欢迎转载,转载请注明出处,徽沪一郎.
概述
Scala越来越流行, Spark也愈来愈红火, 对spark的代码进行走读也成了一个很普遍的行为。不巧的是,当前java社区中很流行的ide如eclipse,netbeans对scala的支持都不算太好。在这种情况下不得不想到编辑器之神emacs,利用emacs+ensime来打造scala编程环境。
本文讲述的步骤全部是在arch linux上,其它发行版的linux视具体情况变通。
安装scala
pacman -S scala
安装sbt
pacman -S sbt
安装ensime
yaourt -S ensime
添加如下代码到$HOME/.emacs中
(add-to-list 'load-path "/usr/share/ensime/elisp") (add-to-list 'exec-path "/usr/share/ensime") (require 'ensime) (add-hook 'scala-mode-hook 'ensime-scala-mode-hook)
运行sbt
sbt
首次运行sbt会解决依赖,下载必须的包。生成$HOME/.sbt/0.13目录,假设当前的sbt版本是0.13的话。
创建plugin.sbt
cd ~/.sbt/0.13 mkdir -p plugins cd plugins touch plugin.sbt
在plugin.sbt中添加如下内容
addSbtPlugin("org.ensime" % "ensime-sbt-cmd" % "0.1.2")
再次运行sbt, sbt会自动下载ensime plugin
下载spark源码
假设下载的spark源码解压在$HOME/working目录。到些为止,准备工作都差不多了,开始真正的使用吧。
生成.ensime文件
spark采用maven进行编译管理,所以不能像一般的sbt工程那样直接使用ensime generate。变通的方法如下
- 运行emacs, 在emacs中打开SparkContext.scala具体什么源文件不重要,这里只是一个比方
- 在emacs中运行ensime-config-gen,按照提示一步步执行,最终生成.ensime
如何回答ensime-config-gen中的每一个问题,下面的screenshot给出了明确的示例。
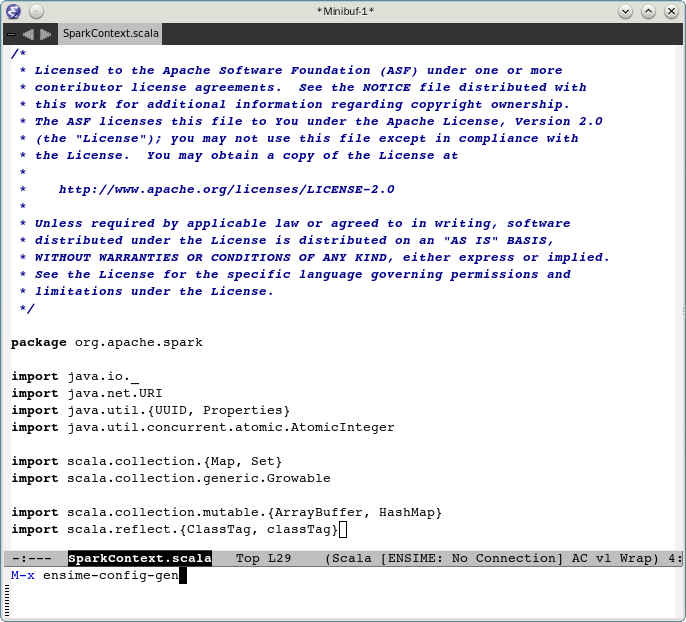
指定根目录

设定项目类型,选择yes

指定项目名称,spark

package的名称 org.apache.spark
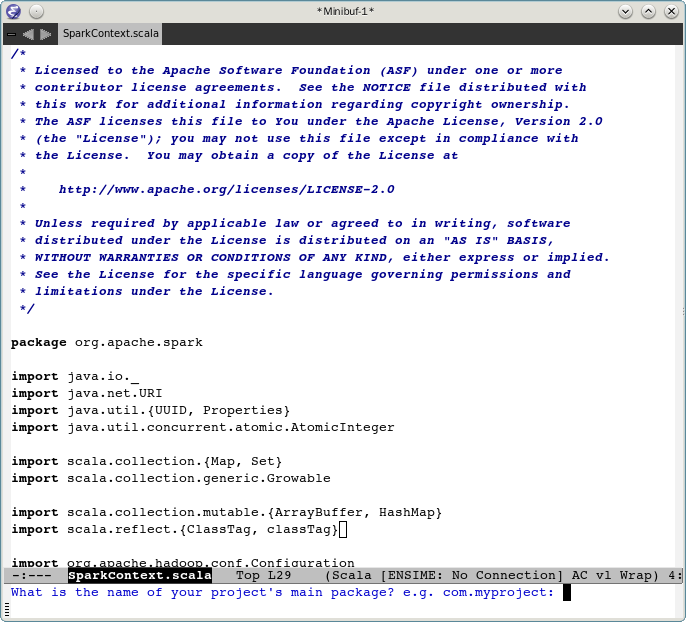
指定源文件目录
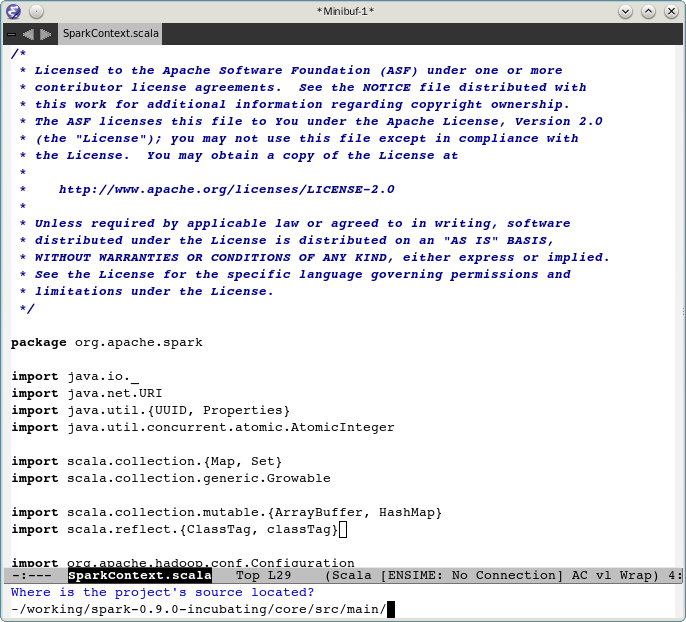
指定所依赖的包所在位置
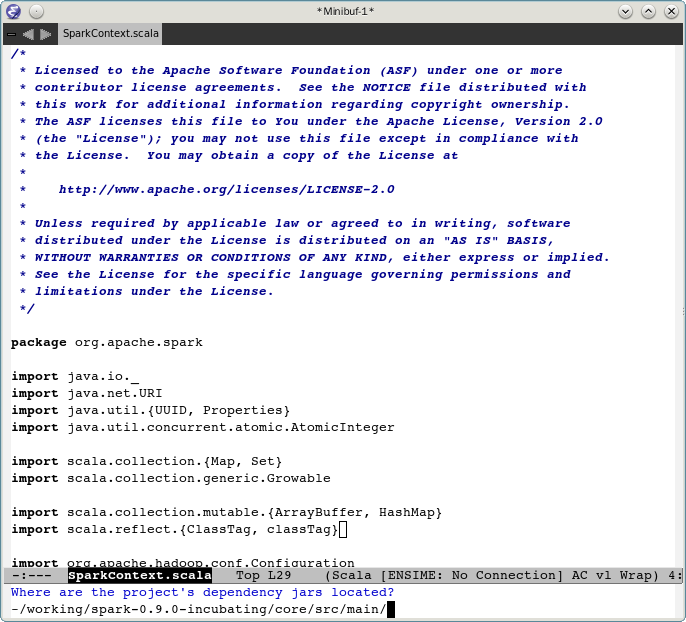
scala的标准库所在位置,选择 N

指定生成的classess被保存在哪个目录,选择默认
至此,配置完成,在spark-0.9.0-incubating/core/src/main能够打到.ensime文件
运行ensime
一旦生成了.ensime,就可以直接在emacs中唤起ensime了,M-X进入minibuffer,输入ensime

确认.ensime的位置

.ensime加载进来之后,状态栏上的"No Connection"提示信息消失,取而代之的是“spark analyzing",表明正在进行源文件的indexing.

ensime指令简明指南
ensime环境搭建完毕,具体指令的话请查看ensime官网上的manual.
由于我是进行源码走读,所以比较注重代码的调用和跳转。
将光标移动某一个类的起始定义处 如class SparkContext,然后调用快捷键c-c c-v i 列出SparkContext的变量与函数

c-c c-v p 列出当前package中的所有类
c-c c-v v 查找某一个方法或类
c-c c-v r 查看当前函数在哪些地方被调用,类似于source insight中的calling或eclipse中的calling hierarchy功能
alt-. 跳转到函数或类的定义处
alt-, 跳转到之前的位置