问题导读:
1.spark是如何提交作业的?
2.Akka框架是如何实现的?
3.如何实现调度的?![]()
前言
折腾了很久,终于开始学习Spark的源码了,第一篇我打算讲一下Spark作业的提交过程。
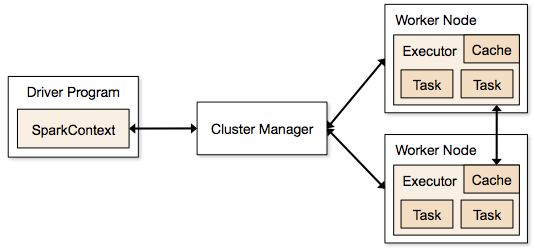
这个是Spark的App运行图,它通过一个Driver来和集群通信,集群负责作业的分配。今天我要讲的是如何创建这个Driver Program的过程。
1、作业提交方法以及参数
我们先看一下用Spark Submit提交的方法吧,下面是从官方上面摘抄的内容。
# Run on a Spark standalone cluster ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://207.184.161.138:7077 --executor-memory 20G --total-executor-cores 100 /path/to/examples.jar 1000
这个是提交到standalone集群的方式,打开spark-submit这文件,我们会发现它最后是调用了org.apache.spark.deploy.SparkSubmit这个类。
我们直接进去看就行了,main函数就几行代码,太节省了。
def main(args: Array[String]) { val appArgs = new SparkSubmitArguments(args) val (childArgs, classpath, sysProps, mainClass) = createLaunchEnv(appArgs) launch(childArgs, classpath, sysProps, mainClass, appArgs.verbose) }
我们主要看看createLaunchEnv方法就可以了,launch是反射调用mainClass,精华全在createLaunchEnv里面了。
在里面我发现一些有用的信息,可能在官方文档上面都没有的,发出来大家瞅瞅。前面不带--的可以在spark-defaults.conf里面设置,带--的直接在提交的时候指定,具体含义大家一看就懂。
val options = List[OptionAssigner]( OptionAssigner(args.master, ALL_CLUSTER_MGRS, false, sysProp = "spark.master"), OptionAssigner(args.name, ALL_CLUSTER_MGRS, false, sysProp = "spark.app.name"), OptionAssigner(args.name, YARN, true, clOption = "--name", sysProp = "spark.app.name"), OptionAssigner(args.driverExtraClassPath, STANDALONE | YARN, true, sysProp = "spark.driver.extraClassPath"), OptionAssigner(args.driverExtraJavaOptions, STANDALONE | YARN, true, sysProp = "spark.driver.extraJavaOptions"), OptionAssigner(args.driverExtraLibraryPath, STANDALONE | YARN, true, sysProp = "spark.driver.extraLibraryPath"), OptionAssigner(args.driverMemory, YARN, true, clOption = "--driver-memory"), OptionAssigner(args.driverMemory, STANDALONE, true, clOption = "--memory"), OptionAssigner(args.driverCores, STANDALONE, true, clOption = "--cores"), OptionAssigner(args.queue, YARN, true, clOption = "--queue"), OptionAssigner(args.queue, YARN, false, sysProp = "spark.yarn.queue"), OptionAssigner(args.numExecutors, YARN, true, clOption = "--num-executors"), OptionAssigner(args.numExecutors, YARN, false, sysProp = "spark.executor.instances"), OptionAssigner(args.executorMemory, YARN, true, clOption = "--executor-memory"), OptionAssigner(args.executorMemory, STANDALONE | MESOS | YARN, false, sysProp = "spark.executor.memory"), OptionAssigner(args.executorCores, YARN, true, clOption = "--executor-cores"), OptionAssigner(args.executorCores, YARN, false, sysProp = "spark.executor.cores"), OptionAssigner(args.totalExecutorCores, STANDALONE | MESOS, false, sysProp = "spark.cores.max"), OptionAssigner(args.files, YARN, false, sysProp = "spark.yarn.dist.files"), OptionAssigner(args.files, YARN, true, clOption = "--files"), OptionAssigner(args.files, LOCAL | STANDALONE | MESOS, false, sysProp = "spark.files"), OptionAssigner(args.files, LOCAL | STANDALONE | MESOS, true, sysProp = "spark.files"), OptionAssigner(args.archives, YARN, false, sysProp = "spark.yarn.dist.archives"), OptionAssigner(args.archives, YARN, true, clOption = "--archives"), OptionAssigner(args.jars, YARN, true, clOption = "--addJars"), OptionAssigner(args.jars, ALL_CLUSTER_MGRS, false, sysProp = "spark.jars") )
Driver程序的部署模式有两种,client和cluster,默认是client。client的话默认就是直接在本地运行了Driver程序了,cluster模式还会兜一圈把作业发到集群上面去运行。
指定部署模式需要用参数--deploy-mode来指定,或者在环境变量当中添加DEPLOY_MODE变量来指定。
下面讲的是cluster的部署方式,兜一圈的这种情况。
yarn模式的话mainClass是org.apache.spark.deploy.yarn.Client,standalone的mainClass是org.apache.spark.deploy.Client。
这次我们讲org.apache.spark.deploy.Client,yarn的话单独找一章出来单独讲,目前超哥还是推荐使用standalone的方式部署spark,具体原因不详,据说是因为资源调度方面的问题。
说个快捷键吧,Ctrl+Shift+N,然后输入Client就能找到这个类,这是IDEA的快捷键,相当好使。
我们直接找到它的main函数,发现了它居然使用了Akka框架,我百度了一下,被它震惊了。
2、Akka
在main函数里面,主要代码就这么三行。
//创建一个ActorSystem val (actorSystem, _) = AkkaUtils.createActorSystem("driverClient",Utils.localHostName(),0, conf, new SecurityManager(conf)) //执行ClientActor的preStart方法和receive方法 actorSystem.actorOf(Props(classOf[ClientActor], driverArgs, conf)) //等待运行结束 actorSystem.awaitTermination()
看了这里真的有点儿懵啊,这是啥玩意儿,不懂的朋友们,请点击这里Akka。下面是它官方放出来的例子:
//定义一个case class用来传递参数 case class Greeting(who: String) //定义Actor,比较重要的一个方法是receive方法,用来接收信息的 class GreetingActor extends Actor with ActorLogging { def receive = { case Greeting(who) ⇒ log.info("Hello " + who) } } //创建一个ActorSystem val system = ActorSystem("MySystem") //给ActorSystem设置Actor val greeter = system.actorOf(Props[GreetingActor], name = "greeter") //向greeter发送信息,用Greeting来传递 greeter ! Greeting("Charlie Parker")
简直是无比强大啊,就这么几行代码就搞定了,接下来看你会更加震惊的。
我们回到Client类当中,找到ClientActor,它有两个方法,是之前说的preStart和receive方法,preStart方法用于连接master提交作业请求,receive方法用于接收从master返回的反馈信息。
我们先看preStart方法吧。
override def preStart() = { // 这里需要把master的地址转换成akka的地址,然后通过这个akka地址获得指定的actor // 它的格式是"akka.tcp://%s@%s:%s/user/%s".format(systemName, host, port, actorName) masterActor = context.actorSelection(Master.toAkkaUrl(driverArgs.master)) // 把自身设置成远程生命周期的事件 context.system.eventStream.subscribe(self, classOf[RemotingLifecycleEvent]) driverArgs.cmd match { case "launch" => // 此处省略100个字 val mainClass = "org.apache.spark.deploy.worker.DriverWrapper" // 此处省略100个字 // 向master发送提交Driver的请求,把driverDescription传过去,RequestSubmitDriver前面说过了,是个case class masterActor ! RequestSubmitDriver(driverDescription) case "kill" => val driverId = driverArgs.driverId val killFuture = masterActor ! RequestKillDriver(driverId) } }
从上面的代码看得出来,它需要设置master的连接地址,最后提交了一个RequestSubmitDriver的信息。在receive方法里面,就是等待接受回应了,有两个Response分别对应着这里的launch和kill。
线索貌似到这里就断了,那下一步在哪里了呢?当然是在Master里面啦,怎么知道的,猜的,哈哈。
Master也是继承了Actor,在它的main函数里面找到了以下代码:
val (actorSystem, boundPort) = AkkaUtils.createActorSystem(systemName, host, port, conf = conf, securityManager = securityMgr) val actor = actorSystem.actorOf(Props(classOf[Master], host, boundPort, webUiPort, securityMgr), actorName) val timeout = AkkaUtils.askTimeout(conf) val respFuture = actor.ask(RequestWebUIPort)(timeout) val resp = Await.result(respFuture, timeout).asInstanceOf[WebUIPortResponse]
和前面的actor基本一致,多了actor.ask这句话,查了一下官网的文档,这句话的意思的发送消息,并且接受一个Future作为response,和前面的actor ! message的区别就是它还接受返回值。
具体的Akka的用法,大家还是参照官网吧,Akka确实如它官网所言的那样子,是一个简单、强大、并行的分布式框架。
小结:
Akka的使用确实简单,短短的几行代码即刻完成一个通信功能,比Socket简单很多。但是它也逃不脱我们常说的那些东西,请求、接收请求、传递的消息、注册的地址和端口这些概念。
3、调度schedule
我们接下来查找Master的receive方法吧,Master是作为接收方的,而不是主动请求,这点和hadoop是一致的。
case RequestSubmitDriver(description) => { val driver = createDriver(description) persistenceEngine.addDriver(driver) waitingDrivers += driver drivers.add(driver) // 调度 schedule() // 告诉client,提交成功了,把driver.id告诉它 sender ! SubmitDriverResponse(true, Some(driver.id), s"Driver successfully submitted as ${driver.id}") }
这里我们主要看schedule方法就可以了,它是执行调度的方法。
private def schedule() { if (state != RecoveryState.ALIVE) { return } // 首先调度Driver程序,从workers里面随机抽一些出来 val shuffledWorkers = Random.shuffle(workers) for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) { for (driver <- waitingDrivers) { // 判断内存和cpu够不够,够的就执行了哈 if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) { launchDriver(worker, driver) waitingDrivers -= driver } } } // 这里是按照先进先出的,spreadOutApps是由spark.deploy.spreadOut参数来决定的,默认是true if (spreadOutApps) { // 遍历一下app for (app <- waitingApps if app.coresLeft > 0) { // canUse里面判断了worker的内存是否够用,并且该worker是否已经包含了该app的Executor val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE) .filter(canUse(app, _)).sortBy(_.coresFree).reverse val numUsable = usableWorkers.length val assigned = new Array[Int](numUsable) // 记录每个节点的核心数 var toAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum) var pos = 0 // 遍历直到分配结束 while (toAssign > 0) { // 从0开始遍历可用的work,如果可用的cpu减去已经分配的>0,就可以分配给它 if (usableWorkers(pos).coresFree - assigned(pos) > 0) { toAssign -= 1 // 这个位置的work的可分配的cpu数+1 assigned(pos) += 1 } pos = (pos + 1) % numUsable } // 给刚才标记的worker分配任务 for (pos <- 0 until numUsable) { if (assigned(pos) > 0) { val exec = app.addExecutor(usableWorkers(pos), assigned(pos)) launchExecutor(usableWorkers(pos), exec) app.state = ApplicationState.RUNNING } } } } else { // 这种方式和上面的方式的区别是,这种方式尽可能用少量的节点来完成这个任务 for (worker <- workers if worker.coresFree > 0 && worker.state == WorkerState.ALIVE) { for (app <- waitingApps if app.coresLeft > 0) { // 判断条件是worker的内存比app需要的内存多 if (canUse(app, worker)) { val coresToUse = math.min(worker.coresFree, app.coresLeft) if (coresToUse > 0) { val exec = app.addExecutor(worker, coresToUse) launchExecutor(worker, exec) app.state = ApplicationState.RUNNING } } } } } }
它的调度器是这样的,先调度Driver程序,然后再调度App,调度App的方式是从各个worker的里面和App进行匹配,看需要分配多少个cpu。
那我们接下来看两个方法launchDriver和launchExecutor即可。
def launchDriver(worker: WorkerInfo, driver: DriverInfo) { logInfo("Launching driver " + driver.id + " on worker " + worker.id) worker.addDriver(driver) driver.worker = Some(worker) worker.actor ! LaunchDriver(driver.id, driver.desc) driver.state = DriverState.RUNNING }
给worker发送了一个LaunchDriver的消息,下面在看launchExecutor的方法。
def launchExecutor(worker: WorkerInfo, exec: ExecutorInfo) { logInfo("Launching executor " + exec.fullId + " on worker " + worker.id) worker.addExecutor(exec) worker.actor ! LaunchExecutor(masterUrl, exec.application.id, exec.id, exec.application.desc, exec.cores, exec.memory) exec.application.driver ! ExecutorAdded( exec.id, worker.id, worker.hostPort, exec.cores, exec.memory) }
它要做的事情多一点,除了给worker发送LaunchExecutor指令外,还需要给driver发送ExecutorAdded的消息,说你的任务已经有人干了。
在继续Worker讲之前,我们先看看它是怎么注册进来的,每个Worker启动之后,会自动去请求Master去注册自己,具体我们可以看receive的方法里面的RegisterWorker这一段,它需要上报自己的内存、Cpu、地址、端口等信息,注册成功之后返回RegisteredWorker信息给它,说已经注册成功了。
4、Worker执行
同样的,我们到Worker里面在receive方法找LaunchDriver和LaunchExecutor就可以找到我们要的东西。
case LaunchDriver(driverId, driverDesc) => { logInfo(s"Asked to launch driver $driverId") val driver = new DriverRunner(driverId, workDir, sparkHome, driverDesc, self, akkaUrl) drivers(driverId) = driver driver.start() coresUsed += driverDesc.cores memoryUsed += driverDesc.mem }
看一下start方法吧,start方法里面,其实是new Thread().start(),run方法里面是通过传过来的DriverDescription构造的一个命令,丢给ProcessBuilder去执行命令,结束之后调用。
worker !DriverStateChanged通知worker,worker再通过master ! DriverStateChanged通知master,释放掉worker的cpu和内存。
同理,LaunchExecutor执行完毕了,通过worker ! ExecutorStateChanged通知worker,然后worker通过master ! ExecutorStateChanged通知master,释放掉worker的cpu和内存。
下面我们再梳理一下这个过程,只包括Driver注册,Driver运行之后的过程在之后的文章再说,比较复杂。
1、Client通过获得Url地址获得ActorSelection(master的actor引用),然后通过ActorSelection给Master发送注册Driver请求(RequestSubmitDriver)
2、Master接收到请求之后就开始调度了,从workers列表里面找出可以用的Worker
3、通过Worker的actor引用ActorRef给可用的Worker发送启动Driver请求(LaunchDriver)
4、调度完毕之后,给Client回复注册成功消息(SubmitDriverResponse)
5、Worker接收到LaunchDriver请求之后,通过传过来的DriverDescription的信息构造出命令来,通过ProcessBuilder执行
6、ProcessBuilder执行完命令之后,通过DriverStateChanged通过Worker
7、Worker最后把DriverStateChanged汇报给Master