散列表未必可以直接移植到其他的平台。所以这个慎用。而由于随机数算法各有不同,这里就不再给出代码实现了。
字符串型处理方式
进入散列函数的关键字还可能是其他类型的变量,所以要做一个预处理,转化为整数,转化后的被称为hashcode,然后再将其映射到不同的地址。在上面的“共识”里说过,遇到字符串就要格外小心,下面我们重点讨论这种情况。
一种选择方法是把字符串中字符的ASCII码值加起来。
Index TrivialHash(const char* Key,int size){// a simple hash function unsigned int val=0; while (*Key !='�') { val+=*Key++; } return val%size; }
这种方法实现简单,而且能快速算出答案。但是如果表很大,他就无法很好地分配关键字了。如果TableSize=10007(prime),假设所有的关键字最多8个字符。由于char最多127,所以散列函数只能取值0~1016之间,显然这不均匀。
另一种方法是这样:
Index BadHashEx(const char* Key,int size){ return (Key[0]+27*Key[1]+720*Key[2])%size; //easy to collision }
这个函数假设key至少有2个字符和NULL结尾,27表示字母表个数+空格,而729=272。该函数只考虑前三个字符,但只要他们是随机的,而表的大小还是10007,那就会得到一个合理的均匀地址分配。然!而!英文不是随机的……虽然三个字符有26^3=17576种可能,但查验词汇量足够大的联机辞典却揭示:3个字母的实际组合数只有2851个。即使这些组合没有冲突,也不过只有表的28%被真正填充到,因此虽然很容易计算,但会造成巨大浪费,所以当散列表足够大的时候这个函数还是不适合的。
下面给出第三种尝试:
Index greatHash(const char* Key,int size){ unsigned int val=2; while (*Key!='�') val=(val<<5)+ *Key++; return val%size; }
这个散列函数涉及到关键字中的所有字符,并且一般可以分布的很好(它计算$sum_{i=0}^{KeySize-1}Key[KeySize-i-1]*32^i$,并将结果限制在适当的范围内)。程序根据Horner法则计算一个32位的多项式函数。例如计算hk=k1+27*k2+272*k3的另外一种方式是借助于公式
Hk=((k3*27+k2)*27+k2)完成,Horner法则将其扩展到用于n次多项式。
之所以用32代替27,是因为可以用移位操作加速,而加法可以用按位异或来代替。
看起来很完美了吧,但!是!
上面的函数就分布而言未必是最好的,但确实有其优点。如果关键字很长,就会在计算上话费过渡时间。不仅如此,前面的字符还会左移出最终的结果。所以通常做法是不使用所有的字符,有些设计人员只使用奇数位置上的字符来实现这个函数。这里有这样一层想法:用计算省下来的时间来补偿由此产生的对均匀分布函数的轻微干扰。总之,需要权衡,因为现实中处处充满了各种不理想的性质,没有理论上那么美好。
剩下的主要编程细节是解决冲突的消除问题。如果当一个元素被插入时另一个元素已经占据了这个地址,那么就产生了冲突。解决方法有几种,我们讨论最简单的两种:分离链接法(Separate chaining)和开放定址法(Open addressing hashing)
下篇文章见,诸君。
ps.转载请注明文章来源