Day 16
面向对象初识
类与对象
类:具有相同属性和技能的一类事物 eg:猫是一类
对象: 具体的类的表现,具体的实实在在的一个实例 eg:我家养的杨稀饭
一个类由两部分组成:静态属性(静态变量/静态字段)与动态属性(方法,函数,动态变量)
type是所有类的元类,object是所有类的父类,类是由元类所创建,type(cls) = type
也可以指定类的元类 class A(metaclass=ABCMeta) ,那这个A的元类就是ABCMeta,默认metaclass=type。
class Person:
'''人类画像''' #此处为此类的一个说明,为__doc__变量的值
#类体:两部分:变量部分,方法(函数)部分
mind = '有思想' # 静态属性,静态变量,静态字段
animal = '高级动物'
faith = '有信仰'
def __init__(self,name,age): # __init__ 初始化函数,实力化一个对象时,会自动执行此函数,给对象封装属性
self.name = name #self为实例化的对象本身(对象空间)
self.age = age
def work(self): # 动态属性,方法,函数,动态变量
print('%s会工作...' % self.name)
def shop(self):
print('%s会购物....' %self.name)
p1 = Person("大白",18)
print(p1.__dict__) #用__dict__可查 看类/对象 名称空间的所有属性
print(Person.__dict__)
p1.work()
Day 17
名称空间
创建一个类 或实例化一个对象时,都会创建类的名称空间与对象的名称空间用来存储相应的属性,名称空间之间相互独立。
问:
类能否调用对象的属性? 不能
对象能否调用对应类的属性? 能,对象可以查询其关联类及父类的属性,但不能更改。例如:
class Animal:
animal = '动物'
class Person(Animal):
soul = '有灵魂'
language = '语言'
def __init__(self, country, name, sex, age, hight):
self.country = country
self.name = name
self.sex = sex
self.age = age
self.hight = hight
p1 = Person('菲律宾','alex','未知',42,175) #实例化一个对象
print(Animal.__dict__) #查看Animal类空间的所有属性
print(Person.__dict__) #查看Person类空间的所有属性
print(p1.__dict__) #查看Animal对象空间的所有属性
print(p1.soul) #对象调用对应类的属性
print(p1.animal) #对象调用父类的属性
查询顺序:
对象.属性 : 先从对象空间找,如果找不到,再从类空间找,再找不到,再从父类找....
类名.属性 : 先从本类空间找,如果找不到,再从父类找....
组合
组合: 给一个类的对象封装一个属性,这个属性是另一个类的对象.
以下例子计算圆环的面积与周长,体现组合的思想
from math import pi
#定义一个类计算圆的面积与周长
class Circle:
def __init__(self,r):
self.r = r
def area(self):
return round(self.r ** 2 * pi,2)
def perimeter(self):
return round(self.r * 2 * pi,2)
#通过内外圆的面积与周长得到圆环的面积与周长
class Ring:
def __init__(self,r1,r2):
self.r1 = Circle(r1) #组合:给类Ring的对象封装r1的属性,这个属性时类Cricle的对象
self.r2 = Circle(r2)
def area(self):
return self.r1.area() - self.r2.area()
def perimeter(self):
return self.r1.perimeter() + self.r2.perimeter()
r = Ring(6,3)
print(r.area())
print(r.perimeter())
升级题:
两个游戏人物相互平A/武器攻击:
小乔 血量hp 400 平A攻击力ad 20 可装配武器 嗜血宝扇(攻击力 60)
周瑜 血量hp 300 平A攻击力ad 30 可装配武器 红莲业火(攻击力 100)
class GameRole:
def __init__(self, name, ad, hp):
self.name = name
self.ad = ad
self.hp = hp
def attack(self,p):
p.hp = p.hp - self.ad
print('%s 攻击 %s,%s 掉了%s血,还剩%s血' %(self.name,p.name,p.name,self.ad,p.hp))
def armament_weapon(self,wea):
self.wea = wea
class Weapon:
def __init__(self,name,ad):
self.name = name
self.ad = ad
def fight(self,p1,p2):
p2.hp = p2.hp - self.ad
print('%s 用%s打了%s,%s 掉了%s血,还剩%s血'
% (p1.name,self.name,p2.name,p2.name,self.ad,p2.hp))
p1 = GameRole('小乔',20,400)
p2 = GameRole('周瑜',30,300)
fan = Weapon('嗜血宝扇',60)
fire = Weapon('红莲业火',100)
p1.armament_weapon(fan) #给小乔 装备了嗜血宝扇这个对象 组合,将武器作为对象封装给游戏人物对象
p2.armament_weapon(fire) #给周瑜 装备了红莲火焰这个对象
#相互打架赤身肉搏升级到武器攻击
p2.attack(p1)
p1.attack(p2)
p1.wea.fight(p1,p2)
p2.wea.fight(p2,p1)
p1.wea.fight(p1,p2)
Day 18
面向对象的三大特征:继承 多态 封装
继承
子类以及子类实例化的对象 可以访问父类的任何方法或变量.
子类 又名派生类
父类 又名基类、超类
以下为动物,人,狗,猫的代码,可通过继承简化:
#版本 1
class Animal:
def __init__(self,name,sex,age):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print('%s需要进食....'%self.name)
class Person:
def __init__(self,name,sex,age):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print('%s需要进食....'%self.name)
class Cat:
def __init__(self,name,sex,age):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print('%s需要进食....'%self.name)
class Dog:
def __init__(self,name,sex,age):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print('%s需要进食....'%self.name)
p1 = Person('王国强','male',90)
p1.eat()
#版本 2
class Animal:
def __init__(self,name,sex,age):
self.name = name
self.sex = sex
self.age = age
def eat(self):
print('%s需要进食....'%self.name)
class Person(Animal): #继承,Person子类继承父类Animal的所有属性
def work(self):
print('%s需要工作....'%self.name)
class Cat(Animal):
pass
class Dog(Animal):
pass
p1 = Person('王国强','male',90)
p1.eat()
p1.work()
单继承:
如果子类的对象调用某个方法:
1)只执行父类的方法:子类中不要定义与父类同名的方法
2) 只执行子类的方法:在子类创建这个方法.
3)既要执行子类的方法,又要执行父类的方法?
两种方法:
- 父类.方法名(self,参数1,参数2...)
- 用super(子类名,self).方法名(参数1,参数2) ,也可简写为super().方法名(参数1,参数2)
# super的应用
class A:
def test(self):
print("in A")
class B(A):
def test(self):
print("in B")
super().test() #super(B,self).test()
b=B().test()
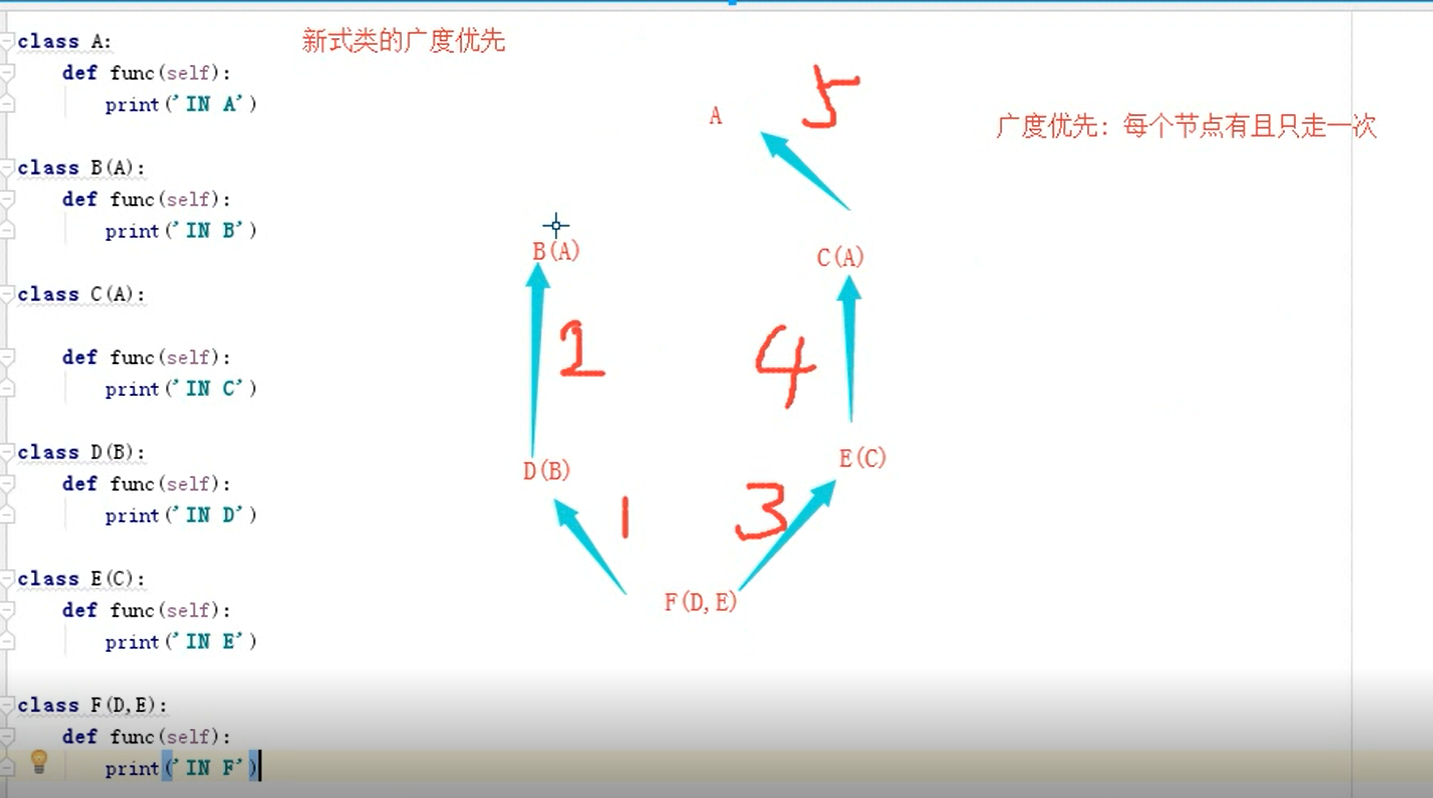
多继承(钻石继承)
新式类与经典类
类分为两种:
- 新式类: 继承object的类都是新式类, python3x 所有的类都为新式类,因为python3 的类默认继承object。
- 经典类: 不继承object类都是经典类, python2x:(既有新式类,又有经典类) 所有的类默认都不继承object类,所有的类默认都是经典类.你可以让其继承object。
新式类 --> 广度优先;经典类 --> 深度优先
多继承的新式类 广度优先 : 一条路走到其他路中也有的某个类的子类,停止,再走其他路,如果这条路没有和其他路的相同类,则这条路走到头。因为广度优先每个节点只走一次。
注:此种算法只适用于新式类多继承中继承两个类的情况 F(D,C),大于两个类继承顺序可参考C3算法.但一般多继承也很少有使用继承数大于两个类的情况。
# class A:
# def func(self):
# print('IN A')
#
# class B(A):
# pass
# # def func(self):
# # print('IN B')
#
# class C(A):
# pass
# # def func(self):
# # print('IN C')
#
# class D(B):
# pass
# # def func(self):
# # print('IN D')
#
# class E(C):
# pass
# # def func(self):
# # print('IN E')
#
# class F(D,E):
# pass
# # def func(self):
# # print('IN F')
#
# f1 = F()
# f1.func()
# class A:
# def func(self):
# print('IN A')
#
# class B(A):
# pass
# # def func(self):
# # print('IN B')
#
# class C(A):
# pass
# # def func(self):
# # print('IN C')
#
# class D(B):
# pass
# # def func(self):
# # print('IN D')
#
# class E(C):
# def func(self):
# print('IN E')
#
# class F(D,E):
# pass
# # def func(self):
# # print('IN F')
#
# f1 = F()
# f1.func()
#
# print(F.mro()) # 查询类的继承顺序 mro(),函数只存在于新式类中
以上代码的查找顺序为:
isinstance(a,A) 判断某个对象a是否为某个类型A,包括父类
type(a) is A 判断某个对象a是否为某个类型A,不包括父类
思考题:
以下d.func()的会输出什么?
#多继承的继承顺序严格按照 mro算法顺序,例如:
#单继承中,对于class B(A)的super().func()查找的父类为 class A;
#下例的多继承中,对于class B(A)的super().func()查找的父类为 class C;
class A:
def func(self):
print("in A")
class B(A):
def func(self):
super().func()
print("in B")
class C(A):
def func(self):
super().func()
print("in C")
class D(B,C):
def func(self):
super().func()
print("in D")
d = D()
d.func()
print(D.mro()) #多继承的顺序
print(isinstance(d,D))
print(isinstance(d,A))
print(type(d) is D)
print(type(d) is C)
#输出结果:
in A
in C
in B
in D
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class
'object'>]
大于2个类的多继承-C3算法
注:此知识点很少用
对于大于2个类的多继承 eg:F(C,D,E)使用C3算法
有如下例子:
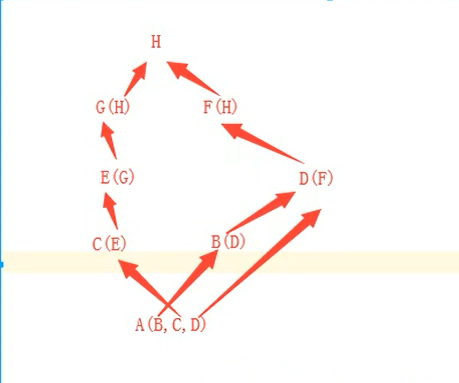
算法为:
#首先找到A继承类的深度继承顺序,得到3个列表:
LB = [B,D,F,H]
LC = [C,E,G,H]
LD = [D,F,H]
#A自己的广度继承关系得到一个列表:
LA = [B,C,D]
#以上4个列表中,每个列表的第一个类为头部,其他为尾部,拿到第一个列表的头部类B,找其他三个列表的尾部是否包含相同的类,如果没有,则取出来放到一个列表lst中,并删除4个列表中头部的B类,如果有,找下一个列表的头部
#只要提取出来一个,我们就从第一个列表的头部接着重复上面的操作
lst = [B,C,D,F,E,G,H]
[B,D,F,H] [C,E,G,H] [D,F,H] [B,C,D]
第一步:找B,尾部没找到,提出来
[D,F,H] [C,E,G,H] [D,F,H] [C,D]
第二步:找D,尾部找到D,接着找第二个列表头部
[D,F,H] [C,E,G,H] [D,F,H] [C,D]
第三步:找C,尾部没找到
[D,F,H] [E,G,H] [D,F,H] [D]
第四步:找D,尾部没找到
[F,H] [E,G,H] [F,H] []
第五步:找F,尾部没找到
[H] [E,G,H] [H] []
第六步:找H,尾部找到,接着找第二个列表头部
[H] [E,G,H] [H] []
第七步:找E,尾部没找到
[H] [G,H] [H] []
第八步:找H,尾部找到,接着找第二个列表头部
[H] [G,H] [H] []
第九步:找G,尾部没找到
[H] [H] [H] []
第九步:找H
[] [] [] []
加上首先找到A类本身和最后找的Object,查找顺序为 [A,B,C,D,F,E,G,H,O]
Day 19
抽象类与接口类
用来制定一种规范
在python中:
抽象类与接口类不做区分,因为python默认支持多继承;
在java中:
抽象类与接口类有明显区分,java默认只支持单继承,为了实现多继承功能,java有一种叫接口的数据类型,多继承的表现形式为 class D(interface.A,interface.B),这种用于被多继承的interface中的方法就是接口类。
抽象类:抽象类中的方法是可以实现的,只能单继承。
接口类:接口interface支持多继承规范,接口中的所有方法 只能写pass ,无法被实现
此处两个重点:
归一化设计;
抽象类接口类制定规范的语法
现有需求:
编写用户用支付宝,京东,微信支付
第一版
# class Alipay:
# def __init__(self,money):
# self.money = money
#
# def pay(self):
# print('使用支付宝支付了%s' %self.money)
#
#
# class Jdpay:
# def __init__(self, money):
# self.money = money
#
# def pay(self):
# print('使用京东支付了%s' % self.money)
#
# # a1 = Alipay(200)
# # a1.pay()
# #
# # j1 = Jdpay(100)
# # j1.pay()
由于第一版中支付实例化时分别调用了不同类的方法,考虑到编程的归一化设计,需要优化
归一化设计
第二版 改进,让你支付的方式一样
# class Alipay:
# def __init__(self,money):
# self.money = money
#
# def pay(self):
# print('使用支付宝支付了%s' %self.money)
#
#
# class Jdpay:
# def __init__(self, money):
# self.money = money
#
# def pay(self):
# print('使用京东支付了%s' % self.money)
#
# def pay(obj): #添加pay函数统一支付入口
# obj.pay()
#
# a1 = Alipay(200)
# j1 = Jdpay(100)
# pay(a1) # 归一化设计
# pay(j1)
第三版,野生程序员来了.......要增加一个微信支付的功能.
此版中微信支付类的支付方法不统一
# class Alipay:
# def __init__(self,money):
# self.money = money
#
# def pay(self):
# print('使用支付宝支付了%s' %self.money)
#
#
# class Jdpay:
# def __init__(self, money):
# self.money = money
#
# def pay(self):
# print('使用京东支付了%s' % self.money)
#
# class Wechatpay:
#
# def __init__(self,money):
# self.money = money
#
# def weixinpay(self): #未统一支付方法名,导致无法调用统一的支付入口pay函数
# print('使用微信支付了%s' % self.money)
#
#
# def pay(obj):
# obj.pay()
#
# a1 = Alipay(200)
# j1 = Jdpay(100)
# pay(a1) # 归一化设计
# pay(j1)
#
# w1 = Wechatpay(300)
# w1.weixinpay()
抽象类接口类制定规范的语法
第四版,发回去重新改,制定规则,抽象类,接口类
#强制制定一个规范,凡是继承Payment的类中必须有pay方法,如果没有,实例化对象就会报错,需要强制子类存在某种方法就在该方法上一行加@abstractmethod
# from abc import ABCMeta,abstractmethod
#
# class Payment(metaclass=ABCMeta): # 抽象类(接口类):
# @abstractmethod
# def pay(self): pass # 制定了一个规范
# #@abstractmethod
# #def func(self):pass
#
#
# class Alipay(Payment):
# def __init__(self,money):
# self.money = money
#
# def pay(self):
# print('使用支付宝支付了%s' %self.money)
#
#
# class Jdpay(Payment):
# def __init__(self, money):
# self.money = money
#
# def pay(self):
# print('使用京东支付了%s' % self.money)
#
# class Wechatpay(Payment):
#
# def __init__(self,money):
# self.money = money
#
# def pay(self):
# print('使用微信支付了%s' % self.money)
#
#
# def pay(obj):
# obj.pay()
# w1 = Wechatpay(200)
# a1 = Alipay(200)
# j1 = Jdpay(100)
# pay(a1) # 归一化设计
# pay(j1)
#
# w1 = Wechatpay(300)
# w1.weixinpay()
多态
一种类型的多种形态:eg:多个子类去继承同一个父类,那么这些子类都是父类的不同形态
#多态的应用
class Animal: pass
class Tiger(Animal): pass #Tiger是Animal的一种形态
class Flog(Animal): pass #Flog是Animal的一种形态
例如要制定一个eat函数,传入一个Tiger或者Flog的类:
python中:传入的参数类型不需要定义
def Eat(obj):
obj.eat()
Java中:必须要定义对象类型,由于老虎和青蛙类型不确定,故使用父类Animal类型,老虎,青蛙就是Animal类型的不同形态
def Eat(Animal obj):
obj.eat()
由于python是弱类型语言,定义参数时不需要指定数据类型,python没有多态的示例,处处是多态
python的鸭子类型
即一种使用风格,中心思想是规范全凭自觉。拥有相同属性与方法的类或函数互称为鸭子类型,即定义一些函数(类),有专属鸭子的走或叫的方法,将鸭子对象带进去能正常运行,即这些函数或类都为鸭子类型。eg:Str、List、Tuple类都有index方法,对于对应的对象都能正常使用index,那么这些类都互为鸭子类型。
封装
广义的封装:定义一些属性来描述一类事物,实例化一个对象,为对象空间封装一些属性;给类封装静态字段......
狭义的封装:私有制。包括一些私有成员:私有静态字段、私有方法、私有属性
私有成员
对于所有私有成员都只能在该类的内部访问,类的外部与派生类均不可访问
私有成员的写法在普通的静态字段/方法/属性前加__
class A:
__money=1000
class B(A):
__age=6
name="小王"
def __init__(self,hair,long):
self.__hair=hair
self.long=long
def __longhair(self):
print("我的头发长%scm" % self.long)
def haircolor(self):
print("%s的头发是%s" % (self.name,self.__hair))
self.__longhair()
def func(self):
print(self.__age)
print(B.__age)
def func1(self):
print(self.__money)
b1=B("黄头发",60)
# b1.__longhair() #私有方法__longhair不能在外部调用
# b1.haircolor() #私有方法__longhair可在内部方法haircolor中调用
#私有属性__hair可在类的内部调用
# print(b1.__hair) #私有属性__hair不能在外部调用
# b1.func() #class B中定义的私有静态变量__age可在该类中使用
# print(B.__age) #私有静态变量不能在外部引用
# print(b1.__age)
# b1.func1() #父类class A定义的私有静态变量 __money不能在子类class B中使用
#打印class B及其实例化对象b1的所有属性及其对应值可知私有成员在内存空间的名字都会加上 _类名,
# eg: 私有属性__hair,存储的变量名为 _B__hair (在外部调用此名可获取到私有属性的值,但一般不这么做))
# print(b1.__dict__)
# print(B.__dict__)
思考题:
以下输出什么:
class Parent:
def __func(self):
print("in Parent")
def __init__(self):
self.__func()
class Son(Parent):
def func(self):
print("in Son")
son1=Son()
分析:
1.对象son1获取__init__方法:对象空间-->Son类空间 -->父类Parent空间(找到了)
2.对象读取self.__func()时,实际读取的是 self._Parent__func()
3.查找_Parent__func()方法并执行:对象空间-->Son类空间 -->父类Parent空间(找到了)
所以输出是 什么呢?
class Parent:
def func(self):
print("in Parent")
def __init__(self):
self.func()
class Son(Parent):
def func(self):
print("in Son")
son1=Son()
分析:
1.对象son1获取__init__方法:对象空间-->Son类空间 -->父类Parent空间(找到了)
2.对象读取self.__func()
3.查找__func()方法并执行:对象空间-->Son类空间(找到了)
Day 20
装饰器
python装饰器本质上就是一个函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外的功能,装饰器的返回值也是一个函数对象(函数的指针)。 装饰器函数的外部函数传入我要装饰的函数名字,返回经过修饰后函数的名字;内层函数(闭包)负责修饰被修饰函数。从上面这段描述中我们需要记住装饰器的几点属性,以便后面能更好的理解:
实质: 是一个函数
参数:是你要装饰的函数名(并非函数调用)
返回:是装饰完的函数名(也非函数调用)
作用:为已经存在的对象添加额外的功能
特点:不需要对对象做任何的代码上的变动
python装饰器有很多经典的应用场景,比如:插入日志、性能测试、事务处理、权限校验等。装饰器是解决这类问题的绝佳设计。并且从引入中的列子中我们也可以归纳出:装饰器最大的作用就是对于我们已经写好的程序,我们可以抽离出一些雷同的代码组建多个特定功能的装饰器,这样我们就可以针对不同的需求去使用特定的装饰器,这时因为源码去除了大量泛化的内容而使得源码具有更加清晰的逻辑。
装饰器的调用:
在需要被装饰的函数上方添加 @装饰器名
自定义装饰器
def add_school(func):
def school(*args,**kwargs):
ret=func(*args,**kwargs)
return "建党小学",ret
return school #返回school函数本身(非调用)
@add_school #相当于school(func)("张建国",6),即school("张建国",6)
def student_list(name,age):
return(name,age)
a=student_list("张建国",6)
print(a)
输出:
('建党小学', ('张建国', 6))
认识三个装饰器
property
作用:将方法伪装成属性,使其看起来更合理。 eg: 周长,面积,BMI 这些名词更适宜为属性,而不是方法
@property 一个内置的装饰器函数,将某个方法装饰为属性,可通过 Person(xx).age 调用
@方法名.setter 装饰器函数,让@property装饰的为属性的某个方法,可以像属性一样重新赋值
@方法名.deleter 删除装饰为属性的某个方法,并不能真正删除,还需在方法中定义 del self.方法名
此处__age为私有属性,外部需要调用,就设置了一个age方法,但age更适合为属性而不是方法,故使用属性装饰器
class Person:
def __init__(self,name,age):
self.name = name
if type(age) is int:
self.__age = age
else:
print("请输入整数型的age参数")
@property
def age(self):
print(self.__age)
@age.setter
def age(self,a1):
if type(a1) is int:
self.__age = a1
else:
print("请输入整数型的age参数")
@age.deleter
def age(self):
del self.__age
p1=Person("ww","20")
p1=Person("ww",20)
p1.age #以属性的方式调用age "属性"
p1.age="30"
p1.age=30 #为age属性重新赋值
print(p1.__dict__)
del p1.age #删除p1对象空间的age属性
print(p1.__dict__)
当类中某个属性A会随着其他属性的变更而变化时,这个属性A适合定义为方法,再加上property装饰器
from math import pi
#定义一个类计算圆的面积与周长
from math import pi
class Circle:
def __init__(self,r):
self.r = r
# self.area = r ** 2 * pi #问: 为什么不直接定义area的属性,而是将其定义为方法再伪装成属性?
@property
def area(self):
return round(self.r ** 2 * pi,2)
c1 = Circle(5)
print(c1.area)
c1.r = 10
print(c1.area)
# 分析:
from math import pi
class Circle:
def __init__(self,r):
self.r = r
self.area = r ** 2 * pi
c1 = Circle(5)
print(c1.area)
c1.r = 10
print(c1.area) #我们发现当将半径参数改为10之后,面积认为半径为5的面积,而将其定义为方法可以很好的避免这个问题
类方法
类方法:通过类名调用的方法,约定俗成第一个参数为cls,python自动将类名(类空间)传给cls。
@classmethod 将某个方法设置为类方法
eg:
class A:
def func1(self): #普通方法
print(self)
@classmethod #类方法
def func2(cls):
print(cls)
a1=A()
a1.func1()
a1.func2() #对象调用类函数,传入的值cls为对应的类
A.func2() #类调用类函数,传入的值为其本身类空间
类方法的使用场景:
- 类中有些方法不需要对象参与:
- 对类中的静态变量进行改变
- 继承中,父类获取子类的类空间
eg:
类中有些方法不需要对象参与:
func2中只适用了类空间的静态变量,将其设置为类方法,可直接通过类调用,无需实例化一个对象
class A:
name = "张三"
age = "77"
@classmethod
def func2(cls):
print("%s %s岁了" % (cls.name,cls.age))
A.func2()
思考题:
以下输出什么
继承中,父类获取子类的类空间:
class A:
age = 12
@classmethod
def func2(cls):
#父类A获取到子类B的类空间,还可进行增删改查的操作
print(cls.age)
class B(A):
age = 60
B.func2()
分析:
1. class B读取其父类class A的类方法func2
2. cls究竟是class A 还是class B?
3. cls为调用类本身对应的类空间或调用对象对应的类的类空间,此处调用该方法的类为class B
静态方法
在类中不需要传入类或对象空间的属性,可在调用该方法时直接传入参数
@staticmethod 将某个方法设置为静态方法
class C:
@staticmethod
def login(name,password):
if name == "张三" and password == "4567" :
print("login success")
else:
print("invalid username or password")
C.login("张三","4567")
我们发现静态方法其实完全可以写成单个函数,例如以下代码。那么封装为类中静态方法的意义是什么?
def login(name,password):
if name == "张三" and password == "4567" :
print("login success")
else:
print("invalid username or password")
login("张三","4567")
将静态方法封装为代码块放到其对应的逻辑类中,更加清晰;
还可通过继承,增加代码的复用性。
Day 21
反射
反射:用字符串类型的变量名来访问该变量的值
反射的方法: getattr hasattr setattr delattr
当某个变量名/方法名/函数名为字符串(例如从外部input输入),该怎么去调用该变量对应的值?
四个使用场景
Example 1: 反射类/对象中的属性/方法
class A:
school = "希望小学"
def __init__(self,name):
self.name = name
def get_name(self):
print("My name is %s" % self.name)
print(A.school)
print(getattr(A,"school")) #反射类中的静态变量
s1 = A("Yorgur")
print(s1.name)
print(getattr(s1,"name")) #反射对象中的属性
s1.get_name()
getattr(s1,"get_name")() #反射对象中的方法
Example 2: 反射模块中的方法
import os
os.rename("test.py","test2.py")
getattr(os,"rename")("test2.py","test.py")
Example 3: 反射当前文件中的函数
#sys.modules变量包含一个由当前载入(完整且成功导入)到解释器的模块组成的字典, 模块名作为键, 它们的位置作为值
#这里使用 sys.modules[__name__]更为准确,因为当文件作为模块为导入时sys.modules["__main__"]并不是模块本身的名称空间。
import sys
def room():
print("我的房间是个茅草屋")
room()
#print(sys.modules["__main__"])
#getattr(sys.modules["__main__"],"room")()
print(sys.modules[__name__])
getattr(sys.modules[__name__],"room")()
#hasattar getattr的结合使用
#以下代码中从外部输入类的方法,若输入的内容在类中不存在,则会报错,需要hasattar判断类中是否有该种方法
class Student:
def __init__(self,name):
self.name=name
@staticmethod
def check_course():
print("可选课程为:数学 物理 化学")
def choose_course(self):
self.course=input("<<<")
print("选择课程为:%s" % self.course)
def choosed_course(self):
print("所选课程为: %s" % self.course)
s1 = Student("小花")
get_way = input("<<<")
#getattr(s1,get_way)() #反射类中的方并调用
if hasattr(Student,get_way):
getattr(s1,get_way)()
else:
print("bad input")
setattr与delattr
class A:
name = "王大"
setattr(A,"name","王二") #重置A的静态变量name对应的值
print(getattr(A,"name"))
delattr(A,"name") #删除A的静态变量name
print(getattr(A,"name"))
总结:
# 反射的四种用法 hasattr,getattr
1. 类名.名字 ==> getattr(类名,'名字')
2. 对象名.名字 ==> getattr(对象,'名字')
3. 模块名.名字 ==>
import 模块
getattr(模块,'名字')
4. 自己文件.名字 ==>
import sys
getattr(sys.modules['__main__'],'名字')
内置方法(双下方法)
格式:__方法名__
别名:类中的特殊方法、内置方法、双下方法、魔术方法
__call__ 相当于 对象(),在用类写装饰器的地方,能用到
__len__ 相当于 len(obj),函数返回的值必须是int()类型
__new__ 特别重要 开辟内存空间 类的构造方法
单例类(只能有一个实例空间内的类)
__str__ 相当于 str(obj),print(),str(),"%s" % 调用__str__方法,要求返回值必须是str类型
__repr__ 将字符串转换为供解释器读取的形式,相当于__str__的备胎,当__str__存在时,print(),str(),"%s" % 调用__str__,不存在时,print(),str(),"%s" % 调用__repr__
repr(),"%r" % 默认调用__repr__方法
__call__
#__call__ 相当于 对象(),在用类写装饰器的地方,能用到
class A:
def __call__(self,*args,**kwargs):
print("in call")
A()()
__len__
#__len__ 相当于 len(obj),函数返回的值必须是int()类型
class A:
def __len__(self):
print("执行__len__")
return 666
a=A("tom")
print(a.__len__())
print(len(a))
__new__ 构造方法
#__new__ 构造方法,用于实例化对象时创建对象空间,在__init__之前执行
class A:
def __new__(cls, *args, **kwargs):
obj = object.__new__(cls)
print(obj)
return obj #self会接受return的结果
def __init__(self,name):
self.name = name
a=A("tom")
print(a)
###单例类
单例类举例:重要
class A:
__ISINSTANCE = None
def __new__(cls, *args, **kwargs):
if not cls.__ISINSTANCE:
cls.__ISINSTANCE = object.__new__(cls)
return cls.__ISINSTANCE #self会接受return的结果
def __init__(self,name):
self.name = name
a=A("Tom")
print(a.name)
print(a)
b=A("Judy")
print(b)
print(a.name)
print(b.name)
__str__ 与 __repr__
#__str__ 相当于 str(obj),print(),str(),"%s" % 调用__str__方法,要求返回值必须是str类型
#类中添加此函数后,print(对象名)不再是对象空间,而是此函数的return值
class Student:
def __init__(self,name):
self.name = name
def __str__(self):
return self.name
a = Student("张华")
print(a)
print(str(a))
print("student %s" % a)
总结
# print一个对象相当于调用一个对象的__str__方法
# str(obj),相当于执行obj.__str__方法
# '%s'%obj,相当于执行obj.__str__方法
__repr__
# 在子类中使用__str__,先找子类的__str__,没有的话要向上找,只要父类不是object,就执行父类的__str__
# 但是如果出了object之外的父类都没有__str__方法,就执行子类的__repr__方法,如果子类也没有,
# 还要向上继续找父类中的__repr__方法.
# 一直找不到 再执行object类中的__str__方法
class A:
# def __str__(self):
# return "str A"
def __repr__(self):
return "repr A"
class B(A):
# def __str__(self):
# return "str B"
def __repr__(self):
return "repr B"
b = B()
print(b.__repr__())
print(repr(b))
print(b)
以下举一个选课系统的例子,来看一下反射的应用(其中只是一个大概逻辑,并不完整)
准备一个文件p_list.txt,存放人员信息
Yorgur 123 Manager
Tom 666 Student
import sys
class Manager:
func_list=[("添加课程","add_course"),("添加学生","add_student")]
def __init__(self,name):
self.name = name
self.course_list = []
def add_course(self):
get_course = input("添加的课程用空格分割:").strip().split()
for i in range(len(get_course)):
self.course_list.append(get_course[i])
self.course_list=list(set(self.course_list))
print("添加课程为:%s" %self.course_list)
def add_student(self):
stu = input("学生名字")
print("添加学生为:%s" %stu)
class Student():
func_list=[("查看课程","check_course"),("选择课程","choose_course"),("查看已选课程","choosed_course")]
def __init__(self,name):
self.name = name
self.course = []
self.have_course = ["数学","物理","化学"]
@staticmethod
def check_course():
print("可选课程为:'物理', '数学', '语文', '化学'")
def choose_course(self):
self.course.append(input("<<<"))
print("选择课程为:%s" % self.course)
def choosed_course(self):
if self.course:
print("所选课程为: %s" % self.course)
else:
print("还未选择课程")
def login():
username=input("username:")
passwd=input("password:")
with open(file="p_list.txt",mode="r") as f:
for line in f:
user,pwd,ident=line.strip().split(" ")
if username == user and passwd == pwd:
print("登陆成功")
return username,ident
import sys
def main():
username,ident = login()
cls = getattr(sys.modules["__main__"],ident)(username)
for num,i in enumerate(cls.func_list,1): #知识点,enumerate()
print(num,i[0])
while True:
get_way = input("请输入需要的功能序号(退出请输入exit):")
if get_way == "exit":
print("exit success")
sys.exit()
else:
way = cls.func_list[int(get_way)-1][1]
getattr(cls,way)()
main()
#enumerate(可迭代对象,第一个索引为几)
#将一个可迭代对象组合为一个索引序列,生成一个迭代器,可使用print(list(enumerate(list1,1))查看结果
#例如以上代码Manager中的列表enumerate为 [(1, ('添加课程', 'add_course')), (2, ('添加学生', 'add_student'))]
Day 22 复习总结
Day 23 双下方法 与 模块初识
接下来继续学习一些双下方法
__del__ 析构方法:用于释放对象空间,清除一个对象在内存中使用的时候会调用此方法(手动del() 或 python解释器自动回收)。
应用场景:某对象借用了操作系统的资源,python解释器无权回收,还要通过析构方法归还回去 : 文件资源 网络资源
item系列 使用对象[]调用/修改/删除某属性
__getitem__
__setitem__
__delitem__
__hash__ hash()默认调用此函数,hash算法能够把某个要存在内存的值通过某种计算得到hash值(该hash值对应某个地址),用于优化该值的内存寻址。
在一次执行中(一次运行代码的过程中),同一个值的hash值是相同的,但在多次执行中,同一个值的hash值不一定相等。
在一次执行中,如果出现A B有两个相同的hash值,hash算法会比较被hash的对象是否相等, A==B ?,如果相等就会覆盖,如果不等,就会为B其重新计算一个hash值。
字典、集合都用到hash算法
__eq__ ==默认调用此函数,使用场景:可用于调整对象的比较规则
接下来展示一些代码,加深理解
__del__ 析构方法
# __del__ 清除一个对象在内存中使用的时候会调用此方法。
#pathy解释器会自动回收不用的类空间与对象空间,但是文件描述符和操作系统相关,解释器无权回收,需要手动定义回收操作
class A:
def __init__(self,name,filepath):
self.name = name
self.filepath = filepath
self.f = open(file=filepath,encoding="utf-8",mode="r")
def read(self):
print(self.f.read())
def __del__(self):
print("在这里执行__del__ %s" %self.filepath)
self.f.close() #关闭文件描述符
a = A("alex","course_list.txt")
b = A("zdd","test.txt")
# a.__del__() #可以看到这两行的执行效果一样,程序结束还会调用此函数
# del a
a.read()
#函数结束时,每个对象会分别自动调用__del__方法,释放资源
item系列
#item系列
# 例一:类似于字典的操作
class A:
def __init__(self,name,age):
self.name = name
self.age = age
def __getitem__(self,key):
return (getattr(self,key))
def __setitem__(self,key,value):
# print("in setitem")
setattr(self,key,value)
def __delitem__(self,key):
delattr(self,key)
a1 = A("张三",18)
print(a1["age"])
a1["hobby"] = "play basketball" #新增hobby属性
print(a1["hobby"])
del a1["age"] #删除age属性
print(a1["age"])
# 例二:类似于列表的操作
class B:
def __init__(self,lst):
self.lst = lst
def __getitem__(self,index):
return self.lst[index]
def __setitem__(self,index,value):
self.lst[index] = value
def __delitem__(self,index):
del self.lst[index]
b = B(["a","b","c","d","e"])
print(b.lst)
print(b[3]) #查询某个索引对应的值
b[2] = "z" #重置某个索引对应的值
print(b.lst)
del b[4] #删除某个索引对应的值
print(b.lst)
__hash__
hash算法:
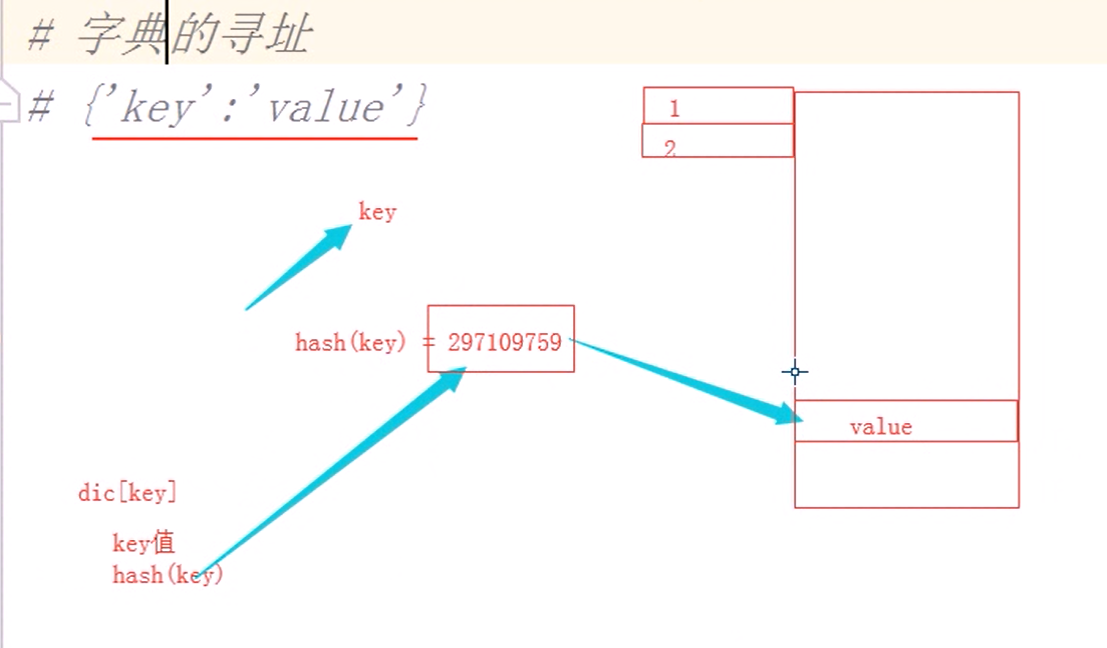
字典的寻址
获取字典某个key对应的值比获取列表某个索引位对应的值快,原因是什么?
因为字典存储时使用hash算法, 将value存储在hash(key)对应的内存地址空间,一次寻址就可以找到对应的内存地址。而列表需要根据索引一个一个去找。
集合去重
集合存储时,将value存在hash(value)对应的内存地址空间,所以有重复值时,hash值一样,存储地址相同,会覆盖,所以集合里面的值都是唯一的。
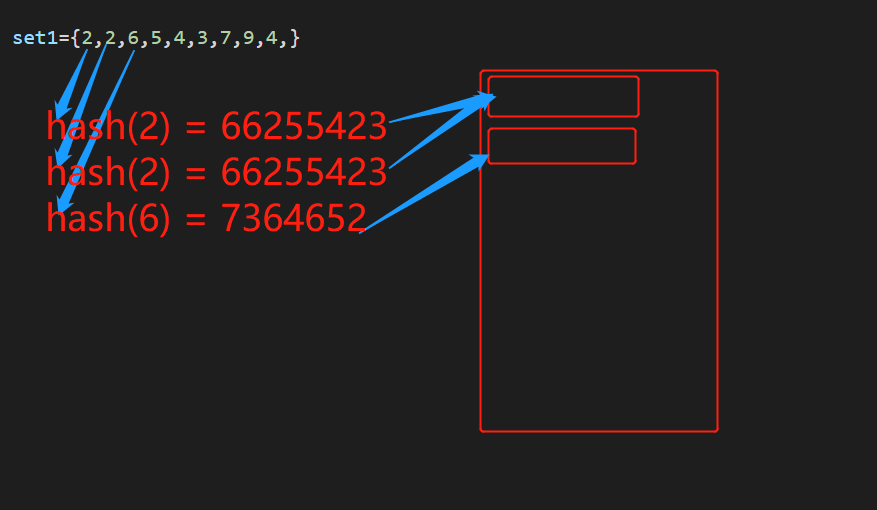
数据类型中有__hash__,那么这个数据类型就是可hash的,但是当元组中有可变类型值时,也是不可hash的,是可变类型不可hash的原因。
- 可hash的数据类型(不可变): 整数,字符串,元组(当元组中的成员都是不可变数据类型)
- 不可hash数据类型(可变):其中可变是指对象中的值改变,但对象的id不变。列表,字典,集合
__eq__
#__eq__ 类A实例化的对象进行 ==比较时,调用此函数
class A:
def __init__(self,name,age):
self.name = name
self.age = age
def __eq__(self,other):
print("in __eq__")
if self.name == other.name and self.age == other.age:
return True
else:
return False
a1 = A("小王",16)
a2 = A("小张",16)
print(a1 == a2) #调用了A中的__eq__
hash与eq的练习题
思考题:
有一个员工管理系统:
员工信息为: name sex age partment
由于之前一些员工转岗时,未直接修改员工部门,而是新增了一份员工信息
请去除重复的员工信息
employee_list.txt内容为:
Tom 男 23 运维
Tom 男 26 开发
Tom 男 29 销售
Tim 男 21 开发
Lury 女 29 运维
Forlsa 女 31 人事
Forlsa 女 35 行政
zhanghua 男 34 法务
#此题考了对集合set存取值的hash原理
#类的内置函数__hash__ 与__eq__
#将每个员工作为Employee类的一个对象放在集合里,集合拿到第一个对象进行hash (故要定义__hash__),得到的hash值对应一个地址空间,当员工信息有重复时,会得到相同的hash值,然后会进行比较 == (故要定义__eq__),如果比较结果相同,就去重。
class Employee:
def __init__(self,name,sex,age,partment):
self.name = name
self.sex = sex
self.age = age
self.partment = partment
def __hash__(self):
return hash("%s%s"%(self.name,self.sex))
def __eq__(self,other):
if self.name == other.name and self.sex == other.sex:
return True
else:
return False
f = open(file = "employee_list.txt",encoding="utf-8",mode="r")
lis1 = []
for i in f:
i = i.strip().split(" ")
lis1.append(Employee(i[0],i[1],i[2],i[3]))
new_list=list(set(lis1))
for i in new_list:
obj = i.__dict__
print("%s %s %s %s" % (obj["name"],obj["sex"],obj["age"],obj["partment"]))
f.close()
模块
模块:模块是一组包含了一类功能的python文件,可以用import 调用。
分类:
- 内置模块
安装python解释器的时候跟着装上的那些模块 - 第三方模块/扩展模块
没在安装python解释器的时候安装的那些功能 - 自定义模块
你写的功能如果是一个通用的功能,那你就把它当做一个模块
模块相关的规范:
- 模块名同变量的命令规则一样,一般首字母小写
- 导入模块:
一行导入多个模块 import math,sys,os (不建议这么用)
一行调用一个模块 - 导入顺序为: 先导入内置模块,再导入第三方模块,最后导入自定义模块
模块的的导入
import 模块名
import 模块名 (as new_name)
导入模块的过程:
给模块新开一个空间,并执行了模块的代码,将变量放到模块的空间中;
在当前模块创建了一个模块名/new_name 的变量,指针指向模块的空间地址。
简单创建一个模块:
新增一个文件 mymodule.py
name = "Honey"
age = 17
def func():
print(name)
func()
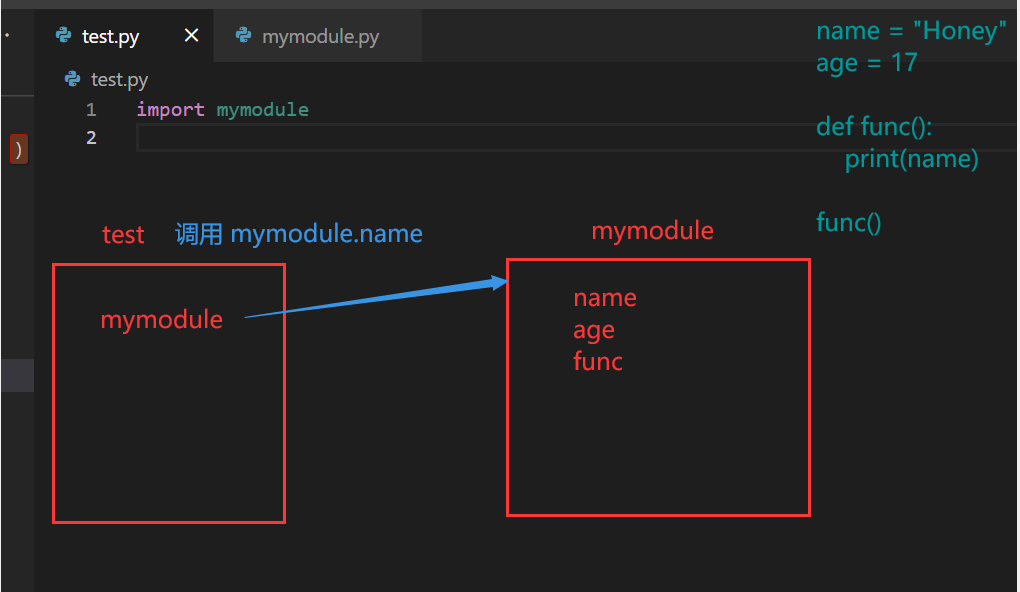
在当前路径下另一个文件中调用这个模块:
import mymodule #模块不会被多次导入,多个import也只会执行一次
#import mymodule as mym #将模块重名了import xxx as xx(也可以不重命名)
print(mymodule.age)
print(mymodule.func())
mymodule.func()
运行后,输出为:
Honey #import这个模块相当于执行了这个模块所在的py文件
17 #可以通过模块名.变量名调用变量
Honey #可以通过模块名.方法名()调用方法
导入模块的过程:
给模块新开一个空间,并执行了模块的代码,将变量放到模块的空间中;
在当前模块创建了一个模块名/new_name 的变量,指针指向模块的空间地址。
Day 24
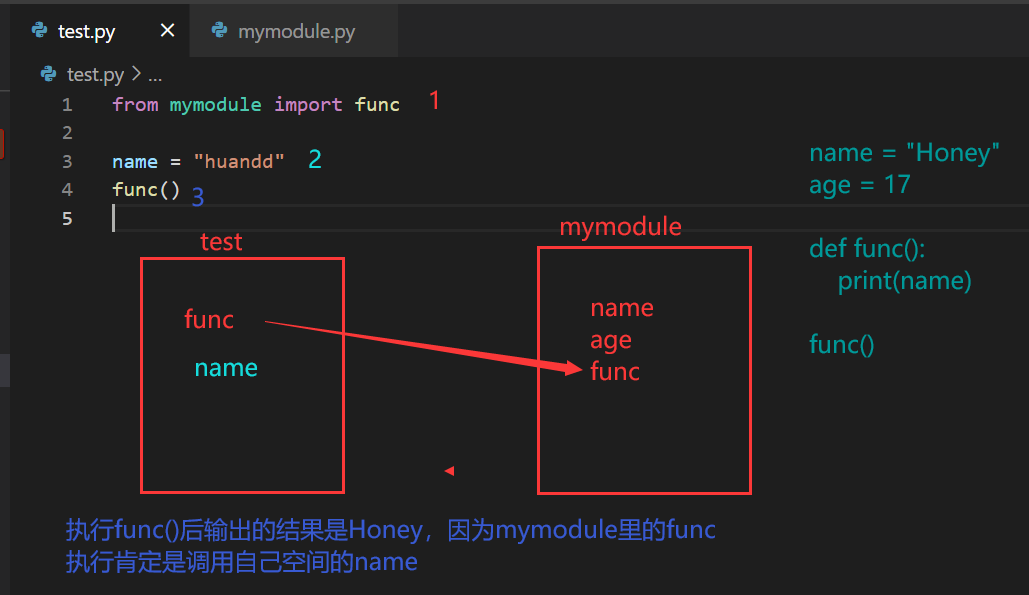
from 模块名 import 名字
from 模块名 import 方法/变量/类名 (as new_name)
此种方法导入的变量才能使用,没导入的不能使用
用法:
from 模块名 import 变量1 #加载单个变量/方法
from 模块名 import 变量1,变量2 #加载多个变量/方法
from 模块名 import *
1)当模块中没有__all__时,导入全部变量/方法
2)当模块有__all__时,导入__all__中的变量/方法
文件1 test.py
from mymodule import *
func()
print(name)
print(age)
文件2 mymodule.py
__all__ = ["name","func"] #__all__变量定义为列表类型,其中变量名英文字符串类型
name = "Honey"
age = 17
def func():
print(name)
func()
脚本方式运行test.py,输出:
Honey #import模块时 func() 打印的
Honey
Honey
NameError: name 'age' is not defined
写的代码有两种运行方式:
- 以模块的方式被加载
- 以脚本的方式运行
__name__
那我们怎么实现import模块时不能输出结果,脚本执行时又能输出呢?
将所有不在函数和类中封装的内容都写在 if __name__ == "__main__": 下面
以下进行详细说明:
#__name__与sys.modules["__main__"]
文件1 test.py
from mymodule import func
import sys
name = "huandd"
func()
print(__name__)
print(sys.modules["__main__"])
文件2 mymodule.py
import sys
name = "Honey"
age = 17
def func():
print(name)
func()
print(__name__)
print(sys.modules["__main__"])
将test.py作为脚本运行,mymodule.py作为模块运行输出:
Honey
mymodule #mymodule的__name__
<module '__main__' from 'd:\Desktop\python_script\test.py'> #mymodule的sys.modules["__main__"]
Honey
__main__ #test.py的__name__
<module '__main__' from 'd:\Desktop\python_script\test.py'> #test.py的sys.modules["__main__"]
如果以执行脚本的方式运行filename.py,__name__就是 __main__;
如果以导入模块的方式运行,__name__就是 filename 或者说模块名;
sys.modules["__main__"] 就是当前载入解析器的模块中正在执行的那个文件的空间地址,和在哪里执行没有关系
所以将以上的代码改成:
文件1 test.py
from mymodule import func
import sys
name = "huandd"
# func()
if __name__ == "__main__":
func()
print(__name__)
print(sys.modules["__main__"])
文件2 mymodule.py
import sys
name = "Honey"
age = 17
def func():
print(name)
if __name__ == "__main__":
func()
print(__name__)
print(sys.modules["__main__"])
将test.py作为脚本运行,mymodule.py作为模块运行时就不会输出模块文件中的内容:
Honey
__main__
<module '__main__' from 'd:\Desktop\python_script\test.py'>
模块的循环引用
当多个模块都相互导入,并形成了闭环时,明明写在这个模块中的方法,就会报错显示找不到。
所以一定要梳理你的模块导入是否形成了闭环。
pyc编译文件与重载模块
python脚本运行时会先将源代码编译为字节码的形式,再逐行执行编译后的字节码,并缓存一份编译好的文件在这个文件所在的目录的__pycache__下,之后再次执行这个文件时,会直接读这个编译好的pyc文件,可以节省导入的时间。
所以在一次执行a.py文件的过程中,改变a.py中的代码,执行结果还是不会变,只有下一次执行时,才是更改后的结果。
那么有没有办法在一次执行过程中更改文件后,还能重新载入呢?
用 importlib,但是非常不推荐这种用法!!!!
文件1 test.py
import mymodule
import time
import importlib
if __name__ == "__main__":
mymodule.func()
time.sleep(10)
importlib.reload(mymodule)
mymodule.func()
文件2 mymodule.py
import sys
name = "Honey"
age = 17
def func():
print(name)
运行文件1 test.py,并在sleep的过程中更改文件2的name="Hony",输出:
Honey
Hony
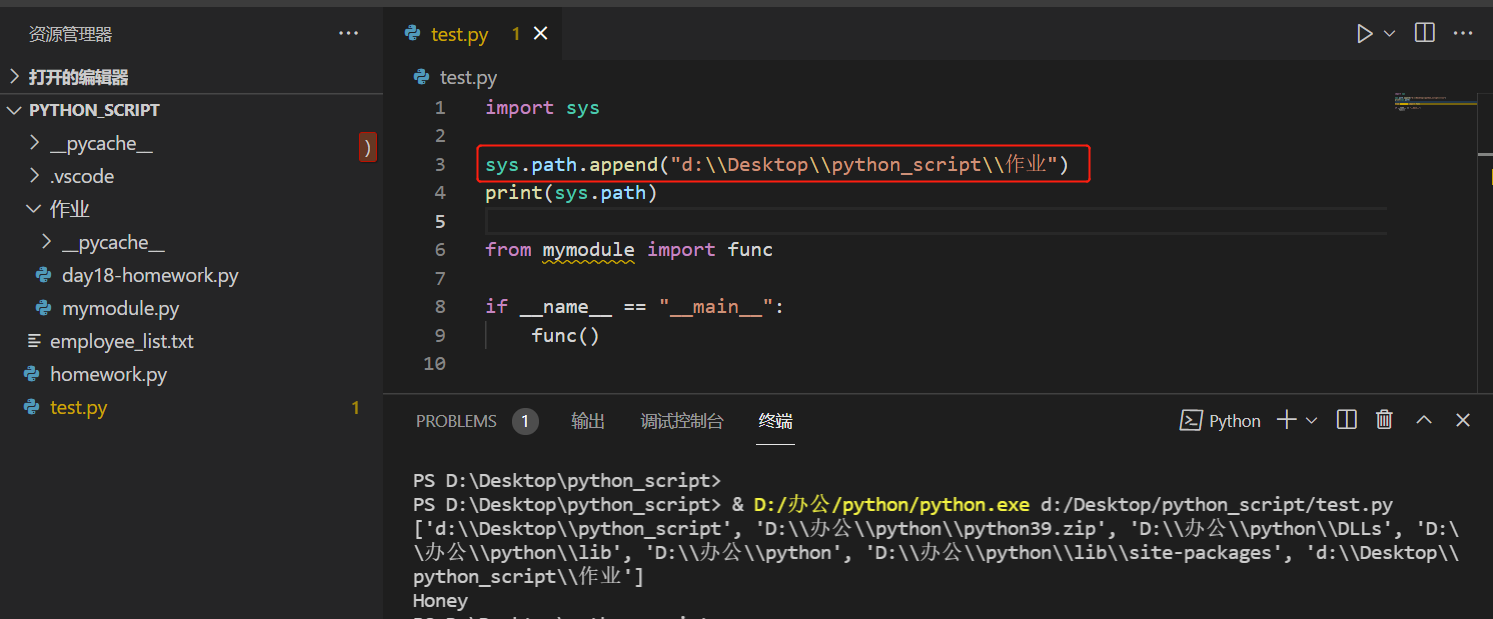
模块搜索路径 sys.path
加载模块时默认从sys.path的路径中加载,没有则会报错,一般自定义模块会容易出现此问题
如下图,将mymodule.py放在当前执行脚本test.py的同级目录作业下,作业路径不在sys.path中,就报错了
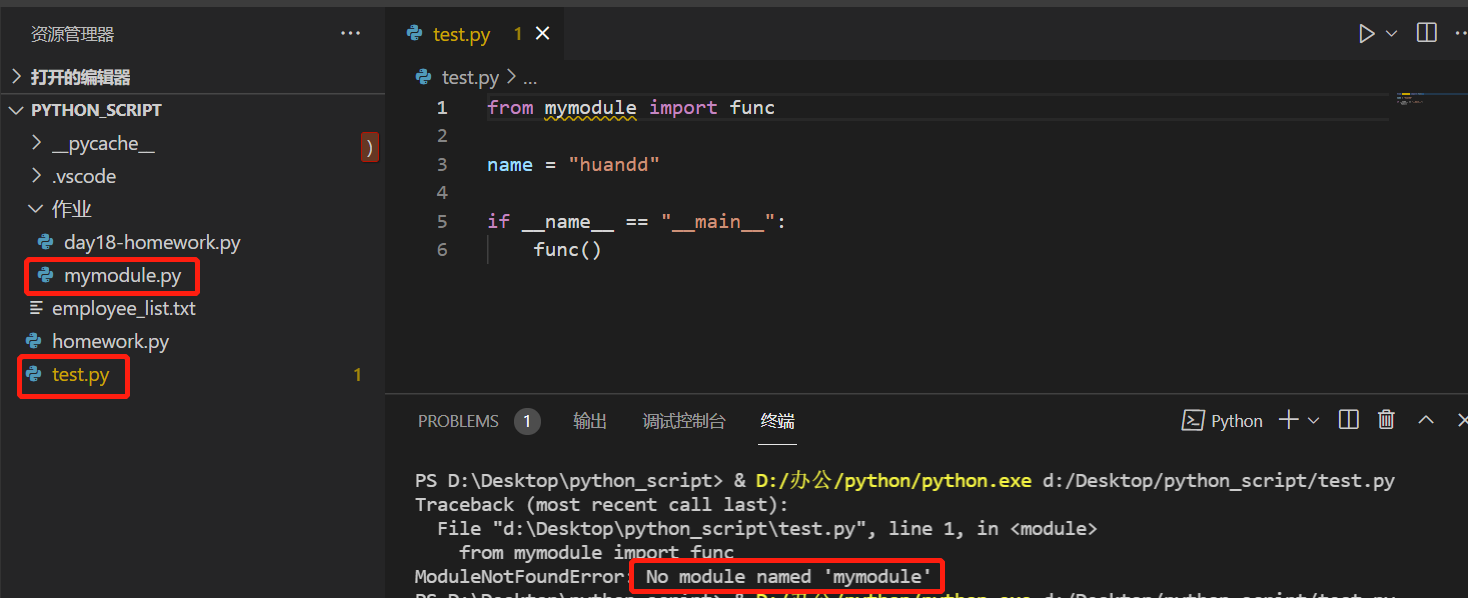
现将作业路径加入sys.path,mymodule模块便能正常加载
总结:
- 模块的搜索路径全部存储在sys.path列表中
- 导入模块的顺序,是从前到后找到一个符合条件的模块就立即停止不再向后寻找
- 如果要导入的模块和当前执行的文件同级:直接导入即可
- 如果要导入的模块和当前执行的文件不同级:需要把要导入模块的绝对路径添加到sys.path列表中
包
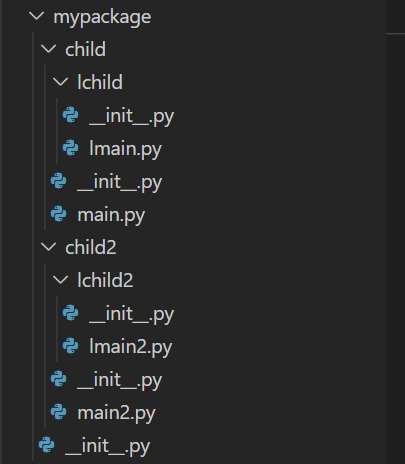
概念:包属于模块的一个分支,是一个包含多个模块的特殊目录,目录下有一个固定文件__init__.py
包与包之间可以嵌套
例如下图mypackage中就嵌套了包child与包child1,child与包child1又分别嵌套了lchild与lchild2
包的导入
导入某个包相当于执行了该包下面的那一个__init__.py文件
导入包的方法:
#当上图所有\_\_init\_\_都为空时:
#要使用child下main模块中的func方法
import mypackage.child.main
mypackage.child.main.func()
或者
from mypackage.child import main
main.func()
那能不能做到仅导入最外层包这个模块就能调用内层方法呢?
需要对其中__init__.py进行开发
在每一个包的__init__.py文件中导入与该init文件平级的所有包与模块
从绝对路径载入:
#要执行的脚本test.py与mypackage同级,那么sys.path中就有能找到mypackage的路径
#mypackage下的init文件为:
from mypackage import child
from mypackage import child2
print("in mypackage")
#child下的init文件为:
from mypackage.child import main
from mypackage.child import lchild
print("in child")
#lchild下的init文件为:
from mypackage.child.lchild import lmain
print("in lchild")
其他的child2与lchild2也是一样的配置
test.py执行:
import mypackage
#调用main中的func
mypackage.child.main.func()
输出:
in lchild
in child
in lchild2
in child2
in mypackage
in main
一旦我们更换test.py的目录,以上import路径又得改,所以可以将__init__.py 中的 from xxx import xxx改为 from . import xxx
从相对路径载入:
这种载入方式直接到包里运行__init__.py文件会报错,但不影响从外部其他文件加载包
#mypackage下的init文件为:
from . import child
from . import child2
print("in mypackage")
#child下的init文件为:
from . import main
from . import lchild
print("in child")
...
总结:
# 直接导入模块
# import 包.包.模块
# 调用: 包.包.模块.变量
# from 包.包 import 模块 # 推荐 平时写作业的过程
# 调用: 模块.变量
# 导入包 读框架源码的时候
# 如要希望导入包之后 模块能够正常的使用 那么需要自己去完成init文件的开发
# 包中模块的 绝对导入
# 包中模块的 相对导入
# 使用了相对导入的模块只能被当做模块执行
# 不能被当做脚本执行
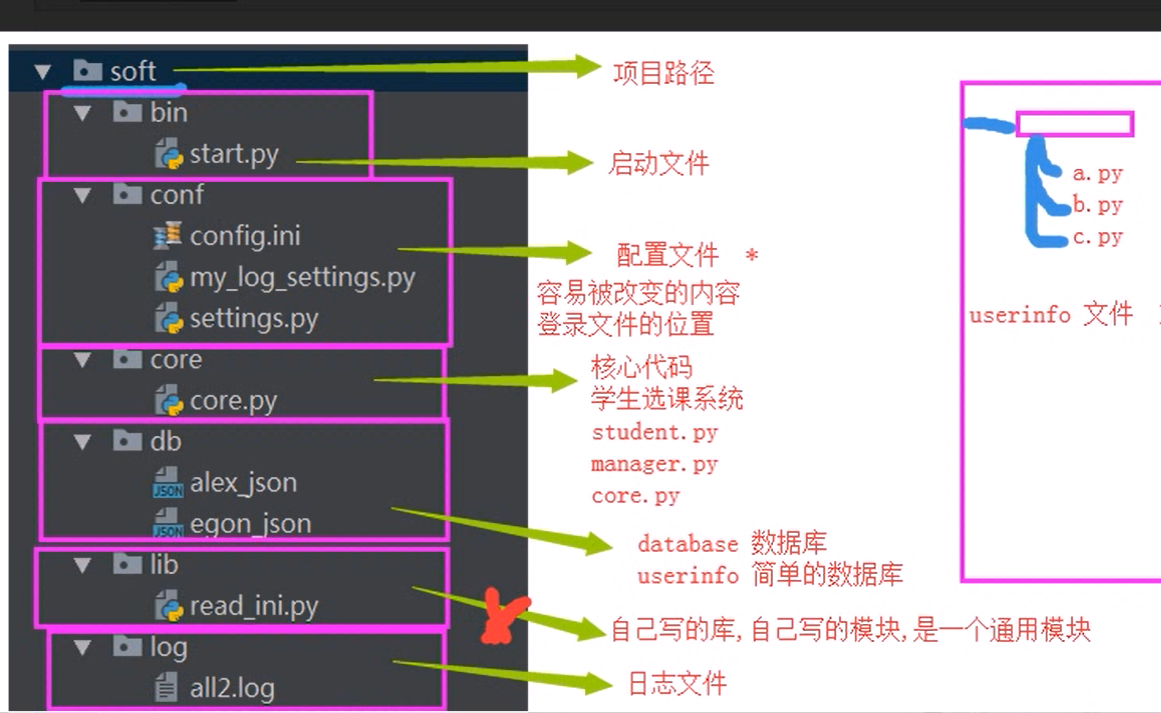
项目开发规范