一 概述
参考博文:
- https://blog.csdn.net/m0_37914588/article/details/82287191
- https://www.jianshu.com/p/8b6eb2fd15ab
- https://www.jianshu.com/p/4aa3bb16f36c
- https://blog.csdn.net/qq_36856024/article/details/99688530?depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-1&utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-1
HashMap实现
Hashmap继承了AbstractMap,实现了Map接口和Cloneable接口,HashMap是基于哈希表(也叫散列表),实现Map接口的双列集合
jdk8中底层数据结构value已经改为数组+链表+二叉树,之前是数组+链表,即key用数组实现,value用链表和红黑树实现
看Hashmap之前,需要把Map,AbstractMap源码撸一遍,否则对整体设计结构不清楚,这里放我的博文链接: https://www.cnblogs.com/houzheng/p/12687883.html
涉及到的数据结构扫盲
当然了还需要撸一遍涉及到的数据结构
哈希函数
哈希函数(Hash Function),也称为散列函数,给定一个输入x,它会算出相应的输出H(x)。哈希函数的主要特征是:
- 输入x可以是任意长度的字符串
- 输出结果即H(x)的长度是固定的
- 计算 H(x) 的过程是高效的(对于长度为 n 的字符串 x ,计算出 H(x) 的时间复杂度应为 O(n) )
即根据这个函数和查找关键字key,可以直接确定查找值所在位置,而不需要一个个比较
哈希表是基于哈希函数建立的一种查找表(数据结构),即就是通过hashmap的key可以找到对应的哈希表中的某个元素(高效快速的找和插入,不是一个一个遍历)
数组查找快,但是插入更新慢,链表查找慢,但是插入删除快
哈希表就是两者的结合,查找插入更新都快
哈希冲突
不同的输入x通过相同哈希函数计算出相同的哈希地址,即相同输出,该种现象称为哈希冲突或哈希碰撞.
而解决哈希冲突的办法:
- 开放定址法
即发生冲突时,去寻找下一个空的哈希地址。只要哈希表足够大,总能找到空的哈希地址。 - 再散列函数法
即发生冲突时,由其他的函数再计算一次哈希值 - 链地址法
HashMap底层使用的就是链地址法
链地址法
将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部.如图:

图中每一行的一个链表就称为一个哈希桶,
即添加数据的时候根据key通过哈希函数算出输出值,这个值即为哈希桶的数组坐标,
坐标相同的就往后添加形成链表,再多于8个了,就转化为红黑树存储.
hashMap中的哈希函数式 (n-1) & hash ,当n是2的幂次方的时候 (n-1) & hash =hash % n, 所以这也是为什么hashMap的n都是2的幂次方,为了位运算提高性能
所以查找的时候也先通过key和哈希函数算出哈希桶坐标,这个坐标的数据就是链表的头或者红黑树的头,再通过头部和key找到想要查找的那个值
红黑树
红黑树是jdk8之后的一种HashMap的优化,特点,基本上就是一层黑一层红:
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点(简称黑高)。

二 源码分析
属性
//静态属性
//hashmap的默认初始容量,16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量值: 1073741824
static final int MAXIMUM_CAPACITY = 1 << 30;
//加载因子,用于扩容使用,是比较合理的值,意思是如果当前容器的容量,达到了我们设定的最大值,就要开始执行扩容操作。
// 比如说当前的容器容量是16,负载因子是0.75,16*0.75=12,也就是说,当容量达到了12的时候就会进行扩容操作
// 如果这个值过小,比如0.5,那么map容量到一半就会扩容,造成空间浪费,如果过大,比如1,则容量满了之后才会扩容,这种情况下hash冲突就会增多(因为桶少了,相应的hash冲突会变多,导致树节点越来越多越长),导致查询变复杂,效率降低
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 使用红黑树的阈值,即链表节点数大于8的时候就转化为红黑树
static final int TREEIFY_THRESHOLD = 8;
//红黑树转化为链表的阈值,即桶节点小于6
static final int UNTREEIFY_THRESHOLD = 6;
// 用链表的最小容量,当整个hashMap中元素数量大于64时,也会进行转为红黑树结构。
static final int MIN_TREEIFY_CAPACITY = 64;
/* ---------------- Fields -------------- */
//存储元素的数组
transient Node<K,V>[] table; // Node:即链表或者红黑树中的每一个节点
//将数据转换成set的另一种存储形式
transient Set<Map.Entry<K,V>> entrySet;
//元素个数
transient int size;
// 修改次数
transient int modCount;
//临界值,也就是元素数量达到临界值时,会进行扩容
int threshold;
// 哈希表的加载因子
final float loadFactor;
Node类,单向链表数据结构
//一个节点的实现类,单向链表结构,即一个哈希桶的元素小于8时,用这种结构存储
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //hash值,相同hash值的元素在一个链表中
final K key;
V value;
Node<K,V> next;//此节点的下一个节点,相同hash值的Node,通过next进行遍历查找
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
TreeNode,红黑树的实现
TreeNode是HashMap的一个静态内部类,为什么先搞红黑树,因为下面有实例方法会用到红黑树中的方法,比如get,put等,搞明白了这些逻辑,理解起HashMap的整体操作就简单多了
//红黑树的结构实现类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父节点
TreeNode<K,V> left; // 左节点
TreeNode<K,V> right; // 右节点
TreeNode<K,V> prev; // 用来删除下一个节点用的,因此prev也就是上一个节点
boolean red; //是否是红黑树的红节点
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next); //父类是Node,所以同时 也是一个单向链表结构
}
//获取根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {//定义两个变量都为当前Node,一直往上找
if ((p = r.parent) == null) // 父节点为null,即为root节点
return r;
r = p;
}
}
//确保参数的root节点是树的根节点,如果不是变成根节点
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;//root的位置
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
//如果root不是第一个节点,要变成第一个节点,这里是链表操作,逻辑就是把root从原来的位置拿掉,
// 即root的前后节点对接,然后将root放到第一个位置,他的下一个节点应该变成原来的first节点
if (root != first) {
Node<K,V> rn;
tab[index] = root;//root放在根节点
TreeNode<K,V> rp = root.prev;//root的上一个节点
if ((rn = root.next) != null)
//将root原来的下个节点的上个节点(本来是root自己)变成root的上个节点
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;//原来root上一个节点的下一个节点(本来是root自己)变成root的下一个节点
if (first != null)
first.prev = root;//原来第一个节点的上一个节点变成root
root.next = first;//root的下一个节点变成原来的first
root.prev = null;// root根节点上一级为null
}
assert checkInvariants(root);//红黑树的一致性检查,确保结构不变
}
}
// map.get() 如果是红黑树就是用的这个方法进行查找
//查找该k和对应的hash值(hash值计算出哈希桶数组下标,即数组的索引位置为链表或者红黑树的头结点)的节点并返回
//调用的时候都是以红黑树的头结点开始调用的,所以this一般都是树的root节点
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this; //开始是root节点
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
//查找步骤:
if ((ph = p.hash) > h) //1 如果root的hash值大于h,说明h在左边,否则在右边
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))// 2 如果hash值相等且key也相等,则返回找到的节点
return p;
else if (pl == null) //3 h如果ash值相等但key不相等得继续,再如果子树有一个为null则从另一个开始找
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null || // //如果不按照hash比较,则按照比较器比较,查找左子树还是右子树
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null) //4 如果hash值相等key不相等且子树都不为null,则递归找右子树
return q;
else
p = pl; //5 右子树递归完也没找到,则从左子树开始重新找
} while (p != null);
return null;
}
// 根节点调用find方法查找k对应节点
final TreeNode<K,V> getTreeNode(int h, Object k) {
//如果调用的节点不是root节点就获取root节点,再调用
return ((parent != null) ? root() : this).find(h, k, null);
}
/**
* 确定红黑树插入子节点的顺序(左边还是右边)
* put的时候如果hash值相等,则会比较key,如果key没有实现Comparable接口,或者比较结果为0,则会用这个方法最终比较确定左右子树的顺序
* 用这个方法来比较两个对象,返回值要么大于0,要么小于0,不会为0
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
// 先比较两个对象的类名,类名相等则用内存地址的hashcode进行比较
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
//返回两个类内存地址的hashCode比较结果,并非是类的hashCode的比较,小于等于都返回-1
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
// 把链表生成红黑树,返回头节点
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) { //遍历链表
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false; //根节点是黑色
root = x; // 将第一个节点先设为root根节点
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h) //根据hash值决定是左子树还是右子树
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null && //hash相等根据key比较
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk); //比较不出来最终比较方法,一定会出结果,查找的时候查左还是右也是最终到这个方法返回比较大小
TreeNode<K,V> xp = p;
// 这里将p重新赋值为左子树或者右子树,如果不为空,那么继续循环往下找
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp; //设置父节点
//设置子树节点
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);//平衡化,调整为红黑树
break;
}
}
}
}
moveRootToFront(tab, root);
}
// 红黑树转化为链表并返回
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);//转化为Node
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
// 往红黑树添加节点
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, HashMap.Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;// 赋值root
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
//下面这一截if else都是左右比较,即新节点是往到左子树还是右子树
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
// hash冲突,比较key是否相同
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) { //标志是否搜索过key,即key是否存在,只会搜索一次
TreeNode<K,V> q, ch;
searched = true;
//左右递归搜索,找到了直接返回,key不允许重复
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
//插入节点
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) { //插入到最后的节点,左或者右
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
// 维持链表结构,这里就表名迭代器可以根据链表一直迭代,树里面节点也是间接的维持了链表的指向
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
// 平衡化并返回root,主要是满足红黑树的五个特性
/**
* 这里总结一下步骤: 首先,新节点会当做红色节点进行插入
* 1 首先判断是不是根节点,如果是根节点直接变黑色返回,即是第一个节点进来
* 2 判断父节点是否是黑色或者爷爷节点为null,则直接返回:
* 第一点: 因为红黑树总是一层黑一层红,所以当父节点是黑色的时候,红色节点直接插入即可
* 第二点: 爷爷节点为null,说明父节点是根节点,即黑色,插入没毛病
* 3 既然父节点是红色,那么就要分两种情况了.这两种情况是对称操作的,逻辑刚好相反:
* 1 父节点是爷爷节点的左子树:
* 1 如果右子树为null: 不平衡,需要旋转,旋转->变色-> 旋转
* 2 如果右子树不为null: 平衡,需要变色,指针上移到爷爷,继续循环
* 2 父节点是爷爷节点的右子树
* 这里和上面一样,只不过旋转方向是一反
*/
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root, TreeNode<K,V> x) {
x.red = true; //新节点都先标为红色处理
// xp:当前节点的父节点、xpp:爷爷节点、xppl:左叔叔节点、xppr:右叔叔节点
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
//1 如果是根节点,那么是黑色的,直接返回
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//2 如果父节点是黑色,或者爷爷节点为null,即父节点是根节点,这两种情况都直接满足红黑树特性,不需要单独处理,直接返回root
else if (!xp.red || (xpp = xp.parent) == null)
return root;
//3 如果父节点是红色,则继续处理,这里已经表示至少是第四个节点进来了,分两种情况:
// 一 如果父节点等于爷爷节点的左子树,即类似下面这种情况:
/**
* 根
* 红(父)
* x
*/
if (xp == (xppl = xpp.left)) {
// 且爷爷节点的右子树不为null并且是红色, 则将爷爷节点的两个子树都变黑,爷爷变红并赋值给x
/**
* 根 x(红)
* 红(父) 红 ---变色---> 黑 黑
* x(红) 红
*/
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;//将爷爷节点变红并赋值给x
x = xpp; // x指针上移动到爷爷,因为没有改变x的属性而是拷贝的引用,所以树结构不被破坏,下一次循环从上面继续爷爷节点开始判断
}
/** 如果爷爷的右子树为空
* 根 根 红 黑
* 红 ---左旋---> 红 --变色--> 黑 ---> 右旋 红 红
* x x x红
*/
else { // 如果爷爷的右子树为空或者是黑色
if (x == xp.right) { //如果x是父节点的右子树,则左旋
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false; //父亲变黑
if (xpp != null) {
xpp.red = true; //爷爷变红
root = rotateRight(root, xpp); //右旋
}
}
}
}
// 二 如果父节点是爷爷节点的右子树,这下面逻辑和上面基本都一样,一个左一个右,对称操作
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
//左旋,其实就只有两部操作,就是把旋转的点p的右子树r转到p的位置,然后如果右子树r有左节点就指到p的右子树,没有就不管,右旋是相反的操作
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,TreeNode<K,V> p) {
TreeNode<K,V> r, pp, rl;
if (p != null && (r = p.right) != null) { //p的右子树不为空则左旋
/**
* 根 根
* p ----> r
* r p
*/
if ((rl = p.right = r.left) != null) // 判断r是否有左节点,有就转到p的右子树
rl.parent = p;
if ((pp = r.parent = p.parent) == null) // 将r的父节点改成p的父节点,即r移动到p的位置
(root = r).red = false; //为null表名此时r成为了root
else if (pp.left == p) // 否则如果p是父节点左子树就把r指向p的位置,其实就是把r转到p的原来位置
pp.left = r;
else
pp.right = r;
r.left = p;
p.parent = r;
}
return root;
}
// 右旋
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root, TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
/**
* p红 l
* l黑 ----> x红 p红
* x红
*/
if (p != null && (l = p.left) != null) {
if ((lr = p.left = l.right) != null)
lr.parent = p;
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
//不变性检查,保证红黑树的结构不改变,从某一个节点开始,会递归检查所有的左右节点,根节点检查整棵树
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,
tb = t.prev, tn = (TreeNode<K,V>)t.next;
if (tb != null && tb.next != t) //前后是否一直
return false;
if (tn != null && tn.prev != t) //前后是否一直
return false;
if (tp != null && t != tp.left && t != tp.right) //左右是否一致
return false;
if (tl != null && (tl.parent != t || tl.hash > t.hash)) //父节点是否一致或者hash值是否按照查找树排列,即左<右
return false;
if (tr != null && (tr.parent != t || tr.hash < t.hash)) //父节点是否一致或者hash值是否按照查找树排列,即右>左
return false;
if (t.red && tl != null && tl.red && tr != null && tr.red) //如果t是红节点,左右节点也是红节点就返回false
return false;
if (tl != null && !checkInvariants(tl))// 同理检查左节点,一直递归检查整棵树
return false;
if (tr != null && !checkInvariants(tr)) // 同理检查右节点,一直递归检查整棵树
return false;
return true;
}
静态方法
// 根据key获取hash函数输出值,通过这个hash值去确定哈希桶的index(算法:(n - 1) & hash),红黑树的节点位置等等
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 如果x实现了Comparable接口,则返回Class,否则返回null,这个方法主要是看key是否实现了Comparable接口,可以用来直接比较
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; ParameterizedType p;
//多数情况下我们都会用String来作为这个key,这里直接返回优化性能
if ((c = x.getClass()) == String.class)
return c;
//下面这一段就是看看x的class是否 implements Comparable<x的class> (注意这里有泛型)
if ((ts = c.getGenericInterfaces()) != null) {
for (Type t : ts) {
if ((t instanceof ParameterizedType) &&
((p = (ParameterizedType) t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}
//如果x所属的类是kc,返回k.compareTo(x)的比较结果,如果x为空,或者其所属的类不是kc,返回0,主要是put的时候用来比较的方法
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}
//调整table长度的方法,大于输入参数且最近的2的整数次幂的数。比如10,则返回16=2的4次幂, 初始化或者扩容的时候会用到
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
构造器
负载因子和容量,阈值之间关系比较重要,一定要先搞清楚
//构造器: 初始容量, 负载因子, 这里说一下负载因子, 负载因子是决定了阈值的大小, 比如0.75,容量是16,那么阈值=16* 0.75,到达12就会扩容
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY) //如果初始容量大于最大容量,则使用最大容量
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor)) //负载因子必须是数字
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 调用tableSizeFor方法计算出不小于initialCapacity的最小的2的幂的结果,并赋给成员变量threshold临界值
this.threshold = tableSizeFor(initialCapacity);
}
//构造器, 初始容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 空构造器
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//根据传入的指定的Map参数去初始化一个新的HashMap,该HashMap拥有着和原Map中相同的映射关系
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false); //调用下面putMapEntries()来完成HashMap的初始化赋值过程
}
// putAll方法也是调用的下面
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
// 计算HashMap的最小需要的容量,这里是 最小容量*负载因子=阈值,到达阈值会扩容,所以做除法,即如果s是10,那么容量必须是16才能保证10没有达到阈值
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ? //如果大于最大值,使用最大值
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold) //如果容量大于临界值,则重新计算临界值,取大于该容量的最小的2的幂的值
threshold = tableSizeFor(t);
}
else if (s > threshold) // 如果map的大小超过了临界值,则进行扩容
resize();
// 遍历进行put
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
实例方法
这里涉及到的链表和红黑树操作比较多,比如get,put,remove,clear,resize,都是比较重要的方法,理解了这些方法的代码,差不读hashMap就理解了
尤其是put,get和扩容机制,里面遇到红黑树的部分,还需要上面红黑树TreeNode里面对应方法帮助理解
//获取大小
public int size() { return size; }
//判断map是否为空
public boolean isEmpty() { return size == 0; }
//判断是否包含key
public boolean containsKey(Object key) { return getNode(hash(key), key) != null; }
//根据key获取value
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//根据key和hash查找节点
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 && //判断table不为null,且长度>0,此哈希桶头结点不为null
(first = tab[(n - 1) & hash]) != null) { // 根据hash计算出数组中的index,这个下标对应的节点即为链表或者红黑树的头结点
if (first.hash == hash && //判断要找的是否是头结点,如果是直接返回,提升效率
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode) // 判断是否是红黑树,如果是使用红黑树的查找方法
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 使用链表查找法,遍历一直往下一个节点查找,直到找到为止
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
// new一个Node节点实例,下面put会用到
Node<K,V> newNode(int hash, K key, V value,Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
// put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//如果table为null或者length=0则扩容
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 计算出数组坐标,如果此节点为null,则直接添加到此位置成为链表或者红黑树的头节点
tab[i] = newNode(hash, key, value, null); //只有是头节点会添加到数组table中,其他都会形成树或者链表
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // 判断要添加的key是否和这个头节点key相等
e = p;
else if (p instanceof TreeNode) //不相等,如果是红黑树则,进行红黑树的put
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 否则,链表put
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //如果p节点后面节点为null则直接往后面链表添加
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 如果添加次数大于7了,那么就将链表转化为红黑树,提升效率
treeifyBin(tab, hash);
break;
}
//添加确认,直接break
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e; //一直往后
}
}
if (e != null) { // 覆盖value
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //afterNode 开头这几个方法都是为HashMap的子类LinkedHashMap服务的,本类是空实现,不必在这里关注
return oldValue;
}
}
++modCount; //修改次数++
if (++size > threshold) // 大于阈值,进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
// 扩容: 重点中的重点方法,面试贼爱问.逻辑一定要能背下来,其实就是重新计算 table大小和阈值,还有个神级优化
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //旧table
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 旧table长度
int oldThr = threshold; //旧阈值
int newCap, newThr = 0; //定义新的长度和阈值
// 1 如果原来容量大于0
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { //且超过了最大值,则直接返回原来的,不能再扩大了
threshold = Integer.MAX_VALUE;
return oldTab;
}
//这里会先将容量变为2倍(划重点,按照2倍扩容),如果此时不超过最大容量,且原容量大于HashMap的默认容量16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; //则将newThr的值设置为原HashMap的阈值*2
}
//2 如果原容量不大于0,即原table为null,但是原阈值大于0,即使用指定容量构造器
else if (oldThr > 0)
newCap = oldThr; //将原阈值作为容量赋值给newCap当做newCap的值
//3 如果原容量不大于0,原阈值也不大于0,即空构造器
else {
newCap = DEFAULT_INITIAL_CAPACITY; //使用默认值 16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 阈值 = 容量 * 负载因子
}
//经过上面的处理过程,如果newThr值为0,给newThr进行赋值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//初始化一个新的容量大小为newCap的Node数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; //给table重新赋值
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) { // 从0开始遍历原table
Node<K,V> e;
if ((e = oldTab[j]) != null) { //如果原来j位置的节点不为null,则赋值给e之后设为null
oldTab[j] = null;
if (e.next == null) //next==null,说明这个节点不存在后续节点,即这个节点肯定是在数组中的某一个,即哈希桶的头节点位置
newTab[e.hash & (newCap - 1)] = e; //添加到对应数组位置
else if (e instanceof TreeNode) // 如果有后续节点,说明这个节点可能是在链表或者红黑树中
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 调用红黑树的方法
else { // 否则走链表的方法
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/**
* 只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,
* 这里在jdk8里做了优化,采用oldCap & e.hash 算法决定是否改变位置:
* 原理:
* 1 因为oldCap是2的次幂高位为1,低位为0,且newCap = oldCap << 1,即高位1左移一位
* 2 旧坐标是 hash & (oldCap -1), 对应的新坐标是 hash & (newCap-1), 主要是对这个重新计算hash的优化
* 3 所以因为 newCap高位多了一位,所以就可能导致本来的hash值位运算的时候这个对应高位可能变为1,那么位置就要+oldCap(因为是n-1,所以是前一位,刚好是oldCap)
* 比如: 本来oldCap =8,那么 oldCap -1 =0111, newCap=16, 那么newCap-1= 01111, 即重新计算坐标只是在oldCap的最高位变成了1,其他不变
* 所以只需要判断这一位就可以,刚好是oldCap的最高位,计算一下就可以了,位运算后如果这一位为1(即结果不为0),那么说明重新计算后的位置改变了,而且刚好多了oldCap个,因为这个位置变1了.所以要+ldCap
* 如果为0,那么说明重新计算坐标后值和原来还一样,
* HashMap就是利用这个只需要跟原来oldCap位运算就可以计算出新坐标了,结果跟重新计算是一样的,优化了
*/
if ((e.hash & oldCap) == 0) { //坐标不变
// 这里第一次循环 loTail=e,loHead=e,第二次e.next进来,因为loTail=e,所以就是e.next=e.next,往后添加
// 即只有第一次进来的时候赋值头节点,后面都一直往后添加
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { // 左边有变化,这里逻辑和上面是一样的,追加链表,第一次赋值头节点,即hiHead
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null); //继续下一个
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead; //将上面形成的链表头部添加到数组对应位置
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead; //将上面形成的链表头部添加到数组对应位置
}
}
}
}
}
return newTab; //返回新table
}
// 链表 -> 红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) //如果数组长度小于64的话会再次扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) { // 否则树化
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null); //节点类型变化为TreeNode
if (tl == null) //第一次循环 hd =e,tl=e,之后一直走else,添加节点之间前后关系,不止next还有prev
hd = p; // 头节点
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null) //赋值头节点
hd.treeify(tab); //调用红黑树的树化方法,真正树化
}
}
//根据key移除元素,返回移除的元素value,没有返回null
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) { //计算出数组下标的节点
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p; // 1 如果是头节点
else if ((e = p.next) != null) {
if (p instanceof TreeNode //2 如果是红黑树调用红黑树的寻找方法
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else { //3 否则链表
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//找到node之后
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) // 调用红黑树移除方法
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p) //如果是数组中的节点
tab[index] = node.next; // 直接将后一个节点移动到数组位置
else // 否则就是链表
p.next = node.next; //链表删除,简单粗暴
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
//清除HashMap
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null; //只会把数组中节点元素全部置为null,链表和红黑树中节点因为GCROOT不可达,会自动被回收
}
}
//判断是否包含value
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (Node<K,V> e : tab) { //从数组开始
for (; e != null; e = e.next) { //遍历每一个链表或者红黑树
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
这里贴一下扩容优化运算图,方便理解,其实就是避免重新 hash & (newCap-1) ,但是又和这个是一样的结果,
理解难点在于 里面的-1, 和2的次幂,-1刚好后面为1,最高位为0,容量大小,刚好是一反,最高位为1低位为0

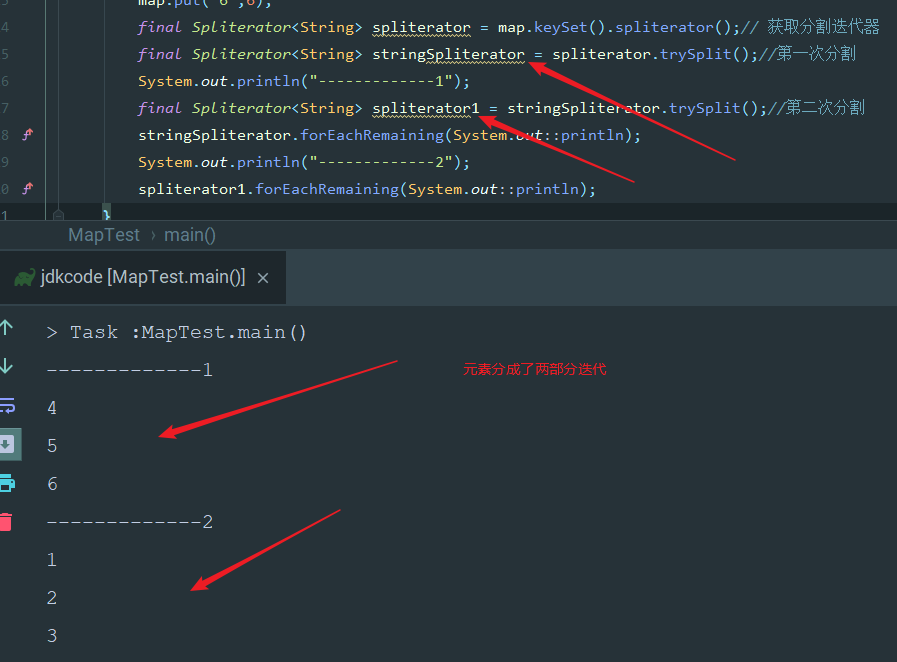
迭代器与分割迭代器
HashMap中的keySet和valus以及entrySet都是返回了一个内部类实例,并没有重新生成一个集合,遍历都是在原table中的数据进行遍历的,并且定义了两种初始的迭代器,普通和可以分割的迭代器
分割迭代器就是可以把map中的元素分成好几个迭代器一起迭代
//返回一个内部类实例,该内部类重写了迭代器方法,当在增强for循环时才调用,并从外部类的table中取值。
// 重点:并没有获取所有的key集合,而是直接操作外部类的key,values和entrySet都是一个原理,都用的内部类直接操作外部类数据
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
//内部类,重新实现AbstractSet,这里并没有
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { this.clear(); }
public final Iterator<K> iterator() { return KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(this, 0, -1, 0, 0);
}
//遍历
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount; //防止改变
for (Node<K,V> e : tab) {
for (; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc) //如果遍历过程中有被修改,则抛出异常
throw new ConcurrentModificationException();
}
}
}
// key迭代器
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
// 抽象迭代器
abstract class HashIterator {
Node<K,V> next; // 下一个节点
Node<K,V> current; // 当前节点
int expectedModCount; // 代表修改次数
int index; // 当前节点数组下标
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
//初始化的时候会将数组中的第一个不为空的元素下标以及值,并将此元素值赋给next,即找到数组第一个不为空的桶的位置
if (t != null && size > 0) {
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
//返回下一个Node
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount) //改动检查
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//如果next的下一个节点为null,说明当前数组没有值了,移动到数组下一个坐标不为空的坐标
// 因为TreeNode是Node的子类,所以也是有next的,可以完成遍历
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
removeNode(p.hash, p.key, null, false, false);// 直接调用外部类的方法
expectedModCount = modCount; //这里重新赋值,所以迭代器里面可以安全remove
}
}
//初始分割迭代器
static class HashMapSpliterator<K,V> {
final HashMap<K,V> map; // 需要遍历的对象
Node<K,V> current; // 当前节点
int index; // 当前桶索引
int fence; // 当前迭代器遍历上限的桶索引
int est; // 当前迭代器需要遍历的元素个数
int expectedModCount;
HashMapSpliterator(HashMap<K,V> m, int origin,
int fence, int est,
int expectedModCount) {
this.map = m;
this.index = origin;
this.fence = fence;
this.est = est;
this.expectedModCount = expectedModCount;
}
// 获取一个当前迭代器的一个迭代范围,例如返回的值是 4,那么遍历到第四个桶就会结束,如果小于0,则返回桶的个数
final int getFence() {
int hi;
if ((hi = fence) < 0) {
HashMap<K,V> m = map;
est = m.size;
expectedModCount = m.modCount;
Node<K,V>[] tab = m.table;
hi = fence = (tab == null) ? 0 : tab.length;
}
return hi;
}
// 获取当前迭代器需要遍历的元素个数
public final long estimateSize() {
getFence(); // force init
return (long) est;
}
}
//key分割迭代器,就是可以将map中的元素分成好几个迭代器进行迭代,value,entry是一样的,有三个,这里只列一个
static final class KeySpliterator<K,V>
extends HashMapSpliterator<K,V>
implements Spliterator<K> {
KeySpliterator(HashMap<K,V> m, int origin, int fence, int est,
int expectedModCount) {
super(m, origin, fence, est, expectedModCount);
}
// 对当前迭代器进行分割
public KeySpliterator<K,V> trySplit() {
// 把当前迭代器的开始索引和最后索引除以二而已
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid || current != null) ? null :
new KeySpliterator<>(map, lo, index = mid, est >>>= 1,
expectedModCount);
}
//迭代
public void forEachRemaining(Consumer<? super K> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
HashMap<K,V> m = map;
Node<K,V>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<K,V> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p.key);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super K> action) {
int hi;
if (action == null)
throw new NullPointerException();
Node<K,V>[] tab = map.table;
if (tab != null && tab.length >= (hi = getFence()) && index >= 0) {
while (current != null || index < hi) {
if (current == null)
current = tab[index++];
else {
K k = current.key;
current = current.next;
action.accept(k);
if (map.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
}
}
return false;
}
public int characteristics() {
return (fence < 0 || est == map.size ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT;
}
}
分割迭代器用法: