Elasticsearch怎么诞生的?
(1)思考:大规模数据如何检索?
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
1)用什么数据库好?(mysql、sybase、oracle、达梦、神通、mongodb、hbase…)
2)如何解决单点故障;(lvs、F5、A10、Zookeep、MQ)
3)如何保证数据安全性;(热备、冷备、异地多活)
4)如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5)如何解决统计分析问题;(离线、近实时)
(2)传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈:
解决要点:
1)通过主从备份解决数据安全性问题;
2)通过数据库代理中间件心跳监测,解决单点故障问题;
3)通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果
(3)非关系型数据库的解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
解决要点:
1)通过副本备份保证数据安全性;
2)通过节点竞选机制解决单点问题;
3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
1、存储数据时按有序存储;
2、将数据和索引分离;
3、压缩数据;
这就引出了Elasticsearch。
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎, 可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch的核心:集群、节点、分片、副本、全文检索
ElasticSearch的使用案例:
- 你经营一个网上商店,你允许你的顾客搜索你卖的产品。在这种情况下,您可以使用Elasticsearch来存储整个产品目录和库存,并为它们提供搜索和自动完成建议。
- 你希望收集日志或事务数据,并希望分析和挖掘这些数据,以查找趋势、统计、汇总或异常。在这种情况下,你可以使用loghide (Elasticsearch/ loghide /Kibana堆栈的一部分)来收集、聚合和解析数据,然后让loghide将这些数据输入到Elasticsearch中。一旦数据在Elasticsearch中,你就可以运行搜索和聚合来挖掘你感兴趣的任何信息。
- 你运行一个价格警报平台,允许精通价格的客户指定如下规则:“我有兴趣购买特定的电子设备,如果下个月任何供应商的产品价格低于X美元,我希望得到通知”。在这种情况下,你可以抓取供应商的价格,将它们推入到弹性搜索中,并使用其反向搜索(Percolator)功能来匹配价格走势与客户查询,并最终在找到匹配后将警报推送给客户。
- 你有分析/业务智能需求,并希望快速调查、分析、可视化,并对大量数据提出特别问题(想想数百万或数十亿的记录)。在这种情况下,你可以使用Elasticsearch来存储数据,然后使用Kibana (Elasticsearch/ loghide /Kibana堆栈的一部分)来构建自定义仪表板,以可视化对您来说很重要的数据的各个方面。此外,还可以使用Elasticsearch聚合功能对数据执行复杂的业务智能查询。
阅读记录点:
1、Elasticsearch的文件存储,是面向文档型数据库,一条数据相当于一个文档,用JSON作为文档序列化的格式。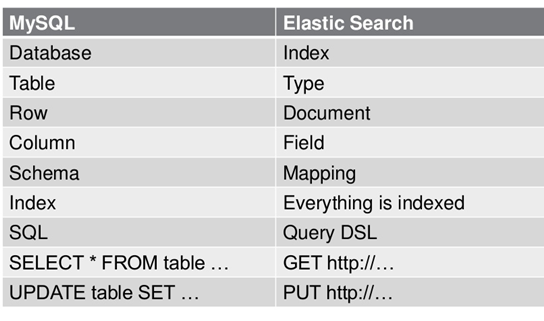
2、Elasticsearch最关键的就是提供强大的索引能力。一切设计都是为了提高搜索的性能。
3、Elasticsearch使用的倒排索引比关系型数据库的B-Tree索引快。
什么是B-Tree索引?
叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读)。为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。
什么是倒排索引?

Posting List:Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
Term Dictionary:Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页。
term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output. 减少内存
4、Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。
增量编码压缩,将大数变小数,按字节存储。
5、Roaring bitmaps
Bitmap的缺点是存储空间随着文档个数线性增长。Roaring bitmaps可以避免这一点。
具体是利用指数特性:将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
6、联合索引
利用跳表(Skip list)的数据结构快速做“与”运算,或者利用bitset按位“与”
7、 ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。