1、在服务器(虚拟机)spark-shell连接hive
1.1 将hive-site.xml拷贝到spark/conf里
cp /opt/apache-hive-2.3.2-bin/conf/hive-site.xml /opt/spark-2.2.1-bin-hadoop2.7/conf/
1.2 将mysql驱动拷贝到spark/jar里
cp /opt/apache-hive-2.3.2-bin/bin/mysql-connector-java-5.1.46-bin.jar /opt/spark-2.2.1-bin-hadoop2.7/jars/
1.3 启动spark-shell,输入代码测试
spark-shell import org.apache.spark.sql.hive.HiveContext val hiveContext = new HiveContext(sc) hiveContext.sql("select * from test").show()

1.4 异常及解决
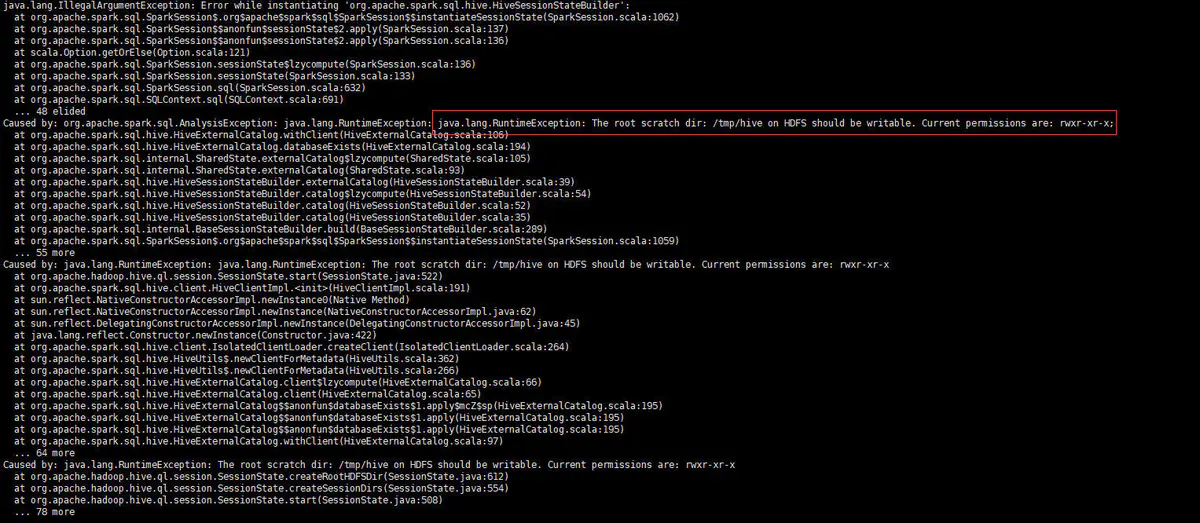
在执行hiveContext.sql("select * from test").show() 报了一个异常:
The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: rwxr-xr-x;
解决办法:
1.4.1 更改HDFS目录/tmp/hive的权限:
hadoop fs -chmod 777 /tmp/hive
1.4.2 同时删HDFS与本地的目录/tmp/hive:
hadoop fs -rm -r /tmp/hive rm -rf /tmp/hive
这次错误采用的是第二种解决办法,有的情况下用第一种方法,比如一次在启动hive时候报这种错误~。
错误截图:
2、win10+eclipse上连接hive
2.1 将hive-site.xml拷贝到项目中的resources文件夹下


2.2 在sbt里添加对应版本的mysql依赖
"mysql" % "mysql-connector-java" % "5.1.46"
2.3 代码
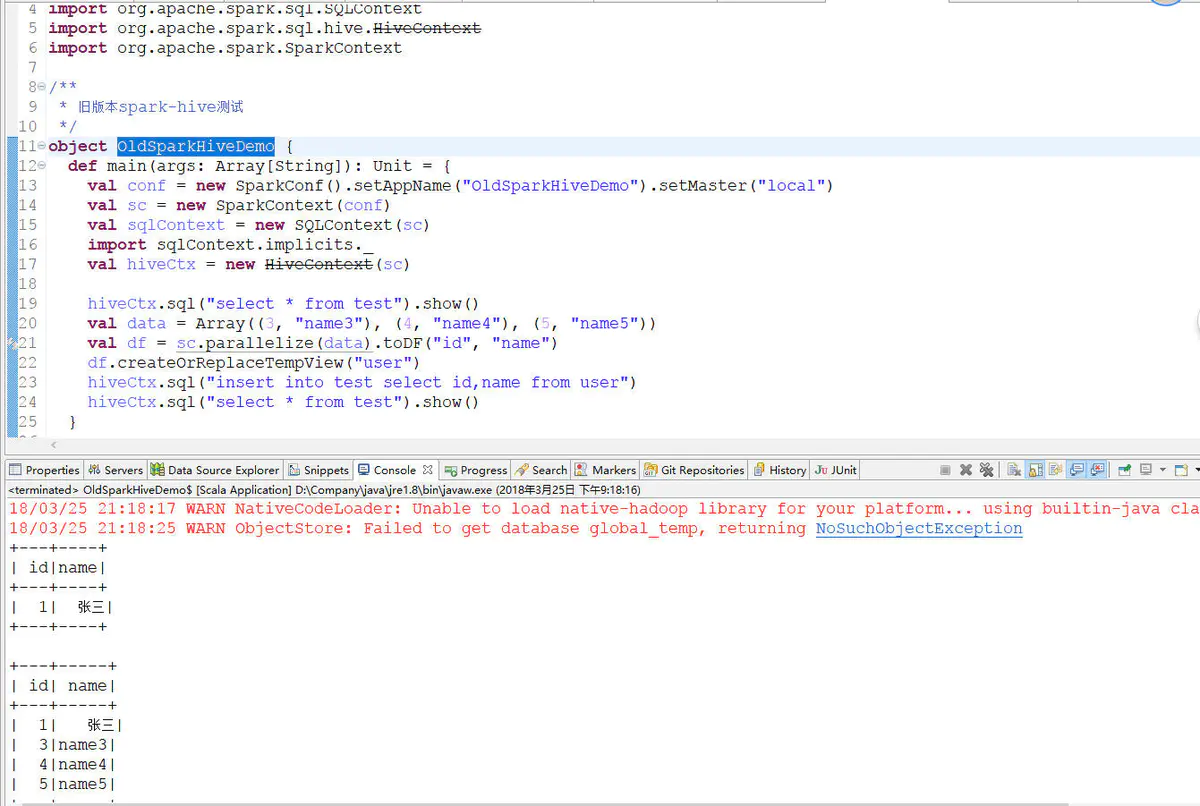
2.3.1 旧版api(1.6以上)
package com.dkl.leanring.spark.sql import org.apache.spark.SparkConf import org.apache.spark.sql.SQLContext import org.apache.spark.sql.hive.HiveContext import org.apache.spark.SparkContext /** * 旧版本spark-hive测试 */ object OldSparkHiveDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("OldSparkHiveDemo").setMaster("local") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) import sqlContext.implicits._ val hiveCtx = new HiveContext(sc) hiveCtx.sql("select * from test").show() val data = Array((3, "name3"), (4, "name4"), (5, "name5")) val df = sc.parallelize(data).toDF("id", "name") df.createOrReplaceTempView("user") hiveCtx.sql("insert into test select id,name from user") hiveCtx.sql("select * from test").show() } }
(注:其中df.createOrReplaceTempView("user")改为df.registerTempTable("user"),因为createOrReplaceTempView方法是2.0.0才有的,registerTempTable是旧版的方法,1.6.0就有了,嫌麻烦就不改代码重新贴图了)
2.3.2 新版api
package com.dkl.leanring.spark.sql import org.apache.spark.sql.SparkSession /** * 新版本spark-hive测试 */ object NewSparkHiveDemo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("Spark Hive Example") .master("local") .config("spark.sql.warehouse.dir", "/user/hive/warehouse/") .enableHiveSupport() .getOrCreate() import spark.implicits._ import spark.sql sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)") val data = Array((1, "val1"), (2, "val2"), (3, "val3")) var df = spark.createDataFrame(data).toDF("key", "value") df.createOrReplaceTempView("temp_src") sql("insert into src select key,value from temp_src") sql("SELECT * FROM src").show() } }
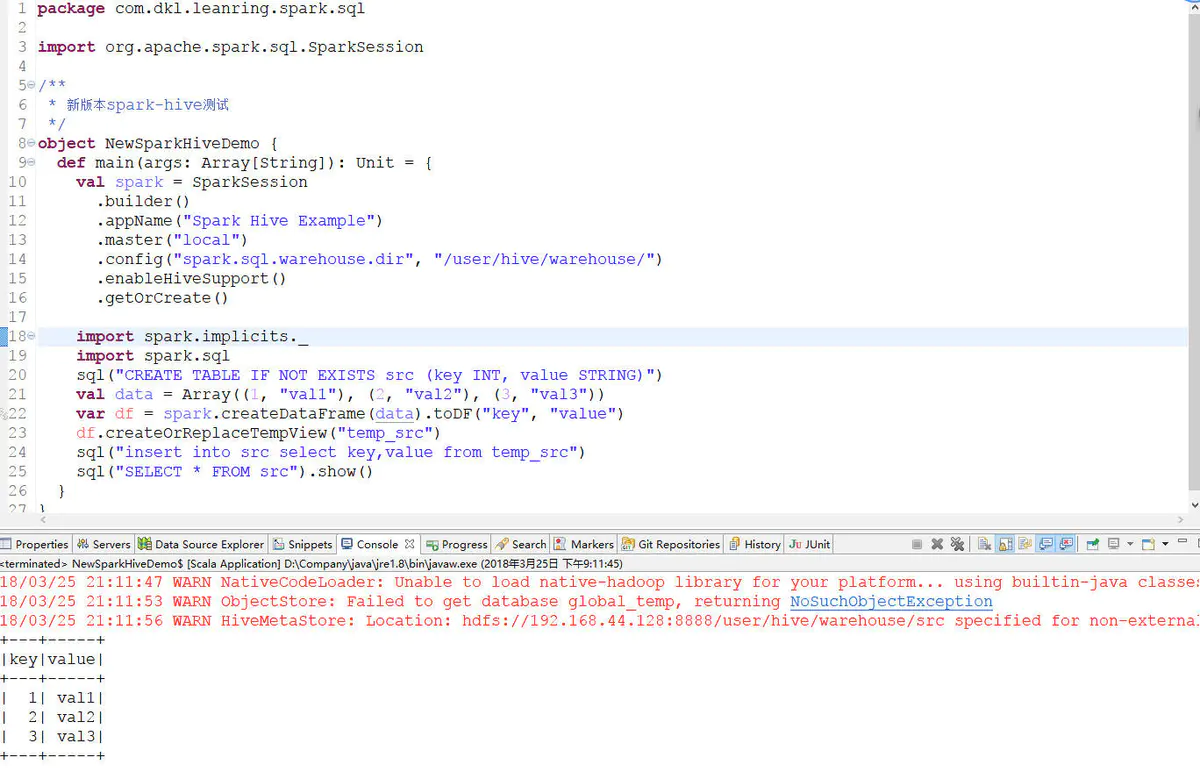
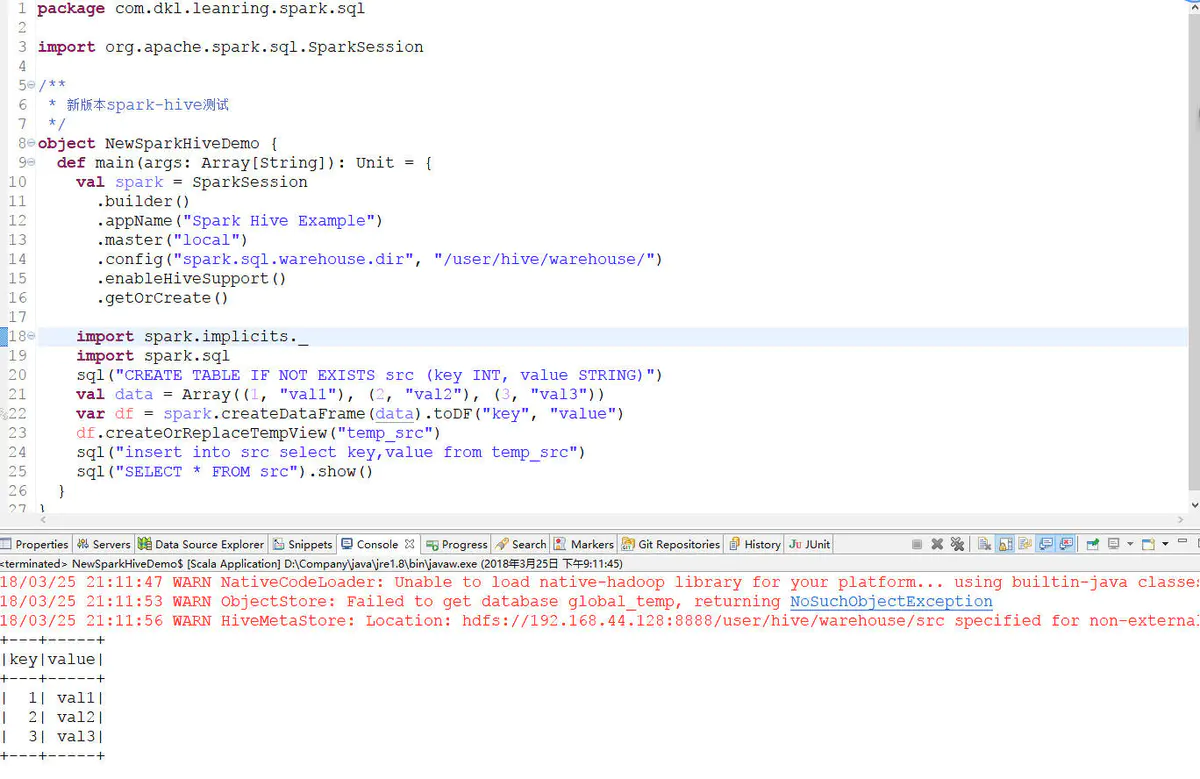
2.4 异常及解决方法
在执行insert语句时会出现如下异常信息:
org.apache.hadoop.security.AccessControlException: Permission denied: user=dongkelun, access=EXECUTE, inode="/user/hive/warehouse":root...
原因是:启动 Spark 应用程序的win用户对spark.sql.warehouse.dir没有写权限
解决办法:
hadoop fs -chmod 777 /user/hive/warehouse/
附异常信息截图: