问题描述:将数据库中的大对象查出来,发现几张分区表比较大,对分区表进行处理,分区表压缩,分区表索引重建,数据文件resize
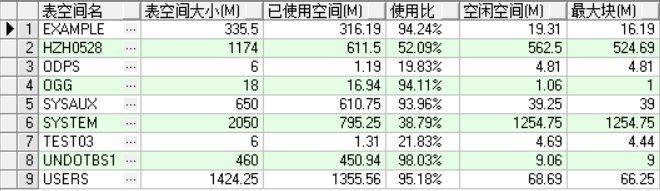
1.查看表空间使用率
SELECT Upper(F.TABLESPACE_NAME) "表空间名", D.TOT_GROOTTE_MB "表空间大小(M)", D.TOT_GROOTTE_MB - F.TOTAL_BYTES "已使用空间(M)", To_char(Round(( D.TOT_GROOTTE_MB - F.TOTAL_BYTES ) / D.TOT_GROOTTE_MB * 100, 2), '990.99') || '%' "使用比", F.TOTAL_BYTES "空闲空间(M)", F.MAX_BYTES "最大块(M)" FROM (SELECT TABLESPACE_NAME, Round(Sum(BYTES) / ( 1024 * 1024 ), 2) TOTAL_BYTES, Round(Max(BYTES) / ( 1024 * 1024 ), 2) MAX_BYTES FROM SYS.DBA_FREE_SPACE GROUP BY TABLESPACE_NAME) F, (SELECT DD.TABLESPACE_NAME, Round(Sum(DD.BYTES) / ( 1024 * 1024 ), 2) TOT_GROOTTE_MB FROM SYS.DBA_DATA_FILES DD GROUP BY DD.TABLESPACE_NAME) D WHERE D.TABLESPACE_NAME = F.TABLESPACE_NAME ORDER BY 1
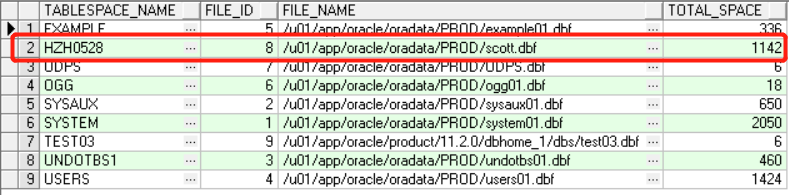
2.查看数据文件大小
SELECT tablespace_name, file_id, file_name, round(bytes / (1024 * 1024), 0) total_space FROM dba_data_files ORDER BY tablespace_name;
3.创建分区测试表
create table test_partiton_02( number_1 number, number_2 number, string_1 varchar2(10), string_2 varchar2(20) ) partition by range(number_2) ( partition p1 values less than (10000), partition p2 values less than (20000), partition p3 values less than (50000), partition p4 values less than (70000), partition p5 values less than (maxvalue) );
4.创建本地分区索引
CREATE INDEX ix_test_partiton_02_1 ON test_partiton_02(number_1)
local (PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4,
PARTITION p5
);--drop index ix_test_partiton_02_1;
5.创建全局分区索引
CREATE INDEX ix_test_partiton_02_2 ON test_partiton_02(number_2) GLOBAL PARTITION BY RANGE (number_2) (PARTITION p1 VALUES LESS THAN (10000), PARTITION p2 VALUES LESS THAN (55000), PARTITION p3 VALUES LESS THAN (MAXVALUE));
6.写入测试数据
insert into test_partiton_02(number_1, number_2, string_1, string_2) select dbms_random.random() as number_1, round(dbms_random.value(0, 100000)) as number_2, dbms_random.string(opt => 'A', len => 1) as String_1, dbms_random.string(opt => 'p', len => 10) as String_2 from dual connect by rownum < 100001; commit;
7.分析表
analyze table test_partiton_02 compute statistics;
8.查看分区表是否压缩,以及生成压缩语句
select /*+parallel(4)*/ p.table_owner,p.table_name,p.partition_name,s.bytes/1024/1024/1024 gb,s.tablespace_name,p.compression,p.compress_for,p.partition_position, RANK() OVER(PARTITION BY TABLE_OWNER,TABLE_NAME ORDER BY PARTITION_POSITION DESC) rn,'alter table '||p.table_owner||'.'||p.table_name||' move partition '||p.partition_name|| ' compress for oltp parallel 4;' from dba_tab_partitions p,dba_segments s where p.table_name=s.segment_name and p.table_owner=s.owner and p.partition_name=s.partition_name and s.SEGMENT_NAME='TEST_PARTITON_02';

9.执行压缩语句
alter table HZH.TEST_PARTITON_02 move partition P5 compress for oltp parallel 4; alter table HZH.TEST_PARTITON_02 move partition P4 compress for oltp parallel 4; alter table HZH.TEST_PARTITON_02 move partition P3 compress for oltp parallel 4; alter table HZH.TEST_PARTITON_02 move partition P2 compress for oltp parallel 4; alter table HZH.TEST_PARTITON_02 move partition P1 compress for oltp parallel 4;
10.再次查看分区表压缩状态,已经可以看到压缩状态编程ENABLED,压缩方式为OLTP,语句见8

11.查看分区索引是否有效
---查看分区索引是否 可用 select index_owner,index_name,partition_name,subpartition_count,high_value,status from dba_ind_partitions t where t.INDEX_NAME in('IX_TEST_PARTITON_02_1','IX_TEST_PARTITON_02_2');

12. 注意tablespace 的实际存储空间,生成索引重建语句
select 'alter index '||p.owner||'.'||p.index_name||' rebuild partition '||i.partition_name||' tablespace HZH0528 parallel 4 online;',
p.owner,p.table_name,p.index_name,p.alignment,i.partition_name,i.status,i.tablespace_name,i.logging,i.compression,i.last_analyzed from dba_part_indexes p,dba_ind_partitions i
where p.index_name=i.index_name and p.owner=i.index_owner and p.owner='HZH' and i.status<>'USABLE' and p.table_name='TEST_PARTITON_02';

13.重建索引,还需要注意关闭重建索引的并行
alter index HZH.IX_TEST_PARTITON_02_1 rebuild partition P1 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_1 rebuild partition P2 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_1 rebuild partition P3 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_1 rebuild partition P4 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_1 rebuild partition P5 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_2 rebuild partition P1 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_2 rebuild partition P2 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_2 rebuild partition P3 tablespace HZH0528 parallel 4 online;
alter index HZH.IX_TEST_PARTITON_02_2 noparallel;
14.重新查看索引状态,状态已经变回usable,重建成功,如果需要重建索引时间较长,建议放在后台执行,要不然会话中断,再次重建会报错,比较麻烦
---查看分区索引是否 可用 select index_owner,index_name,partition_name,subpartition_count,high_value,status from dba_ind_partitions t where t.INDEX_NAME in('IX_TEST_PARTITON_02_1','IX_TEST_PARTITON_02_2');

15.做完表压缩和索引重建,就可以进行数据文件的收缩,如果表空间上T,而且数据文件就是几百个,不建议使用这个SQL,查询非常慢,可以手动指定resize的数据文件大小,如果压不了就报错,不会影响
select a.file#,a.name,c.tablespace_name,round(a.bytes/1024/1024) CurrentMB,ceil(HWM *a.block_size)/1024/1024 ResizeTo,(a.bytes - HWM*a.block_size)/1024/1024 ReleaseMB, 'alter database datafile ' || a.FILE# || ' resize ' ||round(ceil(HWM*a.block_size)/1024/1024+5)||'M;' ResizeCmd from v$datafile a,(SELECT file_id,MAX(block_id+blocks-1) HWM FROM DBA_EXTENTS GROUP BY file_id) b,dba_data_files c where a.file# = b.file_id(+) And (a.bytes - HWM * a.block_size) >0 and a.FILE#=c.file_id and c.tablespace_name='&tablespace_name' order by 6 desc;

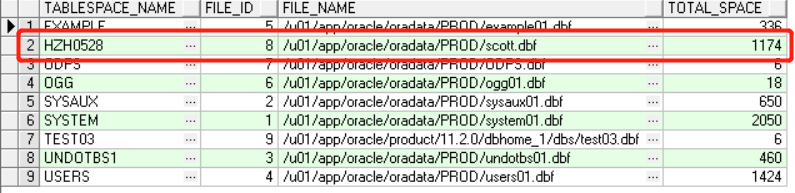
16.resize数据文件
alter database datafile 8 resize 1142M;
17.查看现在的表空间使用率,测试所用数据量较小,不太能体现压缩带来的数据变化,但是具体流程大体这样

18.查看数据文件大小变化
SELECT tablespace_name, file_id, file_name, round(bytes / (1024 * 1024), 0) total_space FROM dba_data_files ORDER BY tablespace_name;