一、 一个日志文件,行的信息中包括调用的接口名,如何找出日志文件中访问量在前10位的接口。
apis = [] # 定义空列表用于存放从日志行中取出的接口名
with open('Log.txt') as fr: # 以行读取日志文件,并在行中截取出接口名存放至apis列表中
for line in fr:
api = line.split(' ')[4]
apis.append(api)
api_set = list(set(apis)) # 为了在统计每个接口名个数时减少循环次数,把接口名列表做了去重处理
d = {} # 定义空字典用于存放类似“接口名:5”这样的键值对
for api in api_set: # 给每个接口名统计次数并成对存放在字典d里
d[api] = apis.count(api)
sorted_api = sorted(d.items(),key = lambda item : item[1],reverse = True ) # 用sorted方法对字典以value值倒叙排序
print(sorted_api[:10]) # 打印出倒序序列中的前十项
重点介绍 sorted 方法。
sorted方法可用来对字典按key值或value值排序的。sorted(iterable,key,reverse),sorted一共有iterable,key,reverse这三个参数,其中iterable表示可以迭代的对象,例如可以是dict.items()、dict.keys()等,key是一个函数,用来选取参与比较的元素,reverse则是用来指定排序是倒序还是顺序,reverse=true则是倒序,reverse=false时则是顺序,默认时reverse=false
1.sorted方法按key值对字典排序
mylist =[A,B,A,C,C,A,D,B,A,C,C,E,F,G,A]
set_list = list(set(mylist))
d = {}
for k in set_list:
d[k] = mylist.count(k)
sorted_list = sorted(d.keys())
print(sorted_list)
结果是:[A, B, C, D, E, F, G]
可以看出,sorted(d.keys())返回了key为元素的列表,value不见了,若想倒序 sorted(d.kyes(),reverse=True)
2.sorted方法按value值对字典排序
要对字典的value排序则需要用到key参数并对其使用lambda表达式的方法。
mylist = [A,B,A,C,C,A,D,B,A,C,C,E,F,G,A]
set_list = list(set(mylist))
d = {}
for k in set_list:
d[k] = mylist.count(k)
sorted_list = sorted(d.items(), key=lambda item:item[1], reverse=True)
print(sorted_list)
结果是: [(A, 5), (C, 4), (B, 2), (D, 1), (E, 1), (F, 1), (G, 1)]
可以看出结果是以字典的每一个“键值对”为元素的列表,字典里原来的信息没有丢掉。
这里的d.items()实际上是将字典d转换为可迭代对象,迭代对象的元素为原字典的一个键值对元组,如(A,5),items()方法将字典的元素转化为了元组。
而这里key参数也就是sorted方法的第二个参数对应的lambda表达式lambda item:item[1],意思则是选取元组中的第二个元素(即 (A,5)中的5)作为比较参数(如果写作key=lambda item:item[0]的话则是选取第一个元素(即(1,5)中的1)作为比较对象,也就是key值作为比较对象。
lambda x:y中x表示输出参数,y表示lambda函数的返回值
所以采用这种方法可以对字典的value进行排序。注意排序后的返回值是一个list,而原字典中的名值对被转换为了list中的元组。
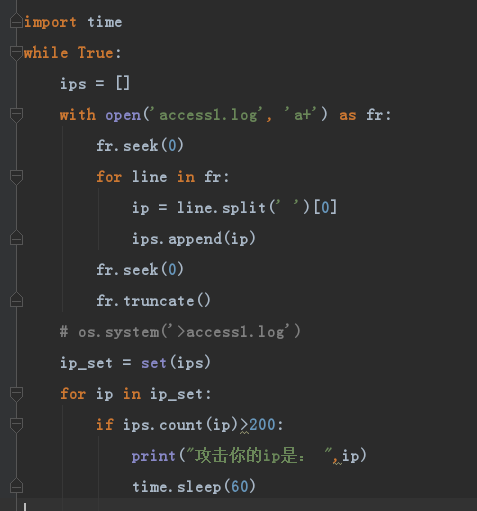
二、监控日志文件中可疑的ip地址 (如每分钟访问量超过200次的IP要处理掉)
思路和用到的技术点:
以一分钟为单位时间段, time 模块
先读日志文件, 读文件
在每行中截取出IP字段统一存放, 字符串拆分 list追加
统计每个IP的数量与200比较 列表去重优化,for 循环, count()方法
日后遇到实际问题还会继续在此总结。。。