1、Python3 函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
1、定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
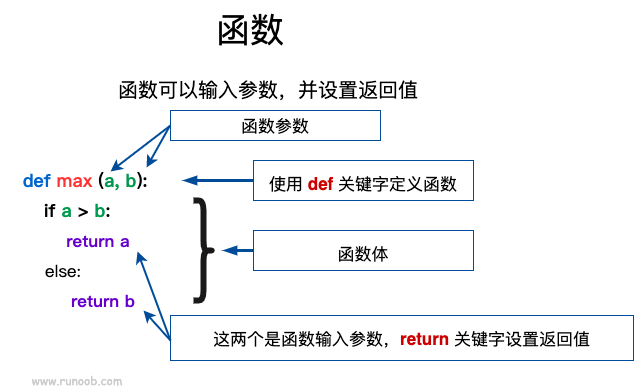
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
语法
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表):
函数体
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
def max(a, b): if a > b: return a else: return b a = 4 b = 5 print(max(a, b))
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=57220 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 5
2、参数传递
1、可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
-
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
-
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
-
不可变类型:类似 C++ 的值传递,如 整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a))内部修改 a 的值,则是新生成来一个 a。
-
可变类型:类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
2、python 传不可变对象实例
通过 id() 函数来查看内存地址变化:
def change(a): print(id(a)) # 指向的是同一个对象 a=10 print(id(a)) # 一个新对象 a=1 print(id(a)) change(a)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=57289 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 140737191977360 140737191977360 140737191977648
3、传可变对象实例
可变对象在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了
# 可写函数说明 def changeme( mylist ): "修改传入的列表" mylist.append([1,2,3,4]) print ("函数内取值: ", mylist) return # 调用changeme函数 mylist = [10,20,30] changeme( mylist ) print ("函数外取值: ", mylist)
传入函数的和在末尾添加新内容的对象用的是同一个引用。故输出结果如下:
函数内取值: [10, 20, 30, [1, 2, 3, 4]]
函数外取值: [10, 20, 30, [1, 2, 3, 4]]
3、参数
以下是调用函数时可使用的正式参数类型:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
1、必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
2、关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
# 可写函数说明 def printinfo(name, age): "打印任何传入的字符串" print("名字: ", name) print("年龄: ", age) return # 调用printinfo函数 printinfo(age=50, name="runoob")
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=49258 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 名字: runoob 年龄: 50
3、默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值:
# 可写函数说明 def printinfo(name, age=35): "打印任何传入的字符串" print("名字: ", name) print("年龄: ", age) return # 调用printinfo函数 printinfo(age=50, name="runoob") print("------------------------") printinfo(name="runoob")
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=49324 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 名字: runoob 年龄: 50 ------------------------ 名字: runoob 年龄: 35
4、不定长参数(加*相当于元组)
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。
注意:加两个星号 ** 的参数会以字典的形式导入;加一个星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数;如果单独出现星号 * 后的参数必须用关键字传入
基本语法如下:
def functionname([formal_args,] *var_args_tuple ): "函数_文档字符串" function_suite return [expression]
加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
def printinfo(a,*b): print(a) print(b) printinfo("abd",1,2,3)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=49396 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') abd (1, 2, 3)
加了两个星号 ** 的参数会以字典的形式导入
def printinfo( arg1, **vardict ): "打印任何传入的参数" print ("输出: ") print (arg1) print (vardict) # 调用printinfo 函数 printinfo(1, a=2,b=3)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=49454 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 输出: 1 {'a': 2, 'b': 3}
如果单独出现星号 * 后的参数必须用关键字传入
def f(a,b,*,c): return a+b+c print(f(1,2,c=12))
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=49568 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 15
5、匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
1、语法
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
# 可写函数说明 sum = lambda arg1, arg2: arg1 + arg2 # 调用sum函数 print ("相加后的值为 : ", sum( 1, 2)) print ("相加后的值为 : ", sum( 2, 5 ))
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=49647 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') 相加后的值为 : 3 相加后的值为 : 7
6、return语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,以下实例演示了 return 语句的用法:
# 可写函数说明 def sum( arg1, arg2 ): # 返回2个参数的和." total = arg1 + arg2 print ("函数内 : ", total) return total # 调用sum函数 total = sum( 10, 20 ) print ("函数外 : ", total)
结果:
函数内 : 30
函数外 : 30
7、强制位置参数
Python3.8 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 或 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f): print(a, b, c, d, e, f)
f(10, 20, 30, d=40, e=50, f=60)
2、Python3 数据结构
1、列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
以下是 Python 中列表的方法:
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
注意:类似 insert, remove 或 sort 等修改列表的方法没有返回值。
1、将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。例如:
a = [66.25, 333, 333, 1, 1234.5] a.append(1) a.append(2) print(a) a.pop() print(a)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=50250 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') [66.25, 333, 333, 1, 1234.5, 1, 2] [66.25, 333, 333, 1, 1234.5, 1]
2、将列表当作队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
from collections import deque a = deque([66.25, 333, 333, 1, 1234.5]) # 进队列 a.append(100) a.append(101) print(a) # 出队列 a.popleft() a.popleft() print(a)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=50380 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') deque([66.25, 333, 333, 1, 1234.5, 100, 101]) deque([333, 1, 1234.5, 100, 101])
3、列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
注意:python的字符串连接是逗号,与java不同(+)
a = [2, 4, 6] a1= [4, 3, -9] b=[3*x for x in a] print("b的值:",b) c=[3*x for x in a if x >3] print("c的值:",c) d=[x*y for x in a for y in a1] print("d的值:",d) e=[x+y for x in a for y in a1] print("e的值:",e) m=[a[i]*a1[i] for i in range(len(a))] print("m的值:",m)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=50988 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') b的值: [6, 12, 18] c的值: [12, 18] d的值: [8, 6, -18, 16, 12, -36, 24, 18, -54] e的值: [6, 5, -7, 8, 7, -5, 10, 9, -3] m的值: [8, 12, -54]
4、嵌套列表解析
实现矩阵
# 以下实例展示了3X4的矩阵列表 matrix = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ] print(matrix)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=51096 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
2、元组和序列
元组由若干逗号分隔的值组成,例如:
t = 12345, 54321, 'hello!' u = t, (1, 2, 3, 4, 5) print(u)
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=51224 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') ((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
如你所见,元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可能有或没有括号, 不过括号通常是必须的(如果元组是更大的表达式的一部分)。
3、集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号({})创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典,集合也支持推导式。
4、字典
另一个非常有用的 Python 内建数据类型是字典。
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}。
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
同时遍历两个或更多的序列,可以使用 zip() 组合:
>>> questions = ['name', 'quest', 'favorite color'] >>> answers = ['lancelot', 'the holy grail', 'blue'] >>> for q, a in zip(questions, answers): ... print('What is your {0}? It is {1}.'.format(q, a)) ... What is your name? It is lancelot. What is your quest? It is the holy grail. What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数:
>>> for i in reversed(range(1, 10, 2)): ... print(i) ... 9 7 5 3 1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana'] >>> for f in sorted(set(basket)): ... print(f) ... apple banana orange pear
3、Python3 模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法
1、import 语句
import module1[, module2[,... moduleN]
2、from … import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]
3、from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
4、__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3 # Filename: using_name.py if __name__ == '__main__': print('程序自身在运行') else: print('我来自另一模块')
说明: 每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
说明:__name__ 与 __main__ 底下是双下划线, _ _ 是这样去掉中间的那个空格。
5、dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
import os print(dir(os))
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=52830 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/test.py', wdir='C:/app/PycharmProjects/tensorflow') ['DirEntry', 'F_OK', 'MutableMapping', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'PathLike', 'R_OK', 'SEEK_CUR', 'SEEK_END', 'SEEK_SET', 'TMP_MAX', 'W_OK', 'X_OK', '_Environ', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_execvpe', '_exists', '_exit', '_fspath', '_get_exports_list', '_putenv', '_unsetenv', '_wrap_close', 'abc', 'abort', 'access', 'altsep', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'curdir', 'defpath', 'device_encoding', 'devnull', 'dup', 'dup2', 'environ', 'error', 'execl', 'execle', 'execlp', 'execlpe', 'execv', 'execve', 'execvp', 'execvpe', 'extsep', 'fdopen', 'fsdecode', 'fsencode', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_exec_path', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getenv', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'linesep', 'link', 'listdir', 'lseek', 'lstat', 'makedirs', 'mkdir', 'name', 'open', 'pardir', 'path', 'pathsep', 'pipe', 'popen', 'putenv', 'read', 'readlink', 'remove', 'removedirs', 'rename', 'renames', 'replace', 'rmdir', 'scandir', 'sep', 'set_handle_inheritable', 'set_inheritable', 'spawnl', 'spawnle', 'spawnv', 'spawnve', 'st', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'supports_bytes_environ', 'supports_dir_fd', 'supports_effective_ids', 'supports_fd', 'supports_follow_symlinks', 'symlink', 'sys', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'walk', 'write']
4、Python3 输入和输出
1、print()
求一个平方与立方的表?
for x in range(1, 11):
print(repr(x).rjust(2), repr(x * x).rjust(3), end=' ')
print(repr(x * x * x).rjust(4))
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=54864 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/Test/__init__.py', wdir='C:/app/PycharmProjects/tensorflow/Test') 1 1 1 2 4 8 3 9 27 4 16 64 5 25 125 6 36 216 7 49 343 8 64 512 9 81 729 10 100 1000
注意:
这个例子展示了字符串对象的 rjust() 方法, 它可以将字符串靠右, 并在左边填充空格。
还有类似的方法, 如 ljust() 和 center()。 这些方法并不会写任何东西, 它们仅仅返回新的字符串。
另一个方法 zfill(), 它会在数字的左边填充 0
2、format
括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
在括号中的数字用于指向传入对象在 format() 中的位置,如下所示:
import math str="Google" str1="Runoob" print("{0}和{1}".format(str,str1)) print("常量 PI 的值近似为 {0:.3f}".format(math.pi))
print('常量 PI 的值近似为:%5.3f。' % math.pi)
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3} for name,num in table.items(): print("{0:10}==>{1:10d}".format(name,num))
结果:
C:Anaconda3python.exe "C:Program FilesJetBrainsPyCharm 2019.1.1helperspydevpydevconsole.py" --mode=client --port=55681 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['C:\app\PycharmProjects', 'C:/app/PycharmProjects']) Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 7.12.0 Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32 runfile('C:/app/PycharmProjects/tensorflow/Test/__init__.py', wdir='C:/app/PycharmProjects/tensorflow/Test') Google和Runoob 常量 PI 的值近似为 3.142 Google ==> 1 Runoob ==> 2 Taobao ==> 3
3、键盘输入
Python提供了 input() 内置函数从标准输入读入一行文本,默认的标准输入是键盘。
input 可以接收一个Python表达式作为输入,并将运算结果返回。
str = input("请输入:"); print ("你输入的内容是: ", str)
结果
请输入:python
你输入的内容是: python
4、文件输入与输出
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
- filename:包含了你要访问的文件名称的字符串值。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:

| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
写入实现:
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
num = f.write( "Python 是一个非常好的语言。 是的,的确非常好!! " )
print(num)
# 关闭打开的文件
f.close()
f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。下面给出一个完整的例子:
>>> f = open('/tmp/foo.txt', 'rb+') >>> f.write(b'0123456789abcdef') 16 >>> f.seek(5) # 移动到文件的第六个字节 5 >>> f.read(1) b'5' >>> f.seek(-3, 2) # 移动到文件的倒数第三字节 13 >>> f.read(1) b'd'
f.close()
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
读取实现:
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回
#!/usr/bin/python3 # 打开一个文件 f = open("/tmp/foo.txt", "r") str = f.read() print(str) # 关闭打开的文件 f.close()
结果:
Python 是一个非常好的语言。
是的,的确非常好!!
f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 ' '。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
#!/usr/bin/python3 # 打开一个文件 f = open("/tmp/foo.txt", "r") str = f.readline() print(str) # 关闭打开的文件 f.close()
f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
#!/usr/bin/python3 # 打开一个文件 f = open("/tmp/foo.txt", "r") str = f.readlines() print(str) # 关闭打开的文件 f.close()
结果:
['Python 是一个非常好的语言。 ', '是的,的确非常好!! ']
另一种方式是迭代一个文件对象然后读取每行:
# 打开一个文件 f = open("/tmp/foo.txt", "r") for line in f: print(line, end='') # 关闭打开的文件 f.close()
结果:
Python 是一个非常好的语言。
是的,的确非常好!!
pickle 模块
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
#!/usr/bin/python3 import pickle # 使用pickle模块将数据对象保存到文件 data1 = {'a': [1, 2.0, 3, 4+6j], 'b': ('string', u'Unicode string'), 'c': None} selfref_list = [1, 2, 3] selfref_list.append(selfref_list) output = open('data.pkl', 'wb') # Pickle dictionary using protocol 0. pickle.dump(data1, output) # Pickle the list using the highest protocol available. pickle.dump(selfref_list, output, -1) output.close()
#!/usr/bin/python3 import pprint, pickle #使用pickle模块从文件中重构python对象 pkl_file = open('data.pkl', 'rb') data1 = pickle.load(pkl_file) pprint.pprint(data1) data2 = pickle.load(pkl_file) pprint.pprint(data2) pkl_file.close()
5、Python3 File(文件) 方法
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 |
关闭文件。关闭后文件不能再进行读写操作。 |
| 2 |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 |
返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 |
如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 |
Python 3 中的 File 对象不支持 next() 方法。 返回文件下一行。 |
| 6 |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 |
读取整行,包括 " " 字符。 |
| 8 |
读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 |
移动文件读取指针到指定位置 |
| 10 |
返回文件当前位置。 |
| 11 |
从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| 12 |
将字符串写入文件,返回的是写入的字符长度。 |
| 13 |
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |