一、效能分析
1、作业地址:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139
2、git地址:https://git.coding.net/kefei101/wfAnalysis.git
3、对wf小程序的功能三进行效能分析,以war_and_peace.txt作为测试文件,使用效能分析工具ptime.exe,连续运行三次,给出每次消耗时间。
说明:下载后,将自己的wf.exe放到word_count_demo文件夹,打开cmd命令行,首先输入ptime wf,再写自己的小程序命令。
三次运行结果如下图所示:
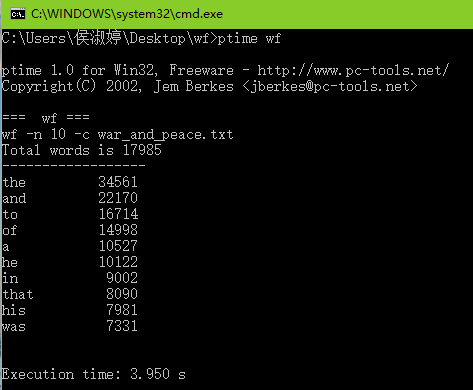

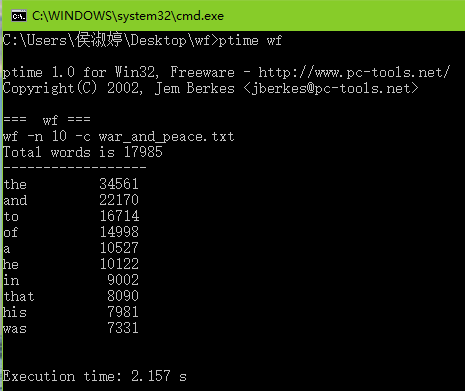
| 次数 | 时间 |
| 1 | 3.950s |
| 2 | 2.851s |
| 3 | 2.157s |
| 平均 | 2.984s |
二、猜测瓶颈
针对测试文档war_and_peace.txt,所用到的流程是

所用到的方法有Jagger类的JaggerFormat(),ReadTxt类的txtToString()方法,SortMap类的sortMap(Map map,int num)方法。
我认为程序中耗时较多的函数方法/程序段有以下几个:
(1)我的程序是一层一层深入的,从判断,到逐层进入对应方法,从而执行方法,输出结果。那么我想在JaggerFormat()方法中耗时的有:判断输入格式,分隔字符串
当然这里面还有我的附加功能(输入格式第一个单词是wf.exe所处的文件夹名)所用到的获取路径方法,我觉得这所占时间是必须的,这也是我的程序比他人运行时间更长的原因之一。


1 //用 stringTokenizer 方法截取输入格式每个单词,放入list中 2 StringTokenizer stringTokenizer = new StringTokenizer(order, " "); 3 ArrayList<String> list = new ArrayList<String>(); 4 while (stringTokenizer.hasMoreElements()) { 5 list.add(stringTokenizer.nextToken()); 6 } 7 8 //判断第一个单词是否是wf程序所处文件夹名 9 String project = System.getProperty("user.dir"); 10 project = project.substring(project.lastIndexOf('\') + 1, project.length());
(2)最重要的方法,也是我认为最耗时的方法,这里读取txt文档用到的方法是BufferedReader的r.readLine()方法,测试文件内容很多,上万行,由于是一行一行读取的,速度可能受限,且统计词频的时候要一个一个判断是否是单词,猜测所占时间比较多。优化的话,换一种读取txt文档方法?
1 //一行一行读取txt文档 2 while ((string = reader.readLine()) != null) { 3 4 //将非字母非数字的字符转化为空格 5 string = string.replaceAll("[^a-zA-Z0-9]", " "); 6 string = string.toLowerCase(); 7 //以空格为依据截取单词 8 StringTokenizer stringTokenizer = new StringTokenizer(string, " "); 9 10 //Then use the LinkedHashMap to store words and word frequency. 11 while (stringTokenizer.hasMoreTokens()) { 12 13 String word = stringTokenizer.nextToken(); 14 //判断单词首字母是否是数字,若不是则加入单词序列,否则不要 15 String first = word.substring(0, 1); 16 if (!first.matches("[0-9]{1,}")) { 17 //计算词频 18 if (!map.containsKey(word)) { 19 map.put(word, new Integer(1)); 20 } else { 21 int newNum = map.get(word).intValue() + 1; 22 map.put(word, new Integer(newNum)); 23 } 24 } 25 } 26 }
(3)最后我认为比较耗时的就是排序输出了,我的sortMap(Map map,int num)里有用到MyMap对象,通过它更方便存取List的同时,可能也会降低程序运行速度。其实之前我有试过别的方法,但我觉得这是最分工明确的,也是较为简单的方法。在大型项目中,更为结构化的程序结构体系应该被提倡,我觉得没毛病。
1 List<MyMap<String,Integer>> list = new ArrayList<MyMap<String,Integer>>(); 2 //将HASMAP类型数据转换为集合类型,并获得MAP迭代器。 3 Iterator iterator = map.keySet().iterator(); 4 while (iterator.hasNext()){ 5 //迭代器中的单词通过使用MyMap类存储在列表中。 6 MyMap<String,Integer> word = new MyMap<String,Integer>(); 7 String key = (String) iterator.next(); 8 word.setKey(key); 9 word.setValue((Integer) map.get(key)); 10 list.add(word); 11 } 12 //排序 13 Collections.sort(list,new Compare());
三、工具分析
在开发大型Java应用程序的过程中难免遇到内存泄漏、性能瓶颈等问题,那随着应用程序的持续运行,可能会造成整个系统运行效率下降等等,那作为未来程序员的一分子,我们也应该提前养成好习惯,在项目程序开发后会使用性能分析工具来找出程序中隐藏的问题,对应用程序的性能进行分析和优化。
针对我的wf统计词频小程序,我使用的是VisualVM性能分析工具,它能通过多种方式从程序运行时获得实时数据,从而进行动态性能分析。(参考博客:https://blog.csdn.net/u013970991/article/details/52036253)由于我所使用的JDK是1.8版本的,使用IDEA编程,可以直接在Idea下载插件使用。
以下是分析工具分析的截图:
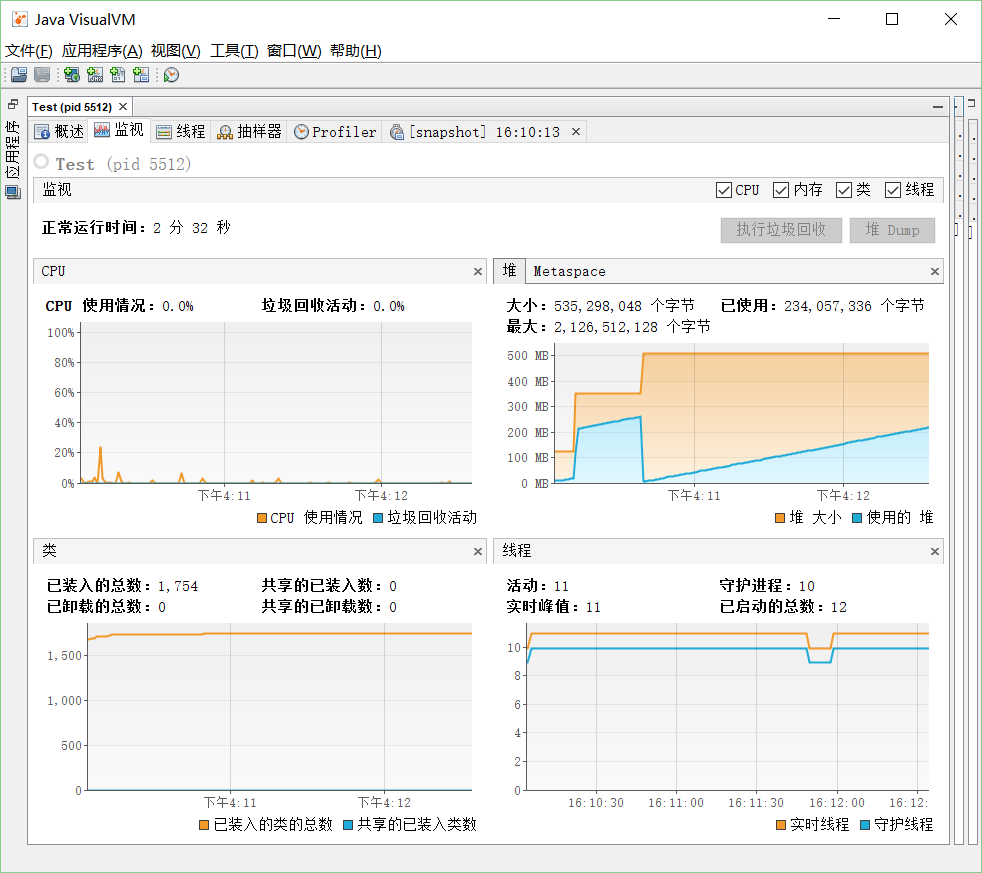

对于以上profile的结果进行分析,发现程序运行最耗时的果然是读取txt文档方法txtToString(),占最大时间的是matches()方法,我查了一下,发现如果需要判断的字符串不是特别复杂,类似于程序中仅仅只是判断字符串首字母是否是数字字符,没有必要使用正则表达式判断,在大项目里面正则表达式最有可能影响性能。
四、程序代码优化
针对matches() 正则表达式判断占时间问题的优化,使用Java中String库中的startsWith()函数进行优化。
1 //Then use the LinkedHashMap to store words and word frequency. 2 while (stringTokenizer.hasMoreTokens()) { 3 4 String word = stringTokenizer.nextToken(); 5 //优化一:使用String的startsWith方法判断单词首字母 6 boolean notWord = word.startsWith("1")||word.startsWith("2")||word.startsWith("3")||word.startsWith("4")||word.startsWith("5") ||word.startsWith("6")||word.startsWith("7")||word.startsWith("8")||word.startsWith("9")||word.startsWith("0"); 7 if (!notWord) { 8 //Statistical word frequency 9 if (!map.containsKey(word)) { 10 map.put(word, new Integer(1)); 11 } else { 12 int newNum = map.get(word).intValue() + 1; 13 map.put(word, new Integer(newNum)); 14 } 15 } 16 }
优化后效能分析对比如下图所示:

其实在我做词频统计小程序的时候,就有考虑到如何让代码看起来更好看,使用哪些方法可以减少代码冗余,提高性能,因此对于这次的效能分析作业我是不担心的。毕竟之前做了那么久功课,尽可能让程序更完美。所以其他的我觉得都没有问题,如果大家觉得我代码哪里不好,欢迎指正!
经过优化后,以war_and_peace.txt再次作为测试文档,使用ptime效能工具分析结果如图:
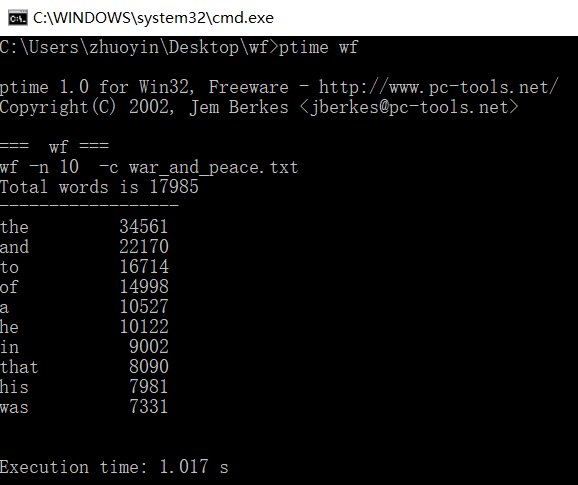


| 次数 | 时间 |
| 1 | 1.017s |
| 2 | 1.036s |
| 3 | 0.993s |
| 平均 | 1.015s |
五、自我评估
问题:在你一生中身体最健康,精力最旺盛的时候,能在大学学习和研究,是一生中少有的机会。请说明一下,你已经具备的专业知识、技能、能力有哪些?离成为一个合格的 IT专业毕业生,在专业知识、技能、能力上还差距哪些?
首先我觉得计算机专业的人才应该具备的不仅仅只是知识本身,还要有学习的能力,知道怎么学,去哪里学,怎么想问题,思维方向等等。而作为计算机专业的一名大学生,首先要有计算机基础。我们大一中会学习高数、线代、模电、web、C语言、计算机导论等专业课,打下计算机理论基础,了解计算机;大二会学习各种编程语言、数据结构、数电、TcpIp、算法等专业课,还有一些上手小项目的专选课,像Android应用程序开发、项目实践课程等。我,虽然专业课期末成绩还能说得过去,那也只有自己知道,自己肚子里的墨水有多深。实话说,我的墨水不深,学的东西多却又不精,往往上个学期的知识,这个学期就又忘了。
技能的话,我现在是学校卓音工作室后端开发人员,会的东西....Java、PHP后端开发,做过一点Python小项目,写过Matlab小程序片段。当然大部分只是会用,并没有深入了解机理。说来惭愧,我的算法不好,没有足够耐心去钻研它。还有一个最重要的,就是团体做项目的时候,我从来只是参与人员,而不是组织者,没有自己组织过开发某个项目。所以说,我离成为一个合格的IT专业毕业生的差距还是很大的。在算法上、计算机机理、Java编程原理、编程语言、项目开发流程等等都相差甚远。与优秀的学长学姐相比,还是差很多的,想毕业直接出来找工作,应该会很难吧。
针对下面这个调查问卷,写下表格,发现自己的薄弱点、不足点:

| 技能 | 课前评估 | 课后评估 |
| Programming Overall(对编程的理解) | 3 | 6 |
| Programming:Comprehension(程序理解,阅读,分析,debug) | 5 | 8 |
| Programming:Implementation(模块实现,逐步细化) | 5 | 8 |
| Programming:Performance(效能分析和改进) | 2 | 7 |
| Programming Language(Java) | 4 | 9 |
| Ability to Learn(自主学习能力) | 4 | 9 |
| Computer Science(算法) | 2 | 8 |
| Task Plan,estimation and Prioritization(计划任务,估计时间和优先级) | 2 | 7 |
以上便是我的软件工程作业 week 3,如有不妥,欢迎批评指正!