
/*
时间:2018/09/17
功能:cookie
目录:
一: 概念
1 保存
2 存储
3 时间
4 目的
二: 结构
三: 查看
四: 获取
1 url
2 header
3 body
五: 禅道登录 - cookie
*/
一: 概念
1 保存
保存客户端,一般由浏览器存储。
2 存储
一般加密存储,因保存客户端,很难保证数据不被非法访问,所有cookies不宜保存敏感数据。
3 时间
cookie保存多长时间,有服务器决定的。
4 目的
下次访问网站直接使用cookie。
二: 结构
cookie ={ u'domain': u'.cnblogs.com', # 来源域名
u'name': u'.CNBlogsCookie', # cookie的名称 - 具有唯一
u'value': u'xxxx', # cookie的值
u'expiry': 1554959887, # 有效终止日期
u'path': u'/', #
u'httpOnly': True, #
u'secure': False} #
三: 查看

1 : 访问网站: https://www.baidu.com/
2 : 在Headers查看Cookies。
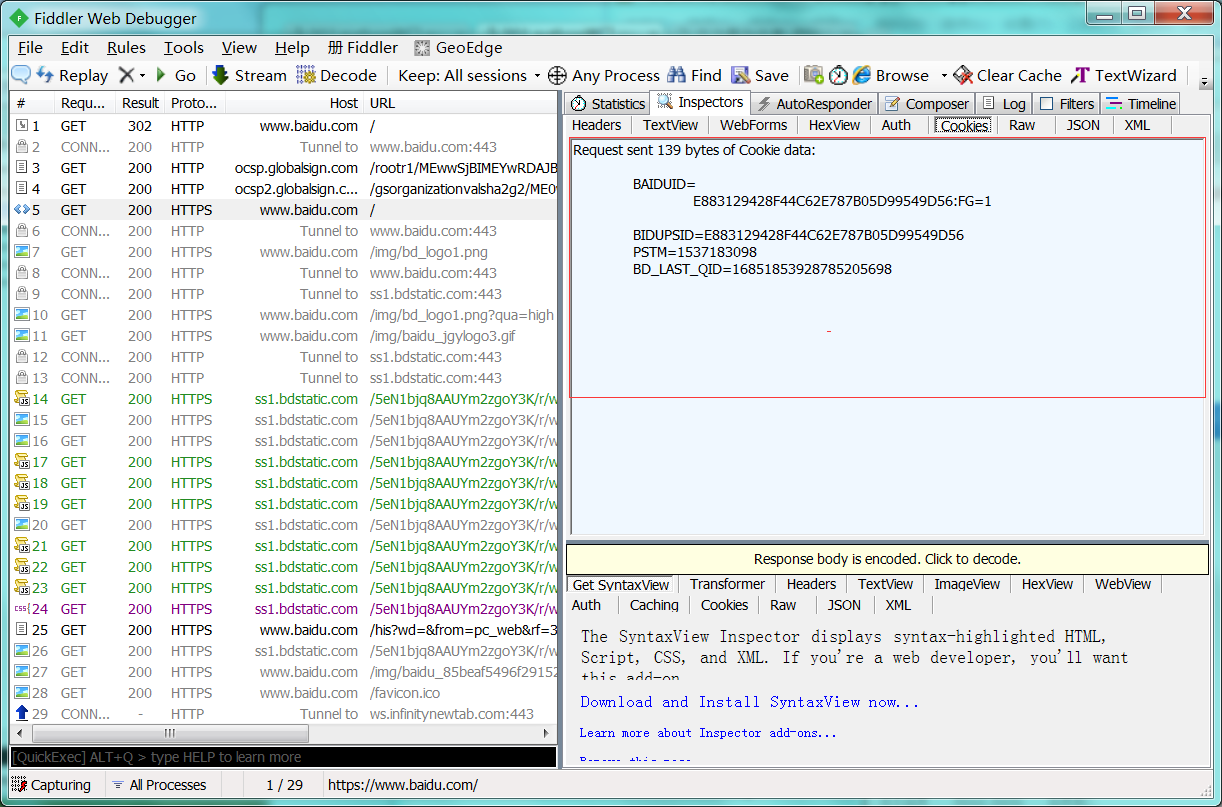
1 : 直接在Cookies里,直接查看Cookies。
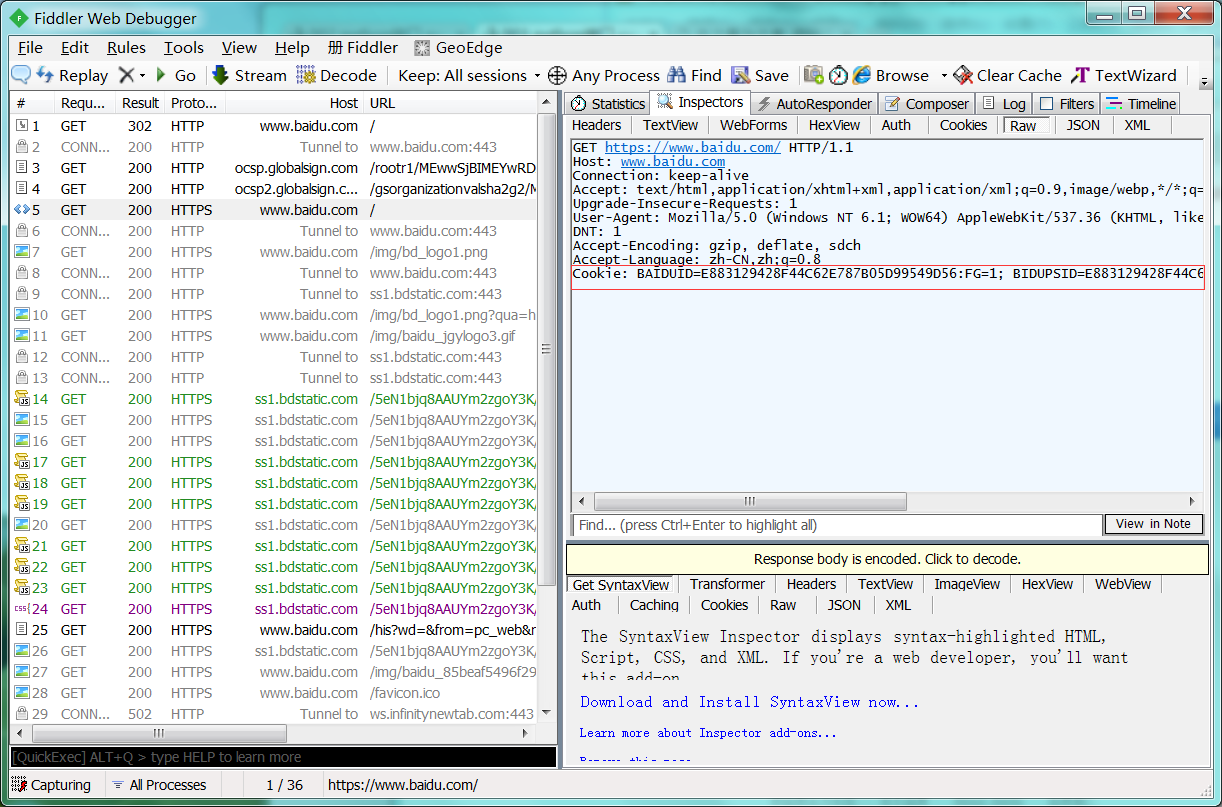
1 : 在Raw里查看Cookies。
四: 获取
1 url
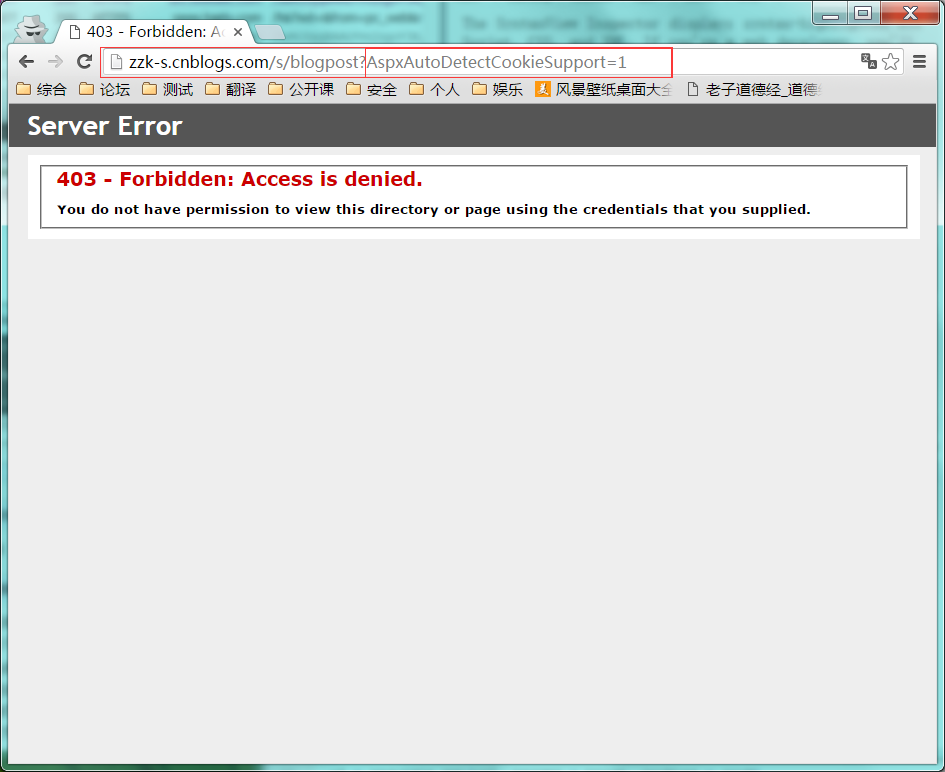
1 : 访问网站: http://zzk-s.cnblogs.com/s/blogpost。
2 : url变为: http://zzk-s.cnblogs.com/s/blogpost?AspxAutoDetectCookieSupport=1。?后面是cookie。
# coding:utf-8
import requests
# 请求首页
url = "http://zzk-s.cnblogs.com/s/blogpost"
r1 = requests.get(url)
# 获取cookie
strUrl = r1.url # 获取url
cookie = strUrl.split("?")[1] # 切片获取
# 请求搜索
param = {
"Keywords" : "001 python接口 get请求"
}
header = {
"Cookie" : cookie # 格式: name = value; name2 = value
}
r2 = requests.get(url, params = param, headers = header)
print(r2.text)
1 : 方法一 cookies放入headers头部传入。
2 : headers内cookie格式是,name = value; name2 = value。
# coding:utf-8
import requests
from urllib.parse import parse_qsl
# 请求首页
url = "http://zzk-s.cnblogs.com/s/blogpost"
r1 = requests.get(url)
# 获取cookie
strUrl = r1.url # 获取url
cookieList = strUrl.split("?")[1] # 切片获取
cookie = dict(parse_qsl(cookieList)) # 转为字典
# 请求搜索
param = {
"Keywords" : "001 python接口 get请求"
}
r2 = requests.get(url, params = param, cookies = cookie)
print(r2.text)
1 : 方法二 cookies=字典格式或者jar格式。
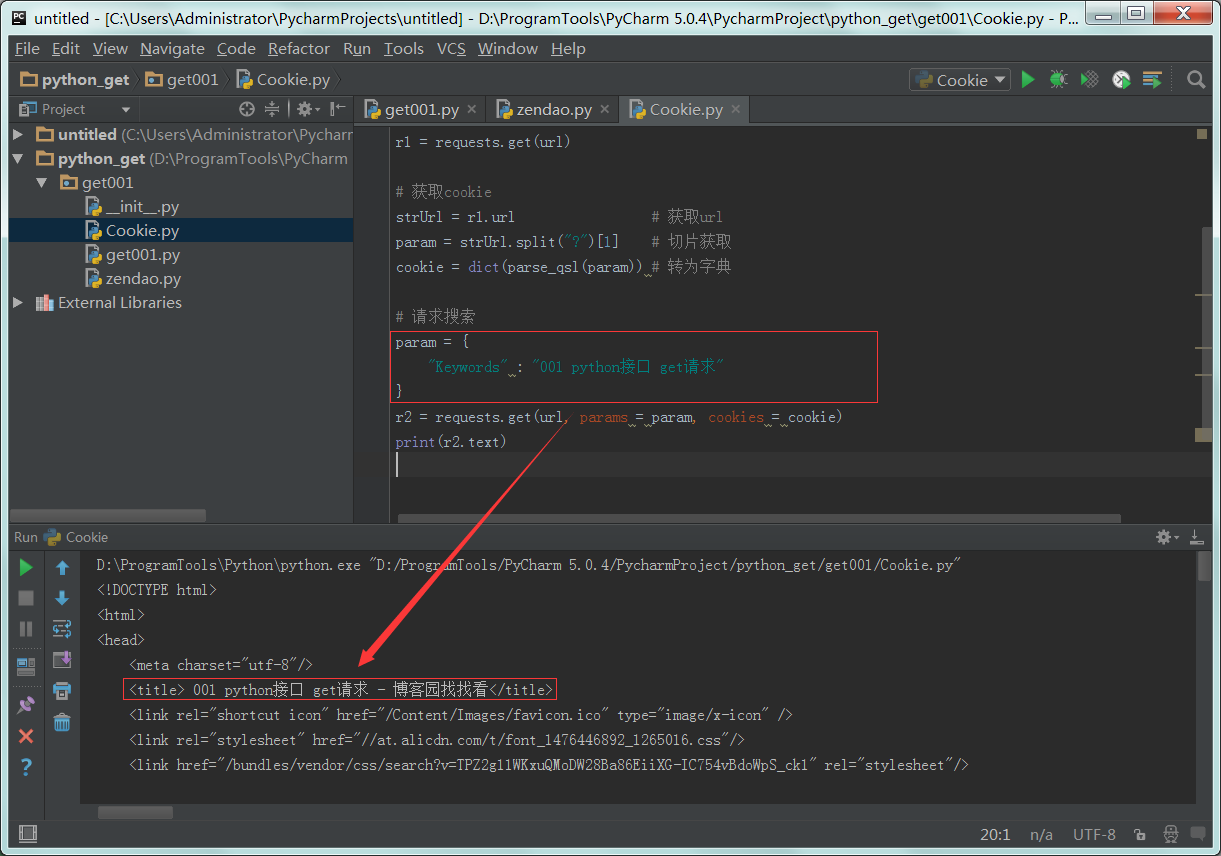
1 : 查看返回结果,使用cookie可以搜索成功。
2 header
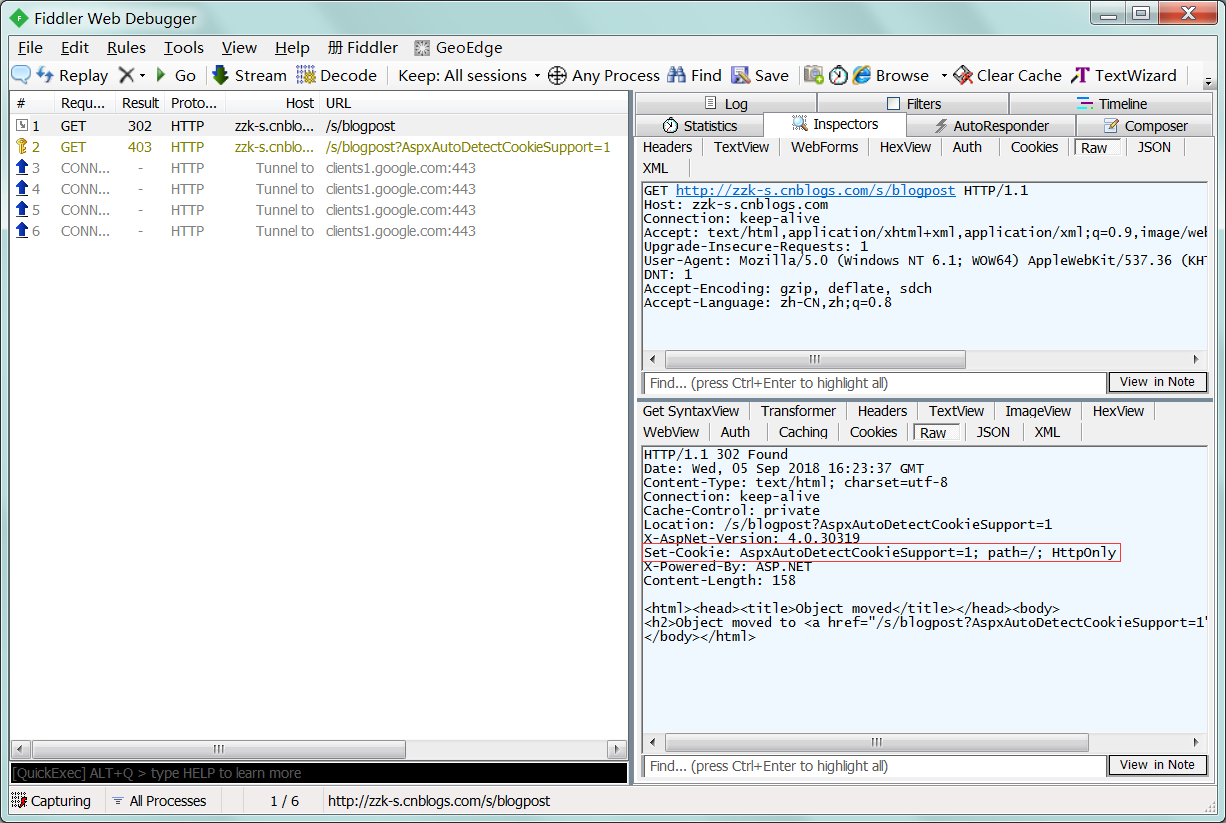
1 : 访问网站: http://zzk-s.cnblogs.com/s/blogpost。
2 : 查看重定位之前的页面信息 - header部分,有Set-Cookie,包含cookie信息。
# coding:utf-8
import requests
from urllib.parse import parse_qsl
# 请求首页
url = "http://zzk-s.cnblogs.com/s/blogpost"
r1 = requests.get(url, allow_redirects = False) # 禁止重定位
# 获取cookie
headerList = r1.headers
header = {
"Cookie" : headerList["Set-Cookie"]
}
# 请求搜索
param = {
"Keywords" : "001 python接口 get请求"
}
r2 = requests.get(url, params = param, headers = header)
print(r2.text)
1 : 使用python获取cookie,再发送搜索请求。
3 body
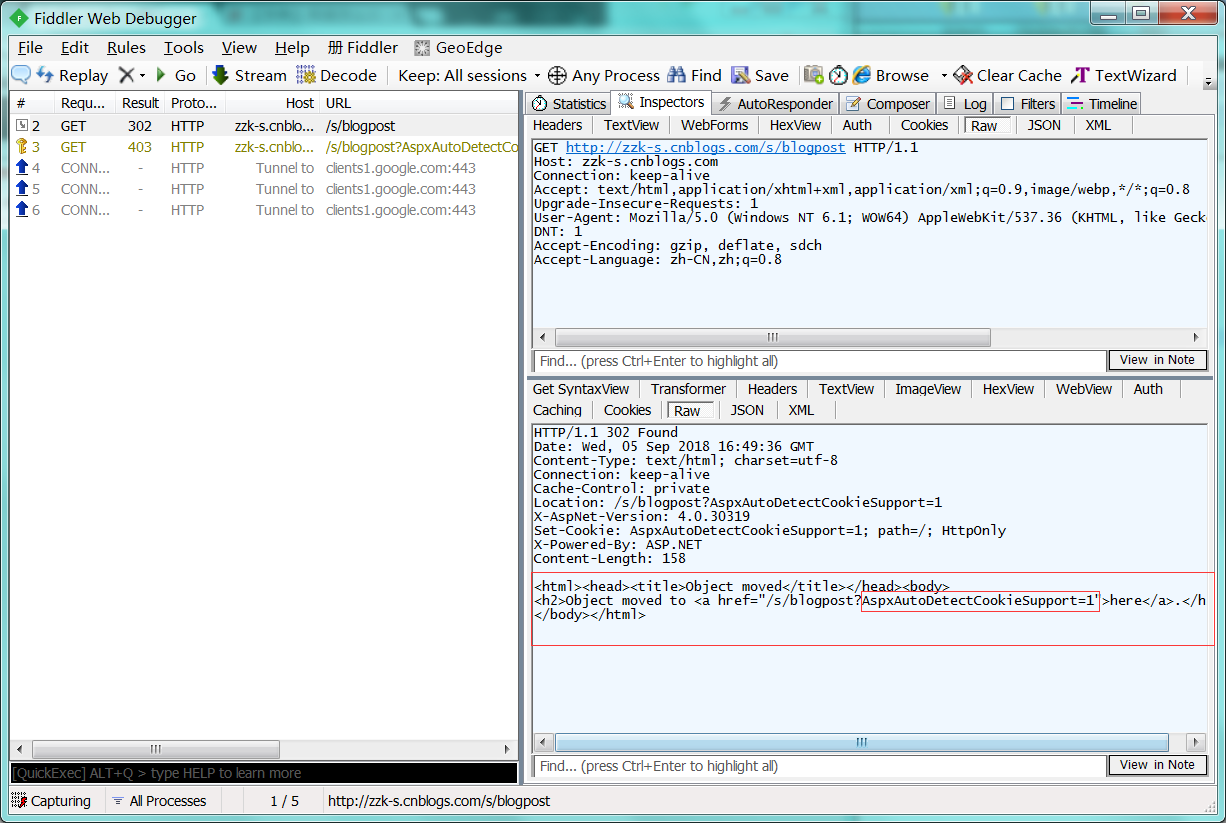
1 : 访问网站: http://zzk-s.cnblogs.com/s/blogpost。
2 : 查看重定位之前的页面信息 - body部分,包含所需cookie信息。
# coding:utf-8
import requests
import re
from urllib.parse import parse_qsl
# 请求首页
url = "http://zzk-s.cnblogs.com/s/blogpost"
r1 = requests.get(url, allow_redirects = False)
print(r1.status_code)
print(r1.text)
# 正则提取
cookieList = re.findall("blogpost?(.+?)"", r1.text)
print(cookieList[0])
cook = dict(parse_qsl(cookieList[0])) # 转为字典
print(cook)
# 请求搜索
param = {
"Keywords" : "001 python接口 get请求"
}
r2 = requests.get(url, params = param, cookies = cook)
print(r2.text)
1 : 使用python获取cookie,再发送搜索请求。

1 : 查看请求结果,服务端返回数据正确。
五: 禅道登录 - cookie
# coding:utf-8
import requests
import re
# 禅道登录
url = "http://127.0.0.1/zentao/user-login.htm"
body = {
"account": "admin",
"password": "123456",
"keepLogin[]": "on",
"referer": "/zentao/my.html"
}
requests.get(url)
requests.post
r = requests.post(url, data = body)
print(r.status_code)
print(r.content.decode("utf-8")) # 中文解码
# 获取cookies
cookiesJar = r.cookies # Jar的格式
print(cookiesJar)
cookiesDict = dict(cookiesJar) # 字典格式
print(cookiesDict)
# 访问请求 - 登录之后
url2 = "http://127.0.0.1/zentao/my/"
r2 = requests.get(url2, cookies = cookiesJar)
print(r2.content.decode("utf-8"))
1 :使用python获取cookie,再请求我的地盘url。
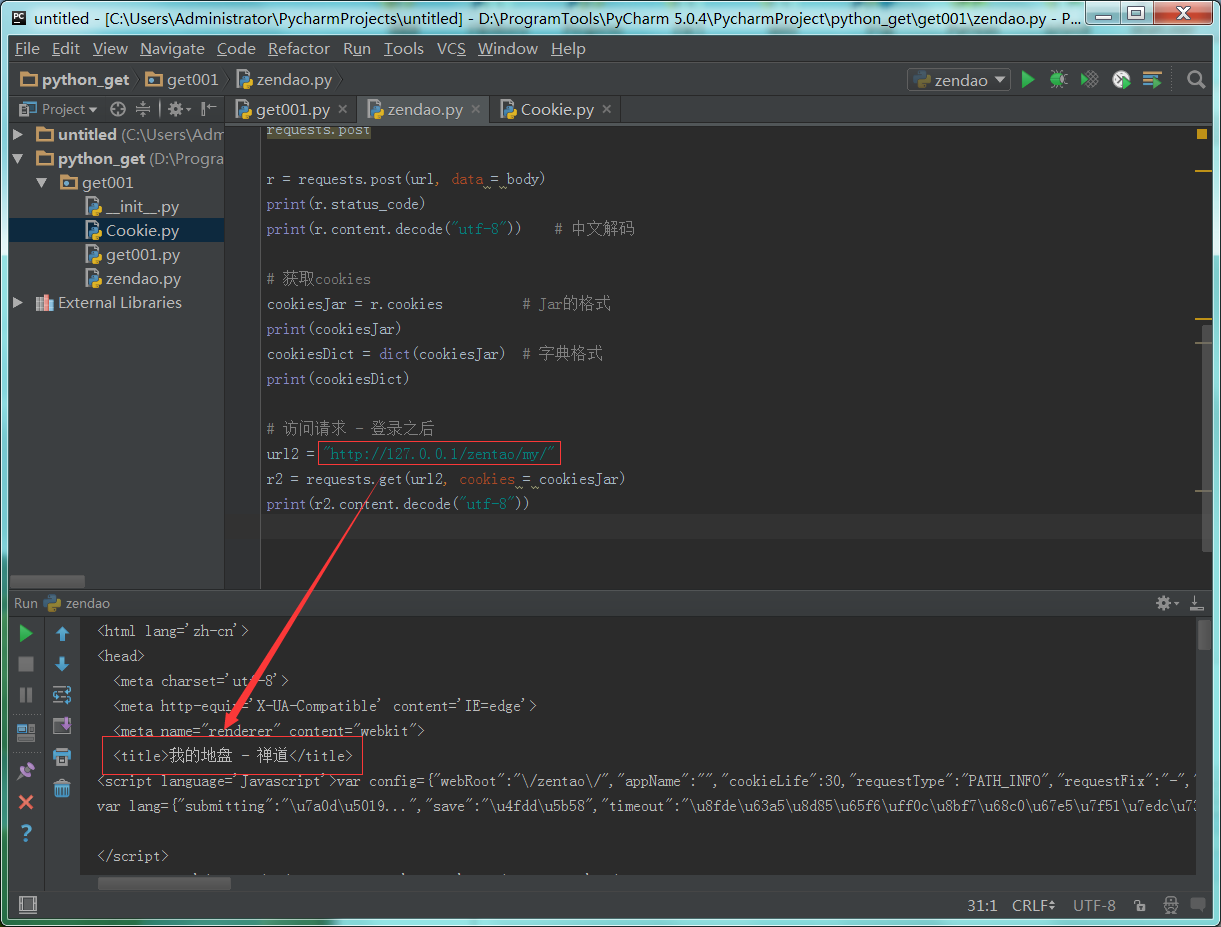
1 : 查看请求结果,客户端访问成功。