问题导读
1、什么是Catalyst?
2、对Hive的兼容支持将转移到什么上?
3、TreeNode具备哪些对节点的操作方法?![]()
摘要:
本文作者整理了对Spark SQL各个模块的实现情况、代码结构、执行流程情况以及分享了对Spark SQL的理解,无论是从源码实现,还是从Spark SQL实际使用角度,这些都很有参考价值。
在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。日前张包峰的博客上分享了Spark SQL各个模块的实现情况、代码结构、执行流程以及对Spark SQL的理解。
Catalyst
Catalyst是与Spark解耦的一个独立库,是一个impl-free的执行计划的生成和优化框架。
目前与Spark Core还是耦合的,对此user邮件组里有人对此提出疑问,见mail。
以下是Catalyst较早时候的架构图,展示的是代码结构和处理流程。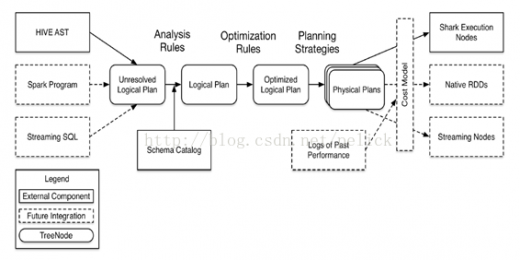
Catalyst定位
其他系统如果想基于Spark做一些类sql、标准sql甚至其他查询语言的查询,需要基于Catalyst提供的解析器、执行计划树结构、逻辑执行计划的处理规则体系等类体系来实现执行计划的解析、生成、优化、映射工作。
对应上图中,主要是左侧的TreeNodelib及中间三次转化过程中涉及到的类结构都是Catalyst提供的。至于右侧物理执行计划映射生成过程,物理执行计划基于成本的优化模型,具体物理算子的执行都由系统自己实现。
Catalyst现状
在解析器方面提供的是一个简单的scala写的sql parser,支持语义有限,而且应该是标准sql的。
在规则方面,提供的优化规则是比较基础的(和Pig/Hive比没有那么丰富),不过一些优化规则其实是要涉及到具体物理算子的,所以部分规则需要在系统方那自己制定和实现(如spark-sql里的SparkStrategy)。
Catalyst也有自己的一套数据类型。
下面介绍Catalyst里几套重要的类结构。
TreeNode体系
TreeNode是Catalyst执行计划表示的数据结构,是一个树结构,具备一些scala collection的操作能力和树遍历能力。这棵树一直在内存里维护,不会dump到磁盘以某种格式的文件存在,且无论在映射逻辑执行计划阶段还是优化逻辑执行计划阶段,树的修改是以替换已有节点的方式进行的。
TreeNode,内部带一个children: Seq[BaseType]表示孩子节点,具备foreach、map、collect等针对节点操作的方法,以及transformDown(默认,前序遍历)、transformUp这样的遍历树上节点,对匹配节点实施变化的方法。
提供UnaryNode,BinaryNode, LeafNode三种trait,即非叶子节点允许有一个或两个子节点。
TreeNode提供的是范型。
TreeNode有两个子类继承体系,QueryPlan和Expression。QueryPlan下面是逻辑和物理执行计划两个体系,前者在Catalyst里有详细实现,后者需要在系统自己实现。Expression是表达式体系,后面章节都会展开介绍。
Tree的transformation实现:
传入PartialFunction[TreeType,TreeType],如果与操作符匹配,则节点会被结果替换掉,否则节点不会变动。整个过程是对children递归执行的。
执行计划表示模型
逻辑执行计划
QueryPlan继承自TreeNode,内部带一个output: Seq[Attribute],具备transformExpressionDown、transformExpressionUp方法。
在Catalyst中,QueryPlan的主要子类体系是LogicalPlan,即逻辑执行计划表示。其物理执行计划表示由使用方实现(spark-sql项目中)。
LogicalPlan继承自QueryPlan,内部带一个reference:Set[Attribute],主要方法为resolve(name:String): Option[NamedeExpression],用于分析生成对应的NamedExpression。
LogicalPlan有许多具体子类,也分为UnaryNode, BinaryNode, LeafNode三类,具体在org.apache.spark.sql.catalyst.plans.logical路径下。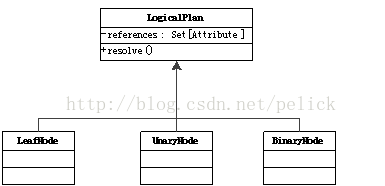
逻辑执行计划实现
LeafNode主要子类是Command体系:
各command的语义可以从子类名字看出,代表的是系统可以执行的non-query命令,如DDL。
UnaryNode的子类:
BinaryNode的子类:
物理执行计划
另一方面,物理执行计划节点在具体系统里实现,比如spark-sql工程里的SparkPlan继承体系。
物理执行计划实现
每个子类都要实现execute()方法,大致有以下实现子类(不全)。
提到物理执行计划,还要提一下Catalyst提供的分区表示模型。
执行计划映射
Catalyst还提供了一个QueryPlanner[Physical <: TreeNode[PhysicalPlan]]抽象类,需要子类制定一批strategies: Seq[Strategy],其apply方法也是类似根据制定的具体策略来把逻辑执行计划算子映射成物理执行计划算子。由于物理执行计划的节点是在具体系统里实现的,所以QueryPlanner及里面的strategies也需要在具体系统里实现。
在spark-sql项目中,SparkStrategies继承了QueryPlanner[SparkPlan],内部制定了LeftSemiJoin, HashJoin,PartialAggregation, BroadcastNestedLoopJoin, CartesianProduct等几种策略,每种策略接受的都是一个LogicalPlan,生成的是Seq[SparkPlan],每个SparkPlan理解为具体RDD的算子操作。
比如在BasicOperators这个Strategy里,以match-case匹配的方式处理了很多基本算子(可以一对一直接映射成RDD算子),如下:
Expression体系
Expression,即表达式,指不需要执行引擎计算,而可以直接计算或处理的节点,包括Cast操作,Projection操作,四则运算,逻辑操作符运算等。
具体可以参考org.apache.spark.sql.expressionspackage下的类。
Rules体系
凡是需要处理执行计划树(Analyze过程,Optimize过程,SparkStrategy过程),实施规则匹配和节点处理的,都需要继承RuleExecutor[TreeType]抽象类。
RuleExecutor内部提供了一个Seq[Batch],里面定义的是该RuleExecutor的处理步骤。每个Batch代表着一套规则,配备一个策略,该策略说明了迭代次数(一次还是多次)。
Rule[TreeType <: TreeNode[_]]是一个抽象类,子类需要复写apply(plan: TreeType)方法来制定处理逻辑。
RuleExecutor的apply(plan: TreeType): TreeType方法会按照batches顺序和batch内的Rules顺序,对传入的plan里的节点迭代处理,处理逻辑为由具体Rule子类实现。
Hive相关
Hive支持方式
Spark SQL对hive的支持是单独的spark-hive项目,对Hive的支持包括HQL查询、hive metaStore信息、hive SerDes、hive UDFs/UDAFs/ UDTFs,类似Shark。
只有在HiveContext下通过hive api获得的数据集,才可以使用hql进行查询,其hql的解析依赖的是org.apache.hadoop.hive.ql.parse.ParseDriver类的parse方法,生成Hive AST。
实际上sql和hql,并不是一起支持的。可以理解为hql是独立支持的,能被hql查询的数据集必须读取自hive api。下图中的parquet、json等其他文件支持只发生在sql环境下(SQLContext)。
Hive on Spark
Hive官方提出了Hive onSpark的JIRA。Shark结束之后,拆分为两个方向:
从这里看,对Hive的兼容支持将转移到Hive on Spark上,之前Shark的经验将在Hive社区的这个支持上体现。我理解,目前SparkSQL里的那种Hive支持方式,只是为了在Spark环境下集成操纵Hive数据,它的hql执行是调用Hive客户端Driver,跑在hadoop MR上的,本身不是Hive on Spark的实现,只是为了使用RDD间接操作Hive数据集。
所以如果想要把现有Hive任务迁移到Spark上,应该使用Shark或者等待Hive on Spark。
Spark SQL里的Hive支持不是hive on spark的实现,而更像一个读写Hive数据的客户端。且其hql支持只包含hive数据,与sql环境是互相独立的。
以上两节是Spark SQL Hive、Shark、Hive on Spark的区别和理解。