每年电商双11大促对阿里技术人都是一次大考,对阿里数据库团队更是如此。经过9年的发展,双11单日交易额从2009年的0.5亿一路攀升到2017年的1682亿,秒级交易创建峰值达到了32.5万笔/秒。支撑这一切业务指标的背后,是底层技术体系的一次次迭代升级。

阿里巴巴数据库系统经历了10多年的发展,今年正式确定从 第三代大规模分库分表 向 第四代X-DB分布式数据库系统 演进的目标。X-DB分布式数据库的落地已经在2017年双11大促中获得了可行性验证,同时底层开始引入存储计算分离架构。分布式在系统稳定性、容灾能力、容量扩展性、技术体系内聚性上有了质的提升,今年双11开启了阿里数据库技术架构新的篇章。

本文以阿里电商交易链路中的核心系统库存中心为例,一窥阿里集团数据数据库的发展历程。库存中心数据库集群(简称库存DB集群),从2012年独立拆分后,其发展可以概括为以下3个阶段:
- 2012~2013年:分库分表水平拆分,构建大规模数据库集群
- 2014~2016年:单元化异地多活架构,数据多单元间同步
- 2017年:X-DB 1.0分布式集群部署上线,新的起点
作为阿里数据库体系中的核心系统,库存DB集群的发展历程可以作为缩影,代表了阿里巴巴数据库体系的演进。
诞生
库存DB集群诞生于2012年,是业务垂直拆分的产物。库存最早是商品中心数据库的一个字段,随着淘宝业务的复杂化,单一字段已经满足不了基于后端仓储的库存管理体系,所以便有了垂直拆分出来的库存DB集群。
水平拆分
2012~2017年,双11交易额一步步的刷新纪录,库存DB集群的QPS/TPS也实现了几十倍的增长。水平拆分的基本思路是把数据库扩展到多个物理节点上,让每个节点处理不同的读写请求,从而缓解单一数据库的性能问题。
借助于数据库团队的DTS(Data Transmission Service)产品,库存中心进行了大规模的水平拆分,分库和分表数量扩展到最初的几百倍,平稳的支撑了这一个阶段业务的快速发展。与此同时,在热点商品扣减、防超卖数据强一致需求、跨城异地容灾数据质量问题、业务数据量急剧膨胀、超大规模数据库集群运维等问题点上,迫切需要新一代架构来解决。
异地多活单元化
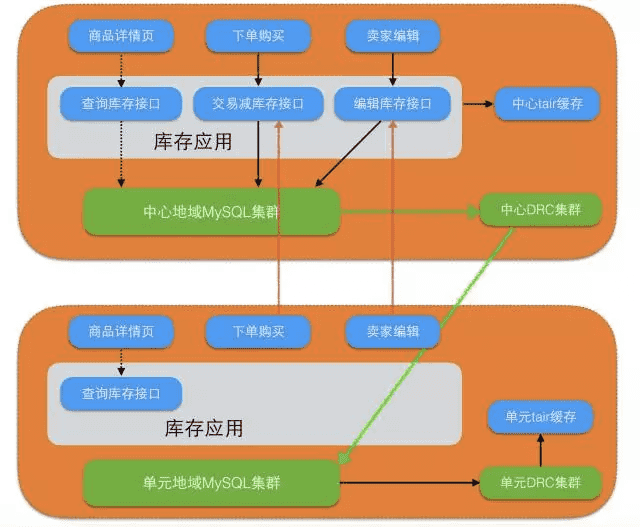
2014~2015年,为了进一步提升用户的购物体验,库存DB集群与主站交易链路一同做了单元化部署。单元化很大程度上解决了买家的使用体验问题,在本单元内封闭完成读写操作。但是对于卖家维度的数据,比如编辑商品、扣减库存,就会涉及到跨单元中心去写。关于单元化架构,之前已经有了很多介绍。
有了多个单元,对于底层数据库来说,面临的最大挑战就是数据同步,因为对于单元封闭的买家维度的数据,需要把单元的数据全部同步到中心;对于读写分离类型的业务,我们要把中心的数据同步到单元。这条数据通道就是依靠DRC(Data Replication Center)来完成。
如今,DRC不仅成为集团单元化链路的基础设施,对应的云产品DTS已经从2016年开始让阿里云用户、聚石塔商家低成本的搭建异地容灾。单元化架构给库存DB集群带来的最大挑战是多单元间的数据强一致问题,我们也为此做了很大的努力。
X-DB分布式集群
2017年双11,库存DB集群第一次使用X-DB 1.0分布式集群部署,平稳的支持了32.5万笔/秒的交易创建峰值。X-DB是阿里巴巴自研高性能分布式可全球化部署数据库,其核心技术目标概括为以下6点:
- 100%兼容MySQL生态,应用无缝迁移
- 跨AZ、Region的全球化部署能力,5个9以上的可用率
- 自动化的数据Sharding,计算、存储均可水平扩展
- 高性能的事务处理,相同硬件下达到MySQL 10倍的事务处理能力,百万TPS
- 自动化的数据冷热分离,存储成本为MySQL的1/10
- 计算存储分离,存储按需扩展
库存DB集群双十一部署架构:
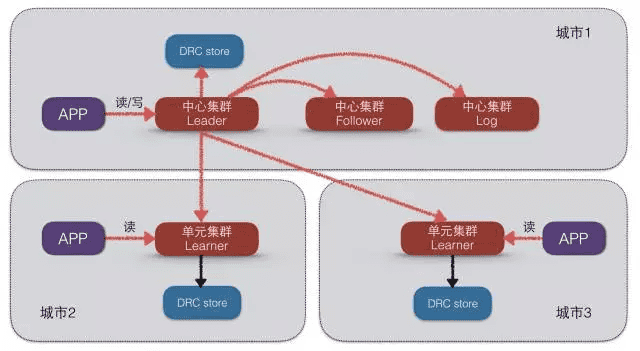
正是由于X-DB提供了全面兼容MySQL、高性能、低成本、跨城容灾、数据强一致的能力。在2017年年初,数据库团队和业务研发团队确定了在库存中心部署X-DB 1.0的目标,解决业务目前面临的痛点:
- 全面兼容MySQL,实现业务系统平滑迁入
- 极致性能,双11单实例热点扣减峰值TPS是去年的3倍
- 低成本,相比于传统的单元化主备架构部署,减少2个数据副本以及单元间数据同步资源成本
- 跨城容灾,借助Batching和Pipelining技术实现跨城强同步场景吞吐量几乎无衰减
- 数据强一致,借助Paxos协议提供多单元间数据强一致能力;批量关闭中心集群全部实例,集群30秒内完成单元选主切换,数据零丢失
- 计算存储分离,彻底解决传统机型计算资源和存储资源固定配比问题,搭配容器化技术,大促峰值期间将数据库弹性部署运行在离线任务主机,落地零扩容成本支持双十一大促
X-DB首次亮相在2017年双11的舞台,平稳支撑零点峰值32.5万笔/秒,开启了阿里数据库体系从分库分表时代向分布式集群时代的大门。技术之路永无止境,我们今天的技术现状离业务对我们的要求还有很大的差距。但是千里之行,始于足下,借用《魔戒》里的经典台词:“There’s some good in this world, Mr. Frodo. And it’s worth fighting for.”