转自基于客户数据的银行信用卡风险控制模型研究,金融,风控,建模,实战,,评分,A (pythonf.cn)
基于客户数据的银行信用卡风险控制模型研究,金融,风控,建模,实战,以,某,制作,评分,A
一、知识准备
1.1 熟悉Python的数据分析库numpy、pandas和scikit算法库
1. 2 熟悉逻辑回归和随机森林算法
二、项目主题
在银行借贷场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,它衡量向别人借钱的人(受信人,需要融资的公司)不能如期履行合同中的还本付息责任,并让借钱给别人的人(授信人,银行等金融机构), 造成经济损失的可能性。一般来说,评分卡打出的分数越高,客户的信用越好,风险越小。
这些”借钱的人“,可能是个人,有可能是有需求的公司和企业。对于企业来说,我们按照融资主体的融资用途,分
别使用企业融资模型,现金流融资模型,项目融资模型等模型。而对于个人来说,我们有”四张卡“来评判个人的信用程度:A卡,B卡,C卡和F卡。而众人常说的“评分卡”其实是指A卡,又称为申请者评级模型,主要应用于相关融资类业务中新用户的主体评级,即判断金融机构是否应该借钱给一个新用户,如果这个人的风险太高,我们可以拒 绝贷款。
三、项目目标
-
能够使用RF算法对缺失值进行补充
-
能够掌握样本不平衡问题
-
熟练掌握评分卡的分箱操作
四、知识要点
4.1 原始数据

4.1.1 导库/获取数据
4.1.2 去重复值
4.1.3 填补缺失值
4.2 描述性统计
4.2.1 处理异常值

4.2.2 处理样本不均衡问题
样本个数:149152; 1占6.62%; 0占 93.38%

样本个数:278560; 1占50.00%; 0占50.00%
4.2.3 训练集和测试集
4.3 分箱处理
4.3.1 等频分箱
4.3.2 封装WOE和IV函数
- 为了衡量特征上的信息量以及特征对预测函数的贡献,银行业定义了概念Information value(IV)
- IV = (good% - bad%) * WOE
- 银行业中用来衡量违约概率的指标,中文叫做证据权重(weight of Evidence),本质其实就是优质客户 比上坏客户的比例的对数。WOE是对一个箱子来说的,WOE越大,代表了这个箱子里的优质客户越多。
- WOE = ln(good% / bad%)
4.3.3 用卡方检验来合并箱体画出IV曲线

4.3.4 用最佳分箱个数分箱,并验证分箱结果

.
.
.


4.4 计算各箱的WOE并映射到数据
对所有的特征进行计算箱子的WOE
# df:数据表
# col:列
# bins:箱子的个数
def get_woe(df,col,y,bins):
df = df[[col,y]].copy()
df["cut"] = pd.cut(df[col],bins)
bins_df = df.groupby("cut")[y].value_counts().unstack()
woe = bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
iv = np.sum((bins_df[0]/bins_df[0].sum()-bins_df[1]/bins_df[1].sum())*bins_df['woe'])
return woe
# 所有的WOE
woeall = {}
for col in bins_of_col:
woeall[col] = get_woe(model_data,col,"SeriousDlqin2yrs",bins_of_col[col])
woeall
model_woe = pd.DataFrame(index=model_data.index)
for col in bins_of_col:
model_woe[col] = pd.cut(model_data[col],bins_of_col[col]).map(woeall[col])
model_woe["SeriousDlqin2yrs"] = model_data["SeriousDlqin2yrs"]
model_woe #这就是建模数据
4.5 建模与模型验证
- C是正则化强度的倒数,C越小,损失函数就越小,模型对损失函数的惩罚越重
- solver:默认是liblinear,针对小数据量是个不错的选择,用于求解使模型最优化参数的算法,即最优化问题的算法
- max_iter:所有分类的实际迭代次数,对于liblinear求解器,会给出最大的迭代次数



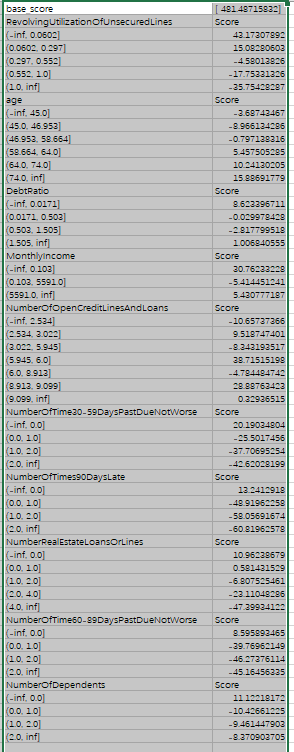
4.6 制作评分卡
- 评分卡中的分数,由以下公式计算:Score = A - B *log(odds)
- A与B是常数,A叫做“补偿”,B叫做“刻度
- log(odds)代表了一个人违约的可能性,逻辑回归的结果取对数几率形式会得到θX,即参数*特征矩阵,所以log(odds)其实就是参数。两个常数可以通过两个假设的分值带入公式求出,这两个假设分别是:
- 某个特定的违约概率下的预期分值
- 指定的违约概率翻倍的分数(PDO)
- 例如,假设对数几率为1/60时,设定的特定分数为600,PDO=20,那么对数几率为1/30时的分数就是620。带入以上线性表达式,可以得到:
- 600 = A - B*log(1/60)
- 620 = A - B*log(1/30)
最终打分结果 :