决策树算法,属于classification中的一种
算法思想:在数据中按照一定规则选取feature,然后根据该feature的值进行分类, 递归进行分类直到一个子类完全属于一个类别或者feature用尽。
算法输入数据样式:
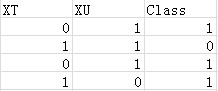 其中XT和XU就是feature, Class就是该条数据所属的类别。
其中XT和XU就是feature, Class就是该条数据所属的类别。
算法过程:
针对上面的例子对分类过程进行描述:
1. 假如第一次分类选取XT进行分类,那么会分成两类(因为XQ有两个取值0和1),如下图
 和
和
2. 检查子类是否满足算法终止条件:发现左边满足终止条件(Class标示的类别都属于同一类),右边不满足,所以继续进行分类
3. 由于在上一次选择feature的时候XT已经选过了,因此这次就只能选取XU了,对XU进行分类,XU=1时为上右图第一行,XU=0时为上右图第二行。
4. 都满足了算法终止条件
按照上述的算法,我们建立了一个决策树,而且分类方式是如下的形式:
XT = 1:
|XU = 1:0
|XU = 0:1
XT = 0:1
所以如果现在有一条数据XT=1, XU=1. 那么按照上面的决策树就可以判断出类别是0
算法关键点:1. feature的选取方式(本文选取最大信息增益法, 采用信息熵进行计算)
2. 算法递归结束条件(feature用尽&子类完全属于一个类别)
1. feature选取:遍历每一个feature,对数据进行分类后计算信息增益,找到使信息增益最大的feature作为该节点的分类feature。如何计算的理论请看wiki信息熵

java代码:计算一批数据的信息量
1 public double calEntropy(List<Map<String, String>> values) { 2 double res = 0.0; 3 Map<String, Integer> count = new HashMap<String, Integer>(); 4 for (Map<String, String> temp : values) { 5 String key = temp.get("Class"); 6 count.put(key, (count.get(key) != null ? count.get(key) + 1 : 1)); 7 } 8 int sum = values.size(); 9 for (Integer i : count.values()) { 10 double p = i / (double) sum; 11 res += -(p * Math.log(p) / Math.log(2.0)); 12 } 13 return res; 14 }
在有了计算数据信息量的方法后就可以对一批数据进行feature的选取了, 这里是采用选取最大信息增量的方法。
具体是:按照某个feature进行分类,分类之后分别计算子类的信息量,然后计算信息增益, 选取信息增益最大的分类。
//for selection private class SelectResult { public SelectResult() { type = null; currentFeature = null; } public Map<String, List<Map<String, String>>> type; public String currentFeature; } public SelectResult select(List<Map<String, String>> value) { SelectResult sr = new SelectResult(); double min = Double.MAX_VALUE; for (String str : heads) { if (flags.get(str) == false) { Map<String, List<Map<String, String>>> tem = new HashMap<String, List<Map<String, String>>>(); for (Map<String, String> temp : value) { if (!tem.containsKey(temp.get(str))) { tem.put(temp.get(str), new ArrayList<Map<String, String>>()); } List<Map<String, String>> d = tem.get(temp.get(str)); d.add(temp); } //calEntropy; double sum = 0; int totalsize = value.size(); for (List<Map<String, String>> t : tem.values()) { sum += (t.size() / (double) totalsize) * calEntropy(t); } if (sum < min) { min = sum; sr.currentFeature = str; sr.type = tem; } } } return sr; }
2. 算法终止:在递归的建立过程中,如何使算法进行终止:
public Node create(List<Map<String, String>> value) { Node root = new Node(); double uncertain = calEntropy(value); SelectResult sr = select(value); //1. current feature == null means that run out of feature ! //2. uncertain equals 0 means that we got a definitely pure class ! if (sr.currentFeature != null && uncertain != 0) { root.featureName = sr.currentFeature; root.subNodes = new HashMap<String, Node>(); flags.put(root.featureName, true); for (String t : sr.type.keySet()) { root.subNodes.put(t, create(sr.type.get(t))); } flags.put(root.featureName, false); } else { //the leaf node !!! root.value = getFinalType(value); root.end = true; } return root; }
---有个小问题是当feature用完后需要判断当前数据集的类型(因为已经不可再分了,必须得有一个类型)
/** * if run out of features, then call this function to get the final class ! * * @param value * @return */ private String getFinalType(List<Map<String, String>> value) { //choose the most common type as the final type !! Map<String, Integer> num = new HashMap<String, Integer>(); for (Map<String, String> temp : value) { String z = temp.get("Class"); num.put(z, num.get(z) != null ? num.get(z) + 1 : 1); } int max = -1; String maxv = ""; for (Map.Entry<String, Integer> x : num.entrySet()) { if (x.getValue() > max) { max = x.getValue(); maxv = x.getKey(); } } return maxv; }
最后附上打印的代码决策树的代码。
public void print(Node root, int level) { if (root.end == true) { System.out.println(root.value); } else { for (String temp : root.subNodes.keySet()) { tp(root.featureName, temp, level); print(root.subNodes.get(temp), level + 1); } } } private void tp(String f, String temp, int l) { if (l >= 1) { System.out.println(""); } for (int i = 0; i < l; i++) { System.out.print("|"); } System.out.print(f + " = " + temp + ":"); }
the end!