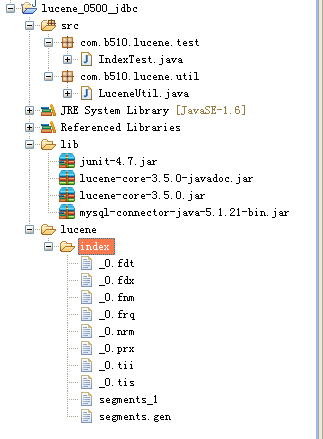
项目结构:
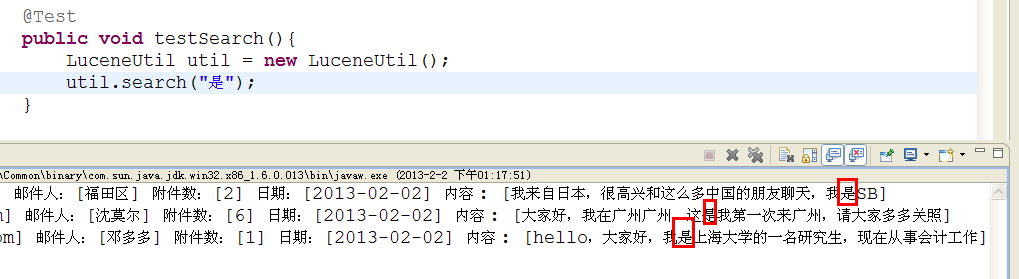
运行效果:
1.搜索关键字"是"
2.搜索关键字"我"

==========================================
数据库中表信息:
1 CREATE TABLE `mymails` ( 2 `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号', 3 `name` varchar(50) DEFAULT NULL COMMENT '寄件人', 4 `email` varchar(50) DEFAULT NULL COMMENT '件邮名称', 5 `content` varchar(200) DEFAULT NULL COMMENT '内容', 6 `attach` int(11) DEFAULT NULL COMMENT '附件数', 7 `sendtime` varchar(20) DEFAULT NULL COMMENT '发送日期', 8 PRIMARY KEY (`id`) 9 ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
==========================================
代码部分:
==========================================
/lucene_0500_jdbc/src/com/b510/lucene/util/LuceneUtil.java
1 /** 2 * 3 */ 4 package com.b510.lucene.util; 5 6 import java.io.File; 7 import java.io.IOException; 8 import java.sql.Connection; 9 import java.sql.DriverManager; 10 import java.sql.PreparedStatement; 11 import java.sql.ResultSet; 12 import java.sql.SQLException; 13 import java.util.HashMap; 14 import java.util.Map; 15 16 import org.apache.lucene.analysis.standard.StandardAnalyzer; 17 import org.apache.lucene.document.Document; 18 import org.apache.lucene.document.Field; 19 import org.apache.lucene.document.NumericField; 20 import org.apache.lucene.index.CorruptIndexException; 21 import org.apache.lucene.index.IndexReader; 22 import org.apache.lucene.index.IndexWriter; 23 import org.apache.lucene.index.IndexWriterConfig; 24 import org.apache.lucene.index.Term; 25 import org.apache.lucene.search.IndexSearcher; 26 import org.apache.lucene.search.ScoreDoc; 27 import org.apache.lucene.search.TermQuery; 28 import org.apache.lucene.search.TopDocs; 29 import org.apache.lucene.store.Directory; 30 import org.apache.lucene.store.FSDirectory; 31 import org.apache.lucene.store.LockObtainFailedException; 32 import org.apache.lucene.util.Version; 33 34 /** 35 * @author Hongten <br /> 36 * @date 2013-1-31 37 */ 38 public class LuceneUtil { 39 40 private static String driver = "com.mysql.jdbc.Driver"; 41 private static String dbName = "db_lucene"; 42 private static String passwrod = "root"; 43 private static String userName = "root"; 44 private static String url = "jdbc:mysql://localhost:3308/" + dbName; 45 46 private Directory directory = null; 47 /** 48 * 评分 49 */ 50 private Map<String, Float> scores = new HashMap<String, Float>(); 51 52 public LuceneUtil() { 53 try { 54 scores.put("sina.com", 1.0f); 55 scores.put("foxmail.com", 1.1f); 56 directory = FSDirectory.open(new File("D:/WordPlace/lucene/lucene_0500_jdbc/lucene/index")); 57 } catch (IOException e) { 58 e.printStackTrace(); 59 } 60 } 61 62 /** 63 * 创建索引 64 */ 65 public void index() { 66 IndexWriter writer = null; 67 try { 68 writer = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); 69 // 删除之前所建立的全部索引 70 writer.deleteAll(); 71 // 创建文档 72 Document document = null; 73 74 String sql = "select * from mymails"; 75 ResultSet rs = null; 76 try { 77 Class.forName(driver); 78 Connection conn = DriverManager.getConnection(url, userName, passwrod); 79 PreparedStatement ps = conn.prepareStatement(sql); 80 rs = ps.executeQuery(); 81 82 while (rs.next()) { 83 System.out.println("id:[" + rs.getString("id") + "] name:[" + rs.getString("name") + "] content:[" + rs.getString("content") + "]"); 84 85 document = new Document(); 86 document.add(new Field("id", rs.getString("id"), Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS)); 87 document.add(new Field("email", rs.getString("email"), Field.Store.YES, Field.Index.NOT_ANALYZED)); 88 document.add(new Field("content", rs.getString("content"), Field.Store.YES, Field.Index.ANALYZED)); 89 document.add(new Field("name", rs.getString("name"), Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS)); 90 document.add(new NumericField("attach", Field.Store.YES, true).setIntValue(Integer.valueOf(rs.getString("attach")))); 91 document.add(new Field("date", rs.getString("sendtime"), Field.Store.YES, Field.Index.ANALYZED)); 92 93 // 这里进行加权处理 94 String et = rs.getString("email").substring(rs.getString("email").lastIndexOf("@") + 1); 95 System.out.println(et); 96 if (scores.containsKey(et)) { 97 document.setBoost(scores.get(et)); 98 } else { 99 document.setBoost(0.6f); 100 } 101 writer.addDocument(document); 102 103 } 104 105 // 关闭记录集 106 if (rs != null) { 107 try { 108 rs.close(); 109 } catch (SQLException e) { 110 e.printStackTrace(); 111 } 112 } 113 114 // 关闭声明 115 if (ps != null) { 116 try { 117 ps.close(); 118 } catch (SQLException e) { 119 e.printStackTrace(); 120 } 121 } 122 123 // 关闭链接对象 124 if (conn != null) { 125 try { 126 conn.close(); 127 } catch (SQLException e) { 128 e.printStackTrace(); 129 } 130 } 131 132 } catch (Exception e) { 133 e.printStackTrace(); 134 } 135 136 } catch (CorruptIndexException e) { 137 e.printStackTrace(); 138 } catch (LockObtainFailedException e) { 139 e.printStackTrace(); 140 } catch (IOException e) { 141 e.printStackTrace(); 142 } finally { 143 if (writer != null) { 144 try { 145 writer.close(); 146 } catch (CorruptIndexException e) { 147 e.printStackTrace(); 148 } catch (IOException e) { 149 e.printStackTrace(); 150 } 151 } 152 } 153 } 154 155 /** 156 * 搜索 157 */ 158 public void search(String key) { 159 try { 160 IndexReader reader = IndexReader.open(directory); 161 IndexSearcher searcher = new IndexSearcher(reader); 162 TermQuery query = new TermQuery(new Term("content", key)); 163 TopDocs tds = searcher.search(query, 12); 164 for (ScoreDoc sd : tds.scoreDocs) { 165 Document doc = searcher.doc(sd.doc); 166 System.out.println("文档序号:[" + sd.doc + "] 得分:[" + sd.score + "] 邮件名称:[" + doc.get("email") + "] 邮件人:[" + doc.get("name") + "] 附件数:[" + doc.get("attach") + "] 日期:[" + doc.get("date") 167 + "] 内容 : [" + doc.get("content") + "]"); 168 } 169 } catch (CorruptIndexException e) { 170 e.printStackTrace(); 171 } catch (IOException e) { 172 e.printStackTrace(); 173 } 174 } 175 }
/lucene_0500_jdbc/src/com/b510/lucene/test/IndexTest.java
1 /** 2 * 3 */ 4 package com.b510.lucene.test; 5 6 import org.junit.Test; 7 8 import com.b510.lucene.util.LuceneUtil; 9 10 /** 11 * @author Hongten <br /> 12 * @date 2013-1-31 13 */ 14 public class IndexTest { 15 16 @Test 17 public void testIndex(){ 18 LuceneUtil util = new LuceneUtil(); 19 util.index(); 20 } 21 22 @Test 23 public void testSearch(){ 24 LuceneUtil util = new LuceneUtil(); 25 util.search("我"); 26 } 27 28 }
I'm Hongten