整体注释:ctrl+?
1、运算符
+ - * / //(取商)
**(幂)
%(求余)
判断某个东西是否在某个东西里面包含: in not in
不等于:
<>
!=
a=a+1 等于 a+=1
a=a-1 等于 a-=1
a=a%1 等于 a%=1
结果是值
算数运算
a = 10 * 10
赋值运算
a = a + 1 a+=1
结果是布尔值
比较运算
a = 1 > 5
逻辑运算
a = 1>6 or 1==1
成员运算
a = "蚊" in "郑建文"
补充:
字节, 位
unicode utf8 gbk
utf8: 3
gbk : 2
2、基本数据类型:
1、数字 int 所有的功能都放在int里
在python3里,所有的整型都是int类型
12354544788545454111 int
在python2里,超过一定范围后,是long int类型
1215551531152515 long int
- int
将字符串转换为数字
a = "123"
print(type(a),a)
b = int(a)
print(type(b),b)
运行结果:<class'str'>123
<class'int'>123

- bit_lenght
# 当前数字的二进制,至少用n位表示
r = age.bit_length()
2、字符串 str
#s1=“huang”
#s2="wei"
text="huang"
#首字母大写
v=text.capitalize()
print(v)
运行结果:
Huang
text="huAng"
#所有变小写,casefold更牛逼,很多未知的对应关系也可以变小写
v=text.casefold()
print(v)
运行结果:
huang
text="huAng"
#平时用的,英文小写的转换
v=text.lower()
print(v)
#判断是否全部是小写,转换成小写 text="Huang" v1=text.islower() v2=text.lower() print(v1,v2)
运行结果:
False huang
1 #判断是否全部是大写,转换成大写 2 text="Huang" 3 v1=text.isupper() 4 v2=text.upper() 5 print(v1,v2)
运行结果:
False HUANG
#大写换小写,小写换大写,,同时转换 text="huAng" v=text.swapcase() print(v)
运行结果:
HUaNG
text="huang"
# 设置宽度,并将内容居中
# 20 代指总长度
#* 空白未知填充,一个字符,可有可无
v=text.center(20,"*")
print(v)
运行结果:
*******huang********
text="huang" #* 空白未知填充,一个字符,可有可无 #填充右边 v=text.ljust(20,'*') print(v)
运行结果:
huang***************
text="huang" #* 空白未知填充,一个字符,可有可无 #填充左边 v=text.rjust(20,'*') print(v)
运行结果:
***************huang
test="huanghuang"
#去字符串中寻找,寻找子序列的出现次数
v=test.count("a")
print(v)
运行结果:
2
test="huanghuang"
#去字符串中寻找,寻找子序列的出现次数
#后面的参数指起始位置到结束位置
v=test.count("a",2,6)
print(v)
运行结果:
1
test="huanghuang"
#以什么什么结尾
#以什么什么开始
v=test.endswith("ng")
v=test.startswith("u")
print(v)
#从开始往后找,找到第一个之后,获取其未知
#> 或 >=
test = "alexalex"
#未找到 -1
v = test.find('ex',1,6)
print(v)
#index找不到,报错 忽略
test = "alexalex"
v = test.index('8')
print(v)
# 格式化,将一个字符串中的占位符替换为指定的值
test = 'i am {name}, age {a}'
print(test)
v = test.format(name='alex',a=19)
print(v)
运行结果:
i am {name}, age {a}
i am alex, age 19
#格式化,传入的值 {"name": 'alex', "a": 19}
test = 'i am {name}, age {a}'
v1 = test.format(name='df',a=10)
v2 = test.format_map({"name": 'alex', "a": 19})
print(v1)
print(v2)
运行结果:
i am df, age 10
i am alex, age 19
#字符串中是否只包含 字母和数字
test = "123"
v = test.isalnum()
print(v)
#是否是字母,汉子
test = "5heer"
v = test.isalpha()
print(v)
# 当前输入是否是数字
test = "二" # 1,②
v1 = test.isdecimal() 十进制
v2 = test.isdigit() 特殊数字
v3 = test.isnumeric() 中文数字
print(v1,v2,v3)
# 是否存在不可显示的字符
# 制表符
#
换行
test = "oiuas dfkj"
v = test.isprintable()
print(v)
# 判断是否全部是空格
test = " "
v = test.isspace()
print(v)
#判断是否是标题
test = "Return True if all cased characters in S are uppercase and there is"
v1 = test.istitle()
print(v1)
v2 = test.title()
print(v2)
v3 = v2.istitle()
print(v3)
运行结果:
False
Return True If All Cased Characters In S Are Uppercase And There Is
True
# ** ** *将字符串中的每一个元素按照指定分隔符进行拼接
test = "你是风儿我是沙"
print(test)
#t = ' '
v = "_".join(test)
print(v)
运行结果:
你是风儿我是沙
你_是_风_儿_我_是_沙
#去除
#移除指定字符串
text=" huang "
v1=text.lstrip()#去除左边空白
print(v1)
v2=text.rstrip()
print(v2)#去除右边空白
v3=text.strip()
print(v3)#去除两边空白
#对应关系替换 test = "aeiou" test1 = "12345" v = "asidufkasd;fiuadkf;adfkjalsdjf" m = str.maketrans("aeiou", "12345") new_v = v.translate(m) print(new_v)
运行结果:
1s3d5fk1sd;f351dkf;1dfkj1lsdjf
#分割为三部分 test = "testasdsddfg" v = test.partition('s') print(v) v = test.rpartition('s') print(v)
#分割为指定个数,但不包括定位符
test = "testasdsddfg"
v = test.split('s',2)
print(v)
test.rsplit()
#分割,只能根据换行符分割 ,true,false:是否保留换行符
test = "asdfadfasdf
asdfasdf
adfasdf"
v= test.splitlines(False)
print(v)
#以xxx开头,以xx结尾
test = "backend 1.1.1.1"
v = test.startswith('a')
print(v)
#test.endswith('a)


1 #将指定字符串替换为指定字符串 2 test = "alexalexalex" 3 v = test.replace("ex",'bbb') 4 print(v) 5 v = test.replace("ex",'bbb',2) 6 print(v)
-------------------7个 基本魔法
join
split
find
strip
upper
lower
replce
--------------------灰魔法(几乎所有的数据类型都能使用)
1、#索引,下标,获取字符串中的某个字符
text="huang"
v=text[0]
print(v)
2、#索引,下标,获取字符串中的某个字符
text="huang"
#[0:-1]指到最后位置
v=text [0:3]#索引范围,0=<范围<3 切片
print(v)
v=len(text)#len 获取字符串里面由多少字符组成
print(v)
3、 for循环:
for 变量名 in 字符串:
print()
1 text="敢问今夕是何年" 2 for abc in text: 3 print(abc)
4、len
5、rang
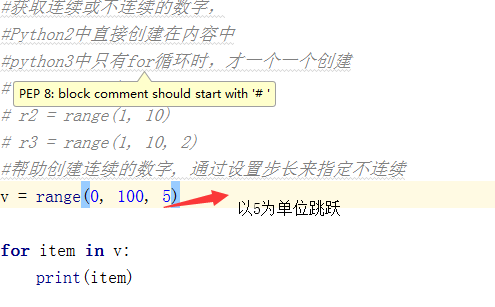
1 #将文字对应的索引打印出来: 2 text=input(">>>") 3 for item in range(0,len(text)): 4 print(item,text[item]) 5 6 运行结果: 7 >>>huang 8 0 h 9 1 u 10 2 a 11 3 n 12 4 g
1 test = input(">>>") 2 print(test) # test = qwe test[0] test[1] 3 l = len(test) # l = 3 4 print(l) 5 r=range(0,3) 6 for item in r: 7 print(item,test[item]) 8 运行结果: 9 >>>huang 10 huang 11 5 12 0 h 13 1 u 14 2 a
#断句
text="username email password
huang 135168@qq.com 123
huang 123151@qq.com 123
huang 1641115@qq.com 123"
v=text.expandtabs(20)
print(v)
运行结果:
username email password
huang 135168@qq.com 123
huang 123151@qq.com 123
huang 1641115@qq.com 123
###################### 1个深灰魔法 ######################
# 字符串一旦创建,不可修改
# 一旦修改或者拼接,都会造成重新生成字符串
# name = "zhengjianwen"
# age = "18"
#
# info = name + age
# print(info)
3、列表 list
4、元祖 tuple
5、字典 dict
6、布尔值 bool