模块
模块能定义函数,类和变量,模块里也能包含可执行的代码。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。模块名同样也是一个标识符,需要符合标识符的命名规则,模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块
模块分为三种:
自定义模块
内置标准模块(又称标准库)
开源模块
模块导入
1)import 语句模块的引入
import 模块名1, 模块名2
提示:在导入模块时,每个导入应该独占一行
import 模块名1 import 模块名2
通过 模块名. 使用 模块提供的工具 —— 全局变量、函数、类
使用 as 指定模块的别名:如果模块的名字太长,可以使用 as 指定模块的名称,以方便在代码中的使用
import 模块名1 as 模块别名
注意:模块别名 应该符合 大驼峰命名法
例子:
hm01.py
title = "模块1" def say_hello(): print("我是%s" % title) #类 class Dog(): pass
hm02.py
title = "模块2" def say_hello(): print("我是%s" % title) #类 class Cat(): pass
hm03.py
import hm01 import hm02 hm01.say_hello() hm02.say_hello() dog = hm01.Dog() print(dog) cat = hm02.Cat() print(cat)
hm04.py 起别名
import hm01 as a import hm02 as b a.say_hello() b.say_hello()
坑:如果发现导入不了想要的模块,使用以下方法:
2)From…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中
例如,要导入模块 fib 的 fibonacci 函数
from fib import fibonacci
注意:
如果 两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数
- 开发时
import代码应该统一写在 代码的顶部,更容易及时发现冲突 - 一旦发现冲突,可以使用
as关键字给其中一个工具起一个别名
from hm01 import say_hello as a_say_hello from hm02 import say_hello a_say_hello() say_hello()
3)From…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的
from modname import *
注意:这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
from hm01 import * from hm02 import * print(title) say_hello()
4)模块的搜索顺序
Python 的解释器在 导入模块 时,会:
1、搜索 当前目录 指定模块名的文件,如果有就直接导入
2、如果没有,再搜索 系统目录
注意:在开发时,给文件起名,不要和系统的模块文件 重名
Python 中每一个模块都有一个内置属性 __file__ 可以 查看模块的完整路径
import random print(random.__file__) #查看模块路径 rand = random.randint(0,10) print(rand)
注意:如果当前目录下,存在一个 这个时候,random.py 的文件,程序就无法正常执行了!,Python 的解释器会 加载当前目录 下的 random.py 而不会加载 系统的 random 模块,
5)__name__ 属性
原则 —— 每一个文件都应该是可以被导入的,一个 独立的 Python 文件 就是一个 模块,在导入文件时,文件中所有没有任何缩进的代码都会被执行一遍!
实际开发场景
- 在实际开发中,每一个模块都是独立开发的,大多都有专人负责
- 开发人员 通常会在 模块下方增加一些测试代码
- 在模块内使用,而被导入到其他文件中不需要执行
__name__属性可以做到,测试模块的代码 只在测试情况下被运行,而在 被导入时不会被执行!
__name__是Python的一个内置属性,记录着一个 字符串- 如果 是被其他文件导入的,
__name__就是 模块名 - 如果 是当前执行的程序
__name__是__main__
# 导入模块 # 定义全局变量 # 定义类 # 定义函数 # 在代码的最下方 def say_hello(): print("你好你好,") #1、没有任何缩进的代码都会被执行,该代码会被另外一个导入本模块的文件执行! print("小明开发的模块") say_hello() #2、name属性讲解:如果直接执行当前模块,输出main,如果该模块被导入其他模块,在其他文件下输出模块文件名 print(__name__) # 根据 __name__ 判断是否执行下方代码 if __name__=="__main__": print("小明开发的模块") say_hello() import hm08 print("="*50)
time模块
时间表现形式
表示时间:时间戳、元组(struct_time)、格式化的时间字符串。
1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
#时间戳,时间戳是计算机能够识别的时间。
import time print(time.time()) #返回当前时间的时间戳,其中time.time(),第一个time为模块第二time为方法
2)格式化的时间字符串(Format String): ‘2017-04-26’
Import time print(time.strftime("%Y-%m-%d %x")) #Y代表year,m为mouth,d为day,x为时间 print(time.strftime("%Y:%m")) #年月日时间分割可以更改,此处用“:”分割
输出:2018-06-07 06/07/18
2018:06
3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
# 时间元组,结构化时间,是用来操作时间的。
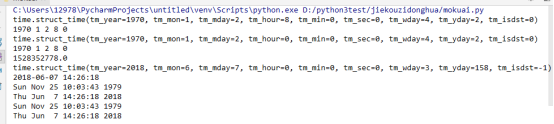
import time c = time.localtime() print(c) #通过操作结构化时间查看具体信息 y=c.tm_year print(y) m=c.tm_mon print(m) d=c.tm_mday print(d)

时间转换形式
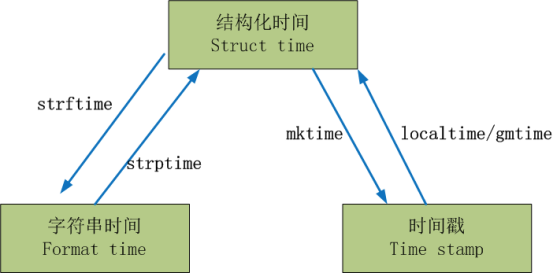
时间戳转化为结构化时间:localtime/gmtime
#时间戳转化为结构化时间localtime/gmtime #gmtime为世界标准时间,一般不使用。 #localtime为东八区时间,为我们所在的时间,常使用localtime import time c1=time.localtime(3600*24) print(c1) print(c1.tm_year,c1.tm_mon,c1.tm_mday,c1.tm_hour,c1.tm_min) c2=time.gmtime(3600*24) #gmtime print(c2) print(c1.tm_year,c1.tm_mon,c1.tm_mday,c1.tm_hour,c1.tm_min) #结构化时间转化为时间戳mktime print(time.mktime(time.localtime())) #字符串时间转化为结构化时间:strptime print(time.strptime("2018-06-07","%Y-%m-%d")) #结构化时间转化为字符串时间:strftime print(time.strftime("%Y-%m-%d %X", time.localtime())) #结构化时间转化为时间字符串:asctime print(time.asctime(time.localtime(312343423))) # 转化成距离1970-1-1 00:00:00 时间312343423秒的时间字符串格式 print(time.asctime(time.localtime())) # 转化成当前时间字符串格式 #时间戳转化为时间字符串:ctime print(time.ctime(312343423)) # 转化成距离1970-1-1 00:00:00 时间312343423秒的时间字符串格式 print(time.ctime()) # 转化成当前时间字符串格式 #其他方法 sleep(secs) #线程推迟指定的时间运行,单位为秒
时间加减
import datetime,time print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 print(datetime.datetime.now() ) print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(minute=3,hour=2)) #时间替换
1.random模块
import random print(random.random()) #输出大于0且小于1之间的小数 print(random.randint(1,5)) # 随机输出大于等于1且小于等于5之间的整数,[1,5] print(random.randrange(1,3)) # 随机输出大于等于1且小于3之间的整数,[1,3) print(random.choice([1,'2',[3,4]])) #随机取列表中的一个元素,结果为1或者2或者[3,4] print(random.sample([1,'2',[3,4]],2)) #随机取列表中任意2个元素 print(random.uniform(1,3)) #随机取大于1小于3的小数 iter=[1,2,3,4,5] print(random.shuffle(iter)) #直接输出,为Nome random.shuffle(iter) print(iter) #练习:随机生成验证码,字母和数字 import random def v_code(): code = '' for i in range(10): num = random.randint(0, 9) # 随机选择0~9一个数字 alf1 = chr(random.randint(65, 90)) # 随机选择A~Z一个字母 alf2 = chr(random.randint(97, 122)) # 随机选择a~z一个字母 add = random.choice([num, alf1, alf2]) # 随机选择num、alf1、alf2中一个 code = "".join([code, str(add)]) # 拼接依次选到的元素 return code # 返回验证码 print(v_code())

4.os模块
os模块是与操作系统交互的一个接口
import os os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd os.curdir # 返回当前目录: ('.') os.pardir #获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') # 可生成多层递归目录 os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() #删除一个文件 os.rename("oldname","newname") #重命名文件/目录 os.stat('path/filename') #获取文件/目录信息 os.sep #输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep #输出当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep #输出用于分割文件路径的字符串 os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") #运行shell命令,直接显示 os.environ # 获取系统环境变量 os.path.abspath(path) #返回path规范化的绝对路径 os.path.split(path) #将path分割成目录和文件名二元组返回 os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) #返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) #如果path是绝对路径,返回True os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
5.sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
6.Hashlib算法
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。
而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
import hashlib md5 = hashlib.md5() # md5只是hashlib摘要算法的一种,可以使用其他摘要算法。md5使用较多。 md5.update('how to use md5 in python hashlib?'.encode("utf8")) # 使用.encode("utf8")或者加b强制转换成二进制方式都不会报错,在python2中不需要 print(md5.hexdigest()) #分块多次调用update(),最后计算的结果是一样 md5 = hashlib.md5() md5.update(b'how to use md5 in ') md5.update(b'python hashlib?') print(md5.hexdigest()) md5.update("hello".encode("utf8")) #计算hello的hash值 print(md5.hexdigest()) #以16进制的方式打印经过md5摘要算法计算的hello的hash值

MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in '.encode("utf8")) sha1.update(b'python hashlib?') print(sha1.hexdigest())
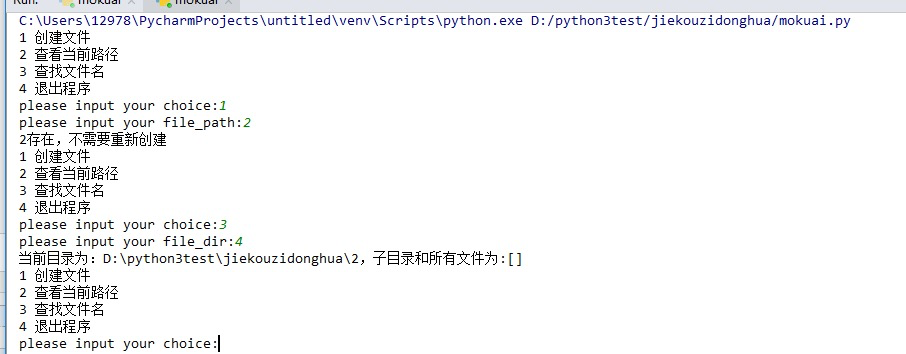
练习:
''' 小程序:根据用户输入选择可以完成以下功能: 创意文件,如果路径不存在,创建文件夹后再创建文件 能够查看当前路径 在当前目录及其所有子目录下查找文件名包含指定字符串的文件 ''' import os choice = { "1": "创建文件", "2": "查看当前路径", "3": "查找文件名", "4": "退出程序" } def mkdir(): file_path = input("please input your file_path:").strip() try: os.chdir(file_path) print("%s存在,不需要重新创建" % file_path) except: print("%s不存在,开始创建文件" % file_path) os.makedirs("%s创建完成" % file_path) def check(): file_name = input("please input your file_path:").strip() try: print("%s绝对路径为:%s" % (file_name, os.path.abspath(file_name))) except: print("%s不存在,开始创建文件" % file_name) def search(): file_dir = input("please input your file_dir:").strip() print("当前目录为:%s,子目录和所有文件为:%s" % (os.getcwd(), os.listdir(os.getcwd()))) while True: for key in choice: print(key, choice[key]) num = int(input("please input your choice:").strip()) if num == 1: mkdir() elif num == 2: check() elif num == 3: search() elif num == 4: break