为什么要有图
为什么要有图
前面我们看了线性表和树
我们知道线性表局限于只有一个前驱和后继的关系
树也只能有一个直接前趋,但是可以有多个后继
但是这里有一些情况,假如我们需要使用多个直接前趋该怎么办呢?比如我们描述多对多关系的时候
假如说现在有学生和老师这种情况,学生要有多个老师,老师也有多个学生
当我们描述这种多对多关系,就需要图
图的基本概述
图的基本概述
图是一种数据结构,其中一个节点可以有零个或者多个相邻的元素
两个节点之间的连接称为边
节点也可以称为顶点
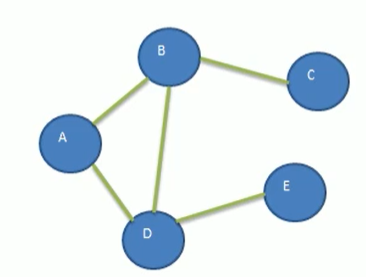
我们看上面的图,这个就是图,其中两个顶点的相连为边,比如BD
图的常用概念
1、顶点:也就是节点,上图的A、B、C、D、E
2、边:两个节点的链接,比如AB
3、路径:和无向图还是有向图有关,比如上图从D到C的路径可以为:D->B->C,或者D->A->B->D
4、无向图:上图就是无向图,也就是顶点的连接没有方向,比如A和B,可以从A->B,也可以从B->A
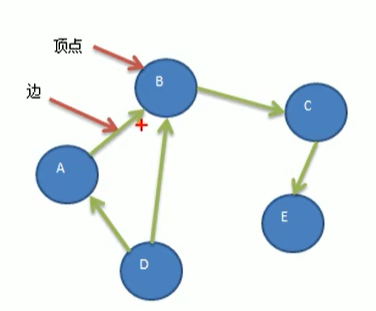
5、有向图:顶点之间有方向
比如这里
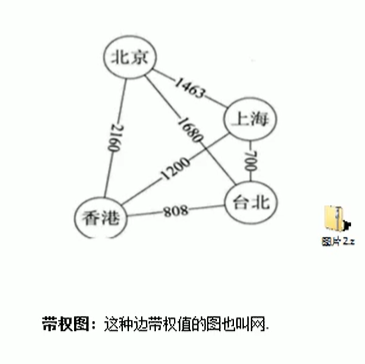
6、带权图:边带有权值,带权图也叫做网
图的表示方式
1、二维数组表示,我们称为邻接矩阵
2、链表表示(或者数组+链表),我们称为邻接表
邻接矩阵
邻接矩阵是表示图形中顶点之间相邻关系的矩阵,对于n个顶点的图来说,矩阵的row和col表示的是1...n个点
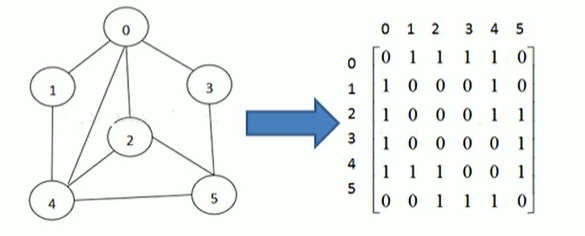
在上图中,0代表不直接联通,1代表可直接联通
比如0和0的值就是0,代表不联通,0和1之间是1,代表可联通
但是有一些虽然不可以直接联通,但是是可以通过其他节点间接连通的
邻接表
邻接矩阵其实有个缺点,它为所有的顶点都分配了n个边的空间,其实这里面有很多空间都浪费掉了,所以为了避免资源的浪费,我们推出了邻接表,邻接表只关心存在的边,不关心不存在的边,所以不存在空间的浪费
其实稀疏数组是可以对邻接矩阵进行优化的,但是转来转去太麻烦了,直接看邻接表
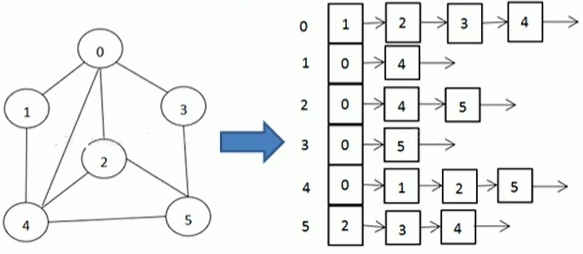
在上图中,是使用数组+链表构成的,其中在数组索引中,0代表标号为0的顶点,1代表标号为1的顶点,....
我们看标号为0的链表,举个例子。标号为0的链表上有1、2、3、4,这就代表顶点0可以和1、2、3、4直接相连
再举个例子,看标号为1的链表,它有0、4,代表顶点1可以和顶点0、4直接相连
注意,链表的节点不代表顺序,只代表和谁相连接
图创建和代码实现
思路分析
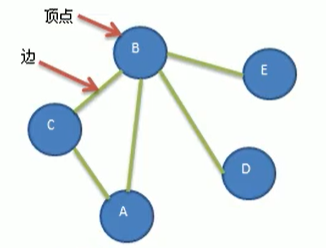
代码实现以上结构:
1、首先要存储这几个顶点,比如我们使用一个ArrayList来存储
2、图的关系我们使用二维数组来保存这个矩阵int[][] edges,1代表能够直连,0代表不能直连
代码实现
package com.howling;
import java.util.ArrayList;
import java.util.Arrays;
public class GraphDemo {
// 图中顶点的集合
private ArrayList<String> vertexList;
// 图中的顶点之间的连接关系,二维矩阵
private int[][] edges;
// 边的条数
private int numOfEdges;
/**
* 构造器
*
* @param n 代表图中顶点的个数
*/
public GraphDemo(int n) {
// 初始化二维矩阵
edges = new int[n][n];
// 初始化顶点的ArrayList
vertexList = new ArrayList<>(n);
// 因为还不知道边的关系,所以初始化为0
numOfEdges = 0;
}
/**
* 插入节点
*
* @param vertex 向集合中插入节点
*/
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
/**
* 获取图中的顶点个数
*
* @return
*/
public int getNumOfVertex() {
return this.vertexList.size();
}
/**
* 根据索引下标获取对应的值,索引取决于顶点添加的顺序
*
* @param index 对应的索引下标
* @return
*/
public String getValueByIndex(int index) {
return vertexList.get(index);
}
/**
* 添加两个顶点之间的边和边的权值
* 假如两个顶点之间可以直接链接就是1,不能直接链接就是0
*
* @param v1 顶点1
* @param v2 顶点2
* @param weight 边的权值
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
/**
* 获取边的个数
*
* @return 边的个数
*/
public int getNumOfEdges() {
return this.numOfEdges;
}
/**
* 获取两个顶点之间,边的权值
*
* @param v1 顶点1
* @param v2 顶点2
* @return 权值
*/
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
public void showGraph() {
Arrays.stream(edges).forEach(e -> System.out.println(Arrays.toString(e)));
}
public static void main(String[] args) {
int n = 5;
String[] VertexValue = {"A", "B", "C", "D", "E"};
GraphDemo graph = new GraphDemo(n);
// 添加顶点
Arrays.stream(VertexValue).forEach(graph::insertVertex);
// 添加边,A-B、A-C、B-C、B-D、B-E
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.showGraph();
}
}
图的遍历
图的遍历介绍
图的遍历,也就是对节点的访问。一个图中有许多节点,那么我们遍历这种节点需要一些策略
一般来讲,有两种遍历策略:
1、深度优先遍历
2、广度优先遍历
图的深度优先
图的深度优先思想(Depth First Search)
1、深度优先遍历,也就是从初始访问节点出发,初始访问节点可能有多个邻接节点
深度优先遍历的策略是首先访问第一个节点,再以这个被访问的邻接节点作为初始访问节点,继续下一次访问
2、我们可以看到,这种访问策略是优先向纵深方向,而不是对一个节点的所有邻接节点进行的横向访问
3、显然,深度优先是一个递归的过程
深度优先的算法步骤
1、访问初始节点v,并标记v节点已访问
2、查找v的第一个邻接节点w
2.1、假如w不存在(不直接连通),那么返回第一步,从v的下一个节点继续
2.2、假如w存在(直接连通)
2.2.1、假如w未被访问,则标记w已访问,并以w作为初始节点,进行第一步
2.2.2、假如w已经被访问,则查找节点v的其他邻接节点,转向第二步
深度优先举例
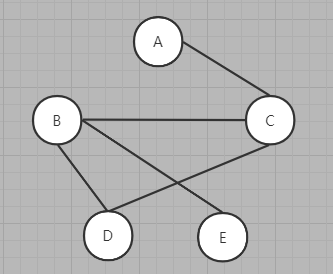
我们以上图来举例子,假如我现在从顶点A开始进行深度优先遍历
那么我首先规定,这几个节点的相邻顺序为:A->B->C->D->E
1、A为开始节点,标记为已遍历
2、A找到相邻节点B,发现与B不能直接连通,继续寻找下一个节点
3、A找到相邻节点C,发现可以与C直接连通,则进入C并标记C为已遍历
4、C找到相邻节点A,发现可以连通但是已遍历,继续寻找下一个节点
5、C找到相邻节点B,发现可以连通并且没有遍历,则进入B并标记B为已遍历
6、B寻找到A和C,发现A不可连通,C已经遍历,继续寻找下一个节点
7、B寻找D,发现D满足条件,则进入D并标记D为已遍历
8、D分别找到了A、B、C、E,发现均不满足条件,则返回上一层B
9、B继续寻找到E,发现E满足条件,进入到E并标记E为已遍历
10、E寻找到了A、B、C、D,发现均不满足条件,有没有其他节点,所以推出到上一层B
11、B发现没有其他节点,推出到上一层C
12、C继续寻找D、E,发现均不满足条件,没有了其他节点,退出到A
13、A继续寻找D、E,发现均不满足条件,没有其他节点,结束递归
图的深度优先代码实现
我们按照这张图来进行一次深度优先
package com.howling;
import java.util.ArrayList;
import java.util.Arrays;
public class GraphDemo {
// 图中顶点的集合
private ArrayList<String> vertexList;
// 图中的顶点之间的连接关系,二维矩阵
private int[][] edges;
// 边的条数
private int numOfEdges;
// 定义boolean数组,标记某个节点是否被访问
private boolean[] isVisited;
/**
* 构造器
*
* @param n 代表图中顶点的个数
*/
public GraphDemo(int n) {
// 初始化二维矩阵
edges = new int[n][n];
// 初始化顶点的ArrayList
vertexList = new ArrayList<>(n);
// 因为还不知道边的关系,所以初始化为0
numOfEdges = 0;
// 记录某个顶点是否被访问
isVisited = new boolean[n];
}
/**
* 返回没有遍历过的相邻节点的下标
*
* @param index 当前节点的下标
* @return 邻接节点的下标
*/
public int getNeighbor(int index) {
// 首先把自己标记为已经遍历
isVisited[index] = true;
// 从头开始遍历,找到能够连接并且没有标记为已遍历的节点
for (int i = 0; i < vertexList.size(); i++) {
if (i == index) {
continue;
}
// 假如找到一个能够连通的,并且没有遍历过的,那么就标记此节点已经遍历并返回对应的坐标
if (edges[index][i] > 0 && !isVisited[i]) {
return i;
}
}
// 假如找不到符合要求的节点,返回-1
return -1;
}
/**
* 图的深度优先遍历
*
* @param index 当前节点
*/
public void DFS(int index) {
// 首先输出当前节点
System.out.println(vertexList.get(index));
// 找到下一个相邻的、可以直接连通、没有遍历过的节点,递归
while (true) {
int neighbor = getNeighbor(index);
if (neighbor == -1) {
return;
}
DFS(neighbor);
}
}
public static void main(String[] args) {
int n = 5;
String[] VertexValue = {"A", "B", "C", "D", "E"};
GraphDemo graph = new GraphDemo(n);
// 添加顶点
Arrays.stream(VertexValue).forEach(graph::insertVertex);
// 添加边,A-C、B-C、B-D、B-E、C-D
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(2, 3, 1);
// 关系图
graph.showGraph();
System.out.println("-----------------------");
// 深度优先遍历,顺序应该为:A-->C-->B-->D-->E
graph.DFS(0);
}
}
因为东西太多,所以只放出部分,剩下的在之前都有实现
图的广度优先
图的广度优先思想(Broad First Search)
广度优先类似一个分层搜索的功能,需要使用一个队列以保持访问过的节点的顺序。
简单来说,比如说从A开始访问,那么我首先走一遍能和A进行互通的所有节点入队列。
等到A所互通的节点走完之后,就把A从队列里面剔除,从队列的头开始再次进行遍历,遍历到之后就入队列,循环往复。
这个时候,只要队列不为空,就说明还没有结束,假如队列为空,则代表全部都已经遍历完了
广度优先遍历算法步骤
1、访问初始节点v,将v标记为已经访问
2、节点v入队列,当队列非空时,继续执行,否则算法结束
3、查找v的相邻节点,全部入队列,并标记为已经访问
4、v的相邻节点全部遍历完成,则v出队列
5、根据队列中的第一个元素u进行查找相邻节点,循环往复
6、当队列为空时,算法结束
这个广度优先还不算很难,所以不举例子了
广度优先代码实现
按照广度优先遍历,这个最终输出的顺序应该为:A-->C-->B-->D-->E
package com.howling;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
public class GraphDemo {
// 图中顶点的集合
private ArrayList<String> vertexList;
// 图中的顶点之间的连接关系,二维矩阵
private int[][] edges;
// 边的条数
private int numOfEdges;
// 定义boolean数组,标记某个节点是否被访问
private boolean[] isVisited;
/**
* 构造器
*
* @param n 代表图中顶点的个数
*/
public GraphDemo(int n) {
// 初始化二维矩阵
edges = new int[n][n];
// 初始化顶点的ArrayList
vertexList = new ArrayList<>(n);
// 因为还不知道边的关系,所以初始化为0
numOfEdges = 0;
// 记录某个顶点是否被访问
isVisited = new boolean[n];
}
/**
* 返回没有遍历过的相邻节点的下标
*
* @param index 当前节点的下标
* @return 邻接节点的下标
*/
public int getNeighbor(int index) {
// 首先把自己标记为已经遍历
isVisited[index] = true;
// 从头开始遍历,找到能够连接并且没有标记为已遍历的节点
for (int i = 0; i < vertexList.size(); i++) {
if (i == index) {
continue;
}
// 假如找到一个能够连通的,并且没有遍历过的,那么就标记此节点已经遍历并返回对应的坐标
if (edges[index][i] > 0 && !isVisited[i]) {
isVisited[i] = true;
return i;
}
}
// 假如找不到符合要求的节点,返回-1
return -1;
}
/**
* 图的广度优先遍历
*
* @param index 开始的下标
*/
public void BFS(int index) {
// 队列
LinkedList<Integer> queue = new LinkedList<>();
// 首先将初始节点加入到队列中
queue.add(index);
while (!queue.isEmpty()) {
// 查找下一个相邻的、可以直接连通的、没有访问过的节点
int neighbor = getNeighbor(queue.get(0));
// 假如可以找到符合要求的节点
if (neighbor != -1) {
// 将指定的节点加入到队列中
queue.add(neighbor);
}
// 假如可以找到符合要求的节点,那么队列首部出队列并且打印
else {
Integer first = queue.removeFirst();
System.out.print(vertexList.get(first) + " ");
}
}
}
public static void main(String[] args) {
int n = 5;
String[] VertexValue = {"A", "B", "C", "D", "E"};
GraphDemo graph = new GraphDemo(n);
// 添加顶点
Arrays.stream(VertexValue).forEach(graph::insertVertex);
// 添加边,A-C、B-C、B-D、B-E、C-D
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(2, 3, 1);
// 关系图
graph.showGraph();
System.out.println("-----------------------");
// 深度优先遍历,顺序应该为:A-->C-->B-->D-->E
graph.BFS(0);
}
}
这里小小地修改了
getNeighbor,在返回节点之前也进行了一次的改变遍历的状态
广度优先和深度优先比较
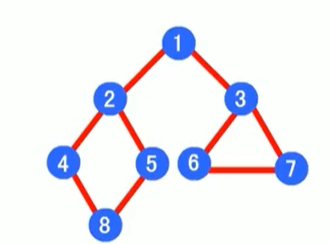
在上图中:
1、深度优先:1-->2-->4-->8-->5-->3-->6-->7
2、广度优先:1-->2-->3-->4-->5-->6-->7-->8