二叉树的问题分析
二叉树是有问题的
二叉树需要加载到内存,假如二叉树的节点比较少,那么没有什么问题,假如二叉树的节点非常多(比如一亿),那么就会出现问题
1、在构建二叉树的时候,需要进行多次的I/O操作,节点海量,构建二叉树的时候,速度会有影响
2、节点海量,也就造成二叉树的高度非常高(2n-1),这样会降低操作速度
即使树的查找效率很高,也顶不住海量节点,更别说其他的增删改操作了
这样的情况在理论上是会发生的,发生这样的问题,根本原因在于二叉树它只有两个节点
为了解决这个问题,我们提出了多叉树。非常经典的多叉树:2-3树、2-3-4树、B树、....
多叉树有个好处,就是可以通过重新组织节点,减少树的高度,这样就能够对二叉树进行优化,比如下面的2-3树
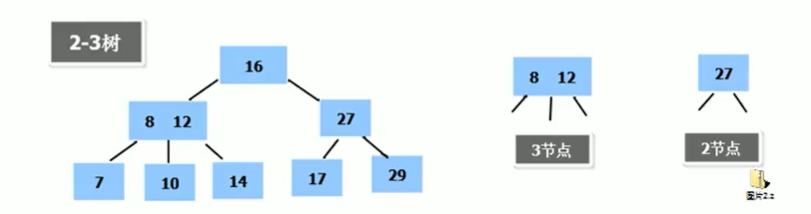
2-3树
基本概述
2-3树其实就是一个比较简单的B树结构,它有如下特点:
1、2-3树的所有叶子节点都在同一层(只要是B树,都满足这个条件)
2、有两个子节点的节点叫做二节点,二节点要么没有子节点,要么有两个子节点
3、有三个子节点的节点叫做三节点,三节点要么没有子节点,要么有三个节点
4、2-3树是由二节点和三节点构成的树
2-3树原理解析
现在有一个数列:{16,24,12,32,14,26,34,10,8,28,38,20},我们要将这个数列构建为2-3树
在讲解2-3树之前,要明确一个事情:在多叉树中,一个节点中可能有多个值,这多个值共同构成了多叉树
节点插入规则:
1、2-3树的所有叶子节点都在同一层(只要是B树都满足这个条件)
2、有两个子节点的叫2节点,2节点要么有两个子节点,要么没有
3、有三个子节点的叫3节点,3节点要么有三个子节点,要么没有
4、按照规则插入一个数到某个节点时,不能满足上面的三个要求,那么就应该拆
首先向上拆,假如上层满了,那么拆本层,拆后仍然需要满足上面三个条件
5、对于三节点的子树的值大小仍然遵守BST(二叉排序树)的规则
也就是说,2-3树仍然是顺序的,仍然是保证BST的顺序的,那么分别来说一下二节点和三节点的BST的例子
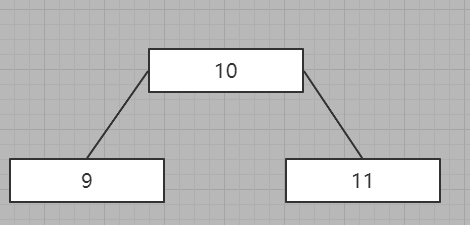
二节点:
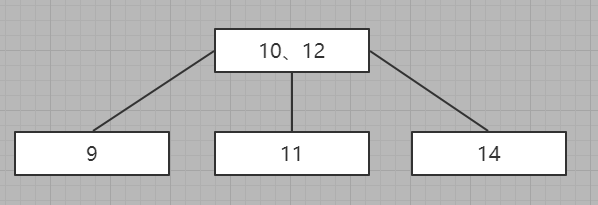
三节点:
二节点还比较好理解,但是三节点说一下
子节点的最左边小于父节点的最小值,子节点的中间节点的权在父节点的两个权值的中间,子节点右边大于父节点的最大值
2-3树构建过程
现在有一个数列:{16,24,12,32,14,26,34,10,8,28,38,20},我们根据这个数列构建为一个2-3树
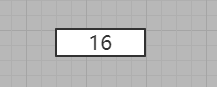
1、插入16节点
2、插入24节点
假如没有下一层,那么优先插入当前层,比较之后发现当前层还是双节点,所以直接插入变为三节点
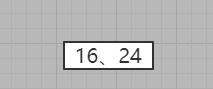
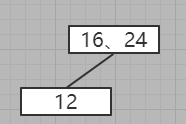
3、插入12节点
没有下一层则有限插入当前层,比较之后发现当前层已经为三节点
考虑向上拆分,发现没有上一层
向下插入,但是向下插入,首先插入到16的左子节点
插入之后发现不符合规则:所有的叶子节点全都都要在同一层,所以要做拆分,我们将上一层根据BST规则进行拆分,得到如下结果
最后形成结果
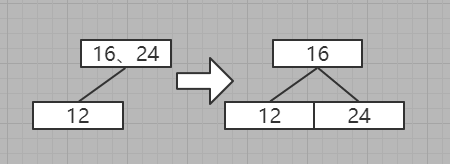
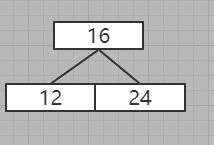
4、插入32
假如没有下一层,那么优先考虑插入本层,所以应该插入到24的右侧
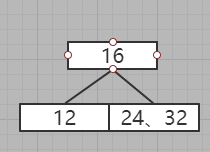
5、插入14
与16比对发现小于16,那么假如没有下一层则插入到本层 ,但是发现存在下一层,那么进入下一层
再次比对,优先插入本层,发现可以插入到12,则插入到12右边
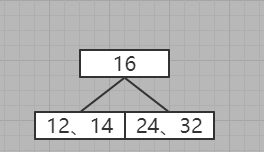
6、插入26
发现有下一层,进入下一层
与各个节点比对,发现可以插入到24右侧,但是发现24所在的节点已经是三节点了
优先向上拆分,发现上层未满,则根据BST规则进行拆分,也就是将26拆分上去了
发现不满足2-3树的三节点规则:三节点要么没有,要么全有,所以将其进行拆分
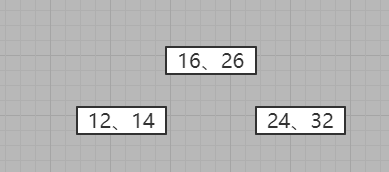
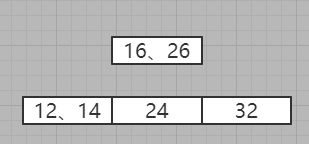
7、插入34
发现有下一层节点,进入下一层节点
优先插入本层
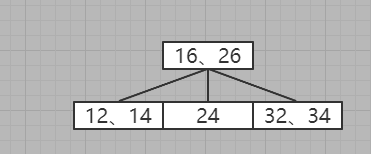
8、插入10
发现有下一层节点,那么进入下一层
比对后发现,可以插入到12左侧,但是12所在的节点已经为三节点
优先考虑向上拆分,但是上层节点已经为三节点了
必须向下进行插入,经过BST平衡后得到
发现不满足B树的规则:所有的叶子节点全部都在一层,所以根据BST规则拆分上一层的上一层,得到
发现树平衡了,其实就是将26拆分出来,将24所在的节点位26的左子节点,32所在的节点为26的右子节点
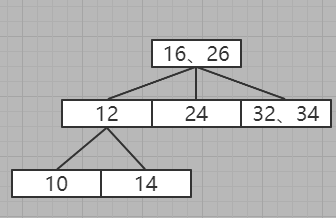
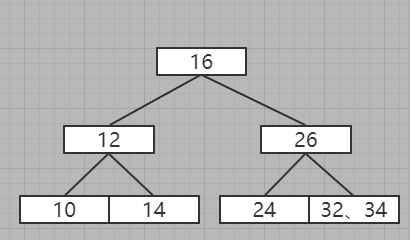
9、插入8
进入到最后一层,插入
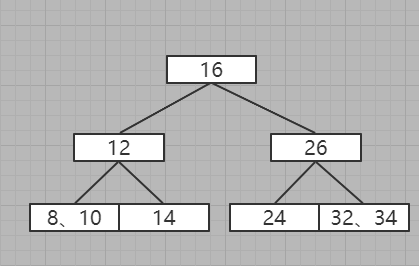
10、插入28
进入到最后一层,进行插入,发现32所在的节点已经为三节点
优先考虑向上拆分,发现可以拆分,则拆分,最终结果为
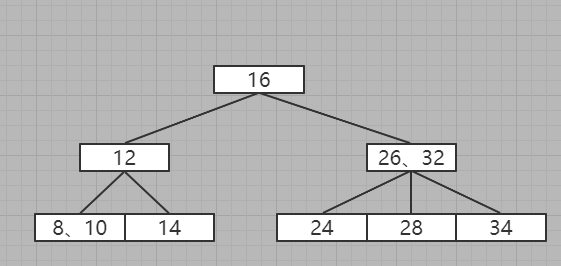
11、插入38
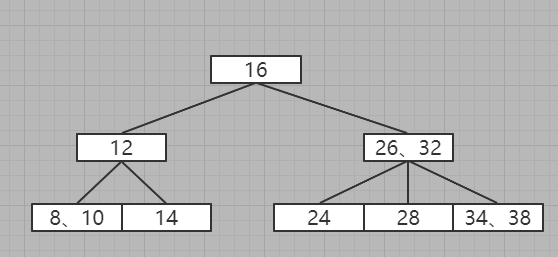
12、插入20
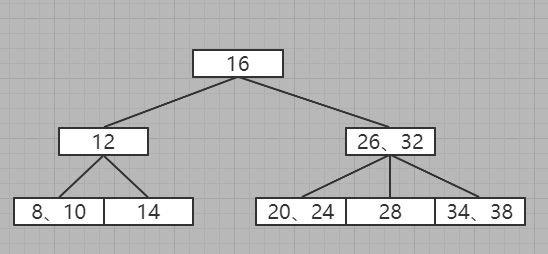
2-3-4树
这个也和2-3树差不多,也是一种B树,只不过它多出来了四节点,这个就不多BB了
B树和B加树和B*树
B树
B树
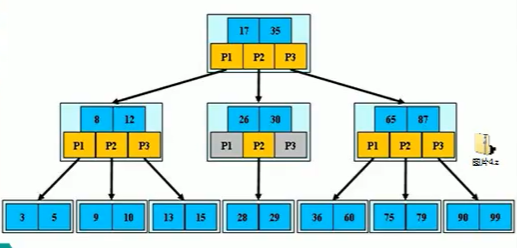
我们看这个黄色的P,其实就是代表节点
B树,Balanced,平衡树。
有人写作B-tree,其实就是B树,但是有人翻译为B-树,这是很让人产生误解的,会让人一位B-树是一种树,而B树是另外一种树,其实他俩都是一个
前面我们已经讲解了2-3树,其实这就是一种B树,我们在讲解MySQL的时候,经常说过某种索引是基于B树,或者B+树的
B树有一些说明:
1、B树的阶:节点的最多子节点的个数
比如2-3树的阶就是3,2-3-4树的阶是4
2、B-树的搜索:从根节点开始,对节点内的关键字序列进行二分查找,假如查到则结束,假如查不到进入到关键字所在范围的儿子节点重新进行二分查找,重复。直到找到节点或者最终的指向为null结束
每一个节点可能会存放一个集合,比如2-3树可能在一个节点里存放1或者2个数据,2-3-4树还可能存放3个数据,甚至其他的B树一个节点里面可能存放更多的数据
在这种情况下,一个节点里面的数据量就需要查找,查找完成之后假如发现数据存在这个节点,那么直接退出就好
假如没有查询到数据,那么就进行判断,数据大于/小于其中的某个范围,比如我们在2-3树的时候,回想一下三节点
三节点的中间节点是小于节点中左边的数据,但是大于右边的数据,类似这种情况就可以进行向下进行查询
3、关键字集合分布在整棵树中
也就是说你要寻找的数据可能存在叶子节点,也可能存在非叶子节点
所以搜索可能在非叶子节点就结束了
4、搜索性能等价于在关键字全集内做一次二分查找
B+树
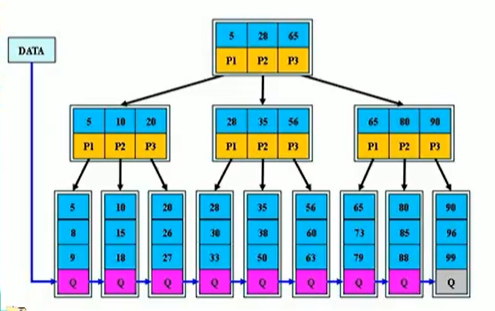
B+树是B树的变体,也是一种多路查找树,但是和B树有所不同
1、所有的关键字都出现在叶子节点中的链表
也就是说,非叶子节点不在存放数据了,数据只能在叶子节点出现,比如5,根节点的5代表是索引,而不是数据
2、链表中的关键字也是有序的
比如我们看第一个5、8、9,这个链表就是有序的
然后里面的Q是指向下一个叶子节点,下一个叶子节点是10、15、18,.....
3、我们的非叶子节点其实就相当于叶子节点的索引,这个索引叫做稀疏索引
就是说,我们要寻找一个数据最终是要寻找叶子节点,因为非叶子节点不存放数据,但是非叶子节点是有用的
它的用处就是便于我们去寻找叶子节点,那么这些非叶子节点就是叫做稀疏索引
4、我们所有的叶子节点才是存储数据的索引,这个也叫稠密索引,也可以叫做聚合索引
所有的关键字都出现在叶子节点的链表里面,也就是上图中,我们这一圈带Q的链表
数据只能存在叶子节点这种形式叫做稠密索引,我们也称为聚合索引
在这种情况下,叶子节点之间都使用指针相连接(我们看到的Q就是指向下一个链表的指针),那么在这种情况下更加适合范围查找
5、更加适合文件索引系统
6、B树和B+树各有自己的应用场景,不能说B+树一定比B树好
其实B+树简直是一个天才设计,简单来讲,它可以将一个链表分割成几段来进行查找,还是以上面的图为例子,只不过这次我们使用链表来进行显示:

我们再看B+树
假如我们想要找到10这个数据,在链表中,我们只能从头开始找,但是在B+树中,我们只需要先找到分割的段,然后就直接找到了数据
所以现在可以理解,为啥B+树的搜索效率如此之高,因为它是将原来的单链表直接分割成了几段链表,这样查询效率就大大提升了
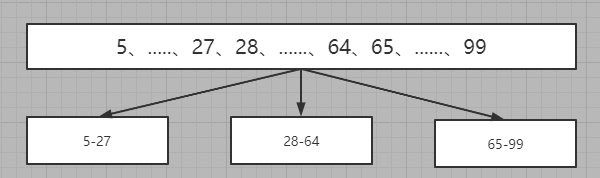
那么它的思想是什么呢?假如我现在的数据是5到99,我现在想要将这些数据进行分段,比如分成三段
那么我就说5->27是一段,28->64是一段,65->99是一段,那么根据这个就分为了三个部分
我仍然不满意,我说,要将这三段再平均分,那就是一段分三段,共九段
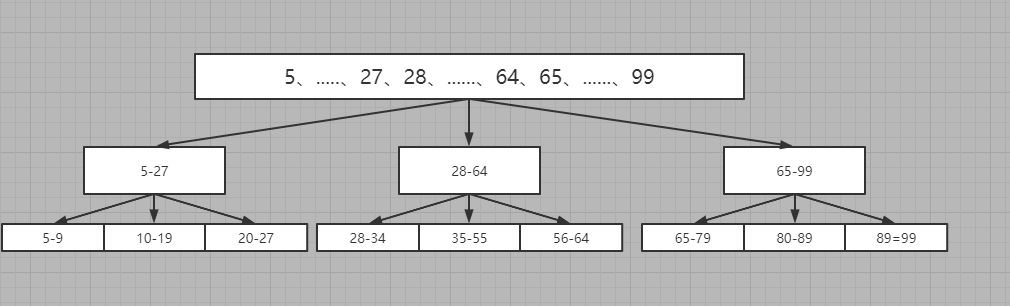
到这里我说差不多了,现在一个链表的长度就不用很长了,那么在查找的时候也十分方便(链表就不画了)
那么我们说,原理图画完了,那么具体落地的程序应该怎么去设计呢?
其实十分简单,我们不需要知道每一段的结束点在哪里,我们只需要知道每一段的开始点在哪里,因为我们是链表,我们肯定是需要从开始点开始遍历的,区别就是开始点在哪里,这也就是我们为什么没有标注结束点的原因
如果还不懂那么看一眼新华词典,我们想要查询某一个词,在目录上肯定会告诉你这个词在哪个页面上,比如第196页,这不就相当于直接砍掉了我们之前的195页么
但是在第196页,我们还是需要一个一个去寻找,就相当于我们的链表一样。假如没有B+树这个目录,我们假如只有链表,就需要从第一页找到第196页
B+树也不是没有缺点的,它的索引维护起来十分困难,光看这个图你就应该了解了所以B+树一般用于放在那些不经常进行变动的数据上,它的查找是十分快的,但是假如我们说要放到一个经常变动的数据项上面,一个索引的维护就足够把性能降低了
B*树
B星树是B+树的变体,在B+树的非根和非叶子节点再次增加一个指向兄弟的指针
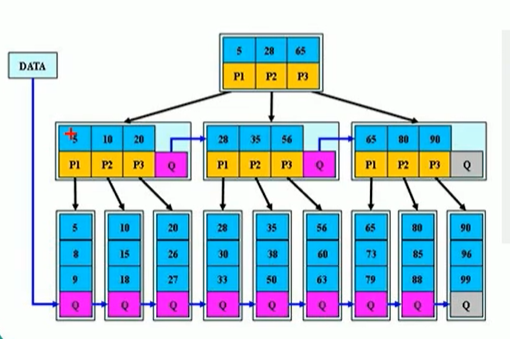
1、B*树定义了非叶子节点关键字个数至少为(2/3)xM,也就是说块的最低使用率为2/3,而B+树的块的最低使用率为B+树的1/2
2、从第一个特点我们可以知道,B*树分配新节点的概率比B+树低,空间使用率更高