常见分类模型与算法
- 距离判别法,即最近邻算法KNN;
- 贝叶斯分类器;
- 线性判别法,即逻辑回归算法;
- 决策树;
- 支持向量机;
- 神经网络;
1. KNN分类算法原理及应用
1.1 KNN概述
K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法。
KNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断你的类型。
本质上,KNN算法就是用距离来衡量样本之间的相似度。
1.2 算法图示
- 从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别
- 算法涉及3个主要因素
- 1) 训练数据集
- 2) 距离或相似度的计算衡量
- 3) k的大小
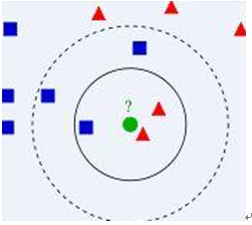
- 算法描述
- 1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中;
- 2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类;
- 3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别;
1.3 算法要点
1.3.1 计算步骤
计算步骤如下:
1) 算距离:给定测试对象,计算它与训练集中的每个对象的距离;
2) 找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻;
3) 做分类:根据这k个近邻归属的主要类别,来对测试对象分类;
1.3.2 相似度的衡量
- 距离越近应该意味着这两个点属于一个分类的可能性越大,但,距离不能代表一切,有些数据的相似度衡量并不适合用距离;
- 相似度衡量方法:包括欧式距离、夹角余弦等。
(简单应用中,一般使用欧式距离,但对于文本分类来说,使用余弦来计算相似度就比欧式距离更合适)
1.3.3 类别的判定
- 简单投票法:少数服从多数,近邻中哪个类别的点最多就分为该类
- 加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
1.4 算法不足之处
1. 样本不平衡容易导致结果错误
- 如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
- 改善方法:对此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
2. 计算量较大
- 因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
- 改善方法:实现对已知样本点进行剪辑,事先去除对分类作用不大的样本。
注:该方法比较适用于样本容量比较大的类域的类域的分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
1.5 KNN分类算法Python实战——KNN简单数据分类实践
1.5.1 需求
计算地理位置的相似度
有以下先验数据,使用KNN算法对未知类别数据分类
|
属性1 |
属性2 |
类别 |
|
1.0 |
0.9 |
A |
|
1.0 |
1.0 |
A |
|
0.1 |
0.2 |
B |
|
0.0 |
0.1 |
B |
未知类别数据
|
属性1 |
属性2 |
类别 |
|
1.2 |
1.0 |
? |
|
0.1 |
0.3 |
? |
1.5.2 Python实现
首先,我们新建一个KNN.py脚本文件,文件里面包含两个函数,一个用来生成小数据集,一个实现KNN分类算法。代码如下:

########################## # KNN: k Nearest Neighbors #输入:newInput: (1xN)的待分类向量 # dataSet: (NxM)的训练数据集 # labels: 训练数据集的类别标签向量 # k: 近邻数 # 输出:可能性最大的分类标签 ########################## from numpy import import operator #创建一个数据集,包含2个类别共4个样本 def createDataSet(): # 生成一个矩阵,每行表示一个样本 group = array([[1.0,0.9],[1.0,1.0],[0.1,0.2],[0.0,0.1]]) # 4个样本分别所属的类别 labels = ['A', 'A', 'B', 'B'] return group, labels # KNN分类算法函数定义 def KNNClassify(newInput, dataSet, labels, k): numSamples = dataSet.shape[0] #shape[0]表示行数 ## step1:计算距离 # tile(A, reps):构造一个矩阵,通过A重复reps次得到 # the following copy numSamples rows for dataSet diff = tile(newInput, (numSamples, 1)) -dataSet #按元素求差值 squareDiff = diff ** 2 #将差值平方 squareDist = sum(squaredDiff, axis = 1) # 按行累加 ##step2:对距离排序 # argsort() 返回排序后的索引值 sortedDistIndices = argsort(distance) classCount = {} # define a dictionary (can be append element) for i in xrange(k): ##step 3: 选择k个最近邻 voteLabel = labels[sortedDistIndices[i]] ## step 4:计算k个最近邻中各类别出现的次数 # when the key voteLabel is not in dictionary classCount,get() # will return 0 classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 ##step 5:返回出现次数最多的类别标签 maxCount = 0 for key, value in classCount.items(): if value > maxCount: maxCount = value maxIndex = key return maxIndex
然后调用算法进行测试
import KNN from numpy import * #生成数据集和类别标签 dataSet,labels = KNN.createDataSet() #定义一个未知类别的数据 testX = array([1.2, 1.0]) k=3 #调用分类函数对未知数据分类 outputLabel = KNN.KNNClassify(testX, dataSet, labels, 3) print "Your input is:", testX, " and classified to class:", outputLabel testX = array([0.1, 0.3]) outputLabel = KNN.KNNClassify(testX,dataSet, labels, 3) print "Your input is:", testX, "and classified to class:", outputLabel
这时候会输出:
Your input is: [1.2 1.0] and classified to class: A Your input is: [0.1 0.3] and classified to class: B
2. 朴素贝叶斯分类算法原理
2.1 概述
贝叶斯分类算法时一大类分类算法的总称。贝叶斯分类算法以样本可能属于某类的概率来作为分类依据。朴素贝叶斯分类算法时贝叶斯分类算法中最简单的一种。
注:朴素的意思时条件概率独立性
2.2 算法思想
朴素贝叶斯的思想是这样的:如果一个事物在一些属性条件发生的情况下,事物属于A的概率>属于B的概率,则判定事物属于A。
通俗来说比如,在某条大街上,有100人,其中有50个美国人,50个非洲人,看到一个讲英语的黑人,那么我们是怎么去判断他来自哪里?
提取特征:
肤色:黑,语言:英语
先验知识:
P(黑色|非洲人) = 0.8
P(讲英语|非洲人)=0.1
P(黑色|美国人)= 0.2
P(讲英语|美国人)=0.9
要判断的概率是:
P(非洲人|(讲英语,黑色) )
P(美国人|(讲英语,黑色) )
思考过程:

P(非洲人|(讲英语,黑色) ) 的 分子= 0.1 * 0.8 *0.5 =0.04
P(美国人|(讲英语,黑色) ) 的 分子= 0.9 *0.2 * 0.5 = 0.09
从而比较这两个概率的大小就等价于比较这两个分子的值,可以得出结论,此人应该是:美国人。
其蕴含的数学原理如下:
p(A|xy)=p(Axy)/p(xy)=p(Axy)/p(x)p(y)=p(A)/p(x)*p(A)/p(y)* p(xy)/p(xy)=p(A|x)p(A|y)
|
朴素贝叶斯分类器 讲了上面的小故事,我们来朴素贝叶斯分类器的表示形式: 当特征为为x时,计算所有类别的条件概率,选取条件概率最大的类别作为待分类的类别。由于上公式的分母对每个类别都是一样的,因此计算时可以不考虑分母,即 朴素贝叶斯的朴素体现在其对各个条件的独立性假设上,加上独立假设后,大大减少了参数假设空间。 |
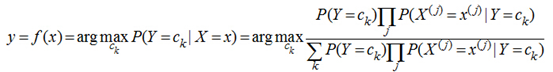

2.3 算法要点
2.3.1 算法步骤
1. 分解各类先验样本数据中的特征;
2. 计算各类数据中,各特征的条件概率;(比如:特征1出现的情况下,属于A类的概率p(A|特征1),属于B类的概率p(B|特征1),属于C类的概率p(C|特征1)......)
3. 分解待分类数据中的特征(特征1、特征2、特征3、特征4......)
4. 计算各特征的各条件概率的乘积,如下所示:
判断为A类的概率:p(A|特征1) * p(A|特征2) * p(A|特征3) * p(A|特征4)......
判断为B类的概率:p(B|特征1) * p(B|特征2) * p(B|特征3) * p(B|特征4)......
判断为C类的概率:p(C|特征1) * p(C|特征2) * p(C|特征3) * p(C|特征4)......
......
5. 结果中的最大值就是该样本所属的类别
2.3.2 算法应用举例
大众点评、淘宝等电商上都会有大量的用户评论,比如:
|
1、衣服质量太差了!!!!颜色根本不纯!!! 2、我有一有种上当受骗的感觉!!!! 3、质量太差,衣服拿到手感觉像旧货!!! 4、上身漂亮,合身,很帅,给卖家点赞 5、穿上衣服帅呆了,给点一万个赞 6、我在他家买了三件衣服!!!!质量都很差! |
0 0 0 1 1 0 |
其中1/2/3/6是差评,4/5是好评
现在需要使用朴素贝叶斯分类算法来自动分类其他的评论,比如:
|
a、这么差的衣服以后再也不买了 b、帅,有逼格 …… |
2.3.3 算法应用流程
1. 分解出先验数据中的各特征
(即分词,比如“衣服”,“质量太差”,“差”,“不纯”,“帅”,“漂亮”,“赞” ......)
2. 计算各类别(好评、差评)中,各特征的条件概率
(比如 p(“衣服” | 差评)、p(“衣服” | 好评)、p(“差”|好评)、p(“差”| 差评) ......)
3. 计算类别概率
p(好评|(c1,c2,c5,c8))的分子=p(c1|好评) * p(c2|好评) * p(c3|好评) *......p(好评)
p(差评|(c1,c2,c5,c8))的分子=p(c1|差评) * p(c2|差评) * p(c3|差评) *......p(差评)

4. 显然p(差评)的结果值更大,因此a被判别为"差评"
2.4 朴素贝叶斯分类算法案例
2.4.1 需求
利用大量邮件先验数据,使用朴素贝叶斯分类算法来自动识别垃圾邮件
2.4.2 python实现
#过滤垃圾邮件 def textParse(bigString): #正则表达式进行文本解析 import re listOfTokens = re.split(r'W*', bigString) return [tok.lower() for tok in listOfTokens if len(tok) > 2] def spamTest() docList = []; classList = []; fullText = [] for i in range(1,26): #导入并解析文本文件 wordList = textParse(open('email/spam/%d.txt'%i).read()) docList.append(wordList) fullText.extend(wordList) classList.append(1) wordList = textParse(open('email/ham/%d.txt'%i).read()) docList.append(wordList) fullText.extend(wordList) classList.append(0) vocabList = createVocabList(docList) trainingSet = range(50);testSet = [] for i in range(10): #随机构建训练集 randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) #随机挑选一个文档索引号放入测试集 del(trainingSet[randIndex]) #将该文档索引号从训练集中剔除 trainMat = []; trainClasses = [] for docIndex in trainingSet: trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V,p1V,pSpam = trainNBO(array(trainMat), array(trainClasses)) errorCount = 0 for docIndex in testSet: #对测试集进行分类 wordVector = setOfWords2Vec(vocabList, docList[docIndex]) if classifyNB(array(wordVector), p0V,p1V != classList[docIndex]: errorCount +=1 print 'the error rate is:', float(errorCount)/len(testSet)
3. logistic逻辑回归分类算法及应用
3.1 概述
Lineage逻辑回归是一种简单而又效果不错的分类算法。
什么是回归:比如说我们有两类数据,各有50个点组成,当我们把这些点画出来,会有一条线区分这两组数据,我们拟合出这个曲线(因为很有可能是非线性的),就是回归。我们通过大量的数据找出这条线,并拟合出这条线的表达式,再有新数据,我们就以这条线为区分来实现分类。
下图是一个数据集的两组数据,中间有一条区分两组数据的线。
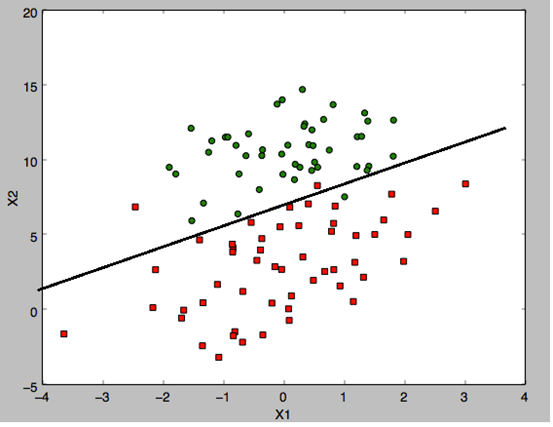
显然,只有这种线性可分的数据分布才适合用线性逻辑回归
3.2 算法思想
Lineage回归分类算法就是将线性回归应用在分类场景中
在该场景中,计算结果是要得到对样本数据的分类标签,而不是得到那条回归直线
3.2.1 算法图示
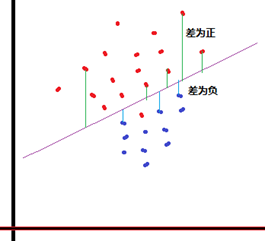
1) 算法目标()?
大白话:计算各点的y值到拟合线的垂直距离,如果距离>0,分为类A;距离<0,分为类B。
2) 如何得到拟合线呢?
大白话:只能先假设,因为线或面的函数都可以表达成y(拟合)=w1 * x1 + w2 * x2 + w3 * x3 + ... ,其中的w是待定参数,而x是数据的各维度特征值,因而上述问题就变成了样本y(x) - y(拟合) > 0? A:B
3) 如何求解出一套最优的w参数呢?
基本思路:代入”先验数据“来逆推求解,但针对不等式求解参数极其困难,通用的解决方法,将对不等式的求解做一个转换:a.将”样本y(x) - y(拟合)“的差值压缩到一个0~1的小区间;b.然后代入大量的样本特征值,从而得到一系列的输出结果;c.再将这些输出结果跟样本的先验类别比较,并根据比较情况来调整拟合线的参数值,从而是拟合线的参数逼近最优。从而将问题转化为逼近求解的典型数学问题。
3.2.2 sigmoid函数
上述算法思路中,通常使用sigmoid函数作为转换函数
- 函数表达式:
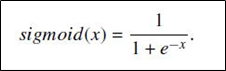 ,注:此处的x是向量
,注:此处的x是向量
- 函数曲线:
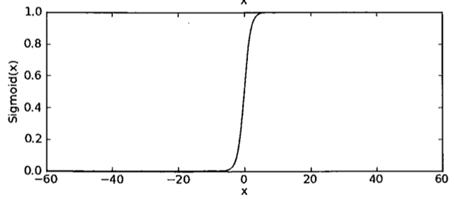
之所以使用sigmoid函数,就是让样板点经过运算后得到的结果限制在0~1之间,压缩数据的巨幅震荡,从而方便得到样本点的分类标签(分类以sigmoid函数的计算结果是否大于0.5为依据)
3.3 算法实现分析
1.3.1 实现思路
- 算法思想的数学表述
把数据集的特征值设为x1,x2,x3......,求出它们的回归系数wj,设z=w1 * x1 + w2 * x2......,然后将z值代入sigmoid函数并判断结果,即可得到分类标签
问题在于如何得到一组合适的参数wj?
通过解析的途径很难求解,而通过迭代的方法可以比较便捷地找到最优解。简单来说,就是不断用样本特征值代入算式,计算出结果后跟其实际标签进行比较,根据差值来修正参数,然后再代入新的样本值计算,循环往复,直到无需修正或已到达预设的迭代次数。
注:此过程用梯度上升来实现。
1.3.2 梯度上升算法
梯度上升是指找到函数增长的方向。在具体实现的过程中,不停地迭代运算直到w的值几乎不再变化为止。
如图所示:

3.4 Lineage逻辑回归分类Python实战
3.4.1 需求
对给定的先验数据集,使用logistic回归算法对新数据分类
3.4.2 python实现
3.4.2.1 定义sigmoid函数
def loadDataSet(): dataMat = []; labelMat = [] fr = open('d:/testSet.txt') for line in fr.readlines(): lineArr = line.strip().split() dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) labelMat.append(int(lineArr[2])) return dataMat, labelMat def sigmoid(inX): return 1.0/(1+exp(-inX))
3.4.2.2 返回回归系数
对应于每个特征值,for循环实现了递归梯度上升算法。
def gradAscent(dataMatln, classLabels): dataMatrix = mat(dataMatln) # 将先验数据集转换为NumPy矩阵 labelMat = mat(classLabels).transpose() #将先验数据的类标签转换为NumPy矩阵 m,n = shape(dataMatrix) alpha = 0.001 #设置逼近步长调整系数 maxCycles = 500 #设置最大迭代次数为500 weights = ones((n,1)) #weights即为需要迭代求解的参数向量 for k in range(maxCycles): #heavy on matrix operations h = sigmoid(dataMatrix * weights) #代入样本向量求得“样本y” sigmoid转换值 error = (labelMat - h) #求差 weights = weights + alpha * dataMatrix.transpose() * error #根据差值调整参数向量 return weights
我们的数据集有两个特征值分别是x1,x2。在代码中又增设了x0变量。
结果,返回了特征值的回归系数:
[[4.12414349]
[0.48007329]
[-0.6168482]]
我们得出x1和x2的关系(设x0 = 1),0=4.12414349+0.48007329*x1 - 0.6168482*x2
3.4.2.3 线性拟合线
画出x1与x2的关系图——线性拟合线

4.决策树(Decision Tree)分类算法原理及应用
4.1 概述
决策树——是一种被广泛使用的分类算法。相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置。在实际应用中,对于探测式的知识发现,决策树更加适用。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
4.2 算法思想
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员吗?
母亲:是,公务员,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。实质:通过年龄、长相、收入和是否公务员将男人分为两个类别:见和不见
假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑。
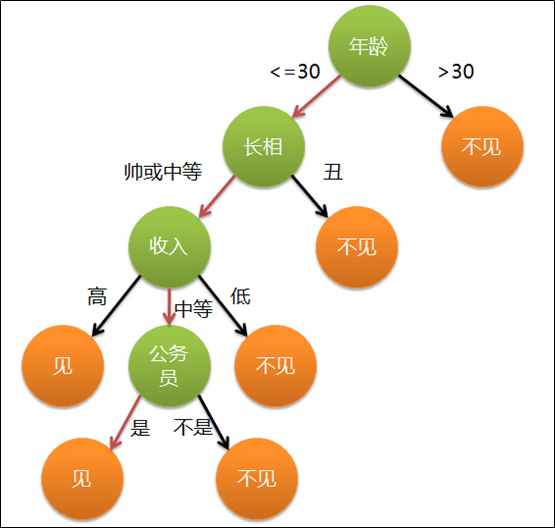
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中:
- 绿色节点表示判断条件
- 橙色节点表示决策结果
- 箭头表示在一个判断条件在不同情况下的决策路径
图中红色箭头表示了上面例子中女孩的决策过程。这幅图基本可以算是一颗决策树,说它”基本可以算“是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
决策树分类算法的关键就是根据”先验数据“构造一棵最佳的决策树,用以预测未知数据的类别
决策树:是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
4.3 决策树构造
4.3.1 决策树构造样例
假如有以下判断苹果好坏的数据样本:
|
样本 红 大 好苹果 0 1 1 1 1 1 0 1 2 0 1 0 3 0 0 0 |
样本中有2个属性,A0表示是否红苹果。A1表示是否大于苹果。假如要根据这个数据样本构建一棵自动判断苹果好坏的决策树。由于本例中的数据只有2个属性,因此,我们可以穷举所有可能构造出来的决策树,就2课树,如下图所示:
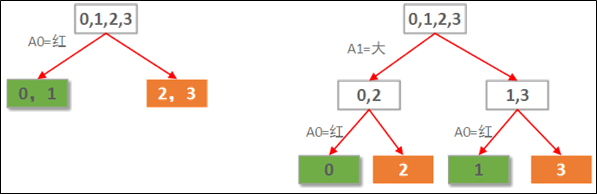
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。当然这是直觉的认知。而直觉显然不适合转化成程序的实现,所以需要有一种定量的考察来评价这两棵树的性能好坏。
决策树的评价所用的定量考察方法为计算每种划分情况的信息熵增益:如果经过某个选定的属性进行数据划分后的信息熵下降最多,则这个划分属性是最优选择。
4.3.2 属性划分选择(即构造决策树)的依据
熵:信息论的奠基人香农定义的用来信息量的单位。简单来说,熵就是“无序,混乱”的程度。
公式:H(X)=- Σ pi * logpi, i=1,2, ... , n,pi为一个特征的概率
通过计算来理解:
1、原始样本数据的熵:
样例总数:4
好苹果:2
坏苹果:2
熵:-(1/2 * log(1/2) + 1/2 * log(1/2)) =1
信息熵为1表示当前处于最混乱,最无序的状态
2、两颗决策树的划分结果熵增益计算
- 树1先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) =0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) =0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1 * 2/4 + e2 * 2/4 = 0。
选择A0做划分的信息熵增益G(S,A0) = S - E = 1 - 0 =1。
事实上,决策树叶子节点表示已经都属于相同类别,因此信息熵一定为0。
- 树2先选A1作划分,各子节点信息熵计算如下:
0,2子节点有1个正例,1个负例。信息熵为:e1 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
1,3子节点有1个正例,1个负例。信息熵为:e2 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
因此选择A1划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1 * 2/4 + e2 * 2/4 = 1。也就是说分了跟没分一样!
选择A1做划分的信息熵增益G(S,A1) = S - E = 1 - 1 = 0。
因此,每次划分之前,我们只需要计算出信息熵增益最大的那种划分即可。
4.4 算法要点
4.4.1 指导思想
经过决策属性的划分后,数据的无序度越来越低,也就是信息熵越来越小
4.4.2 算法实现
梳理出数据中的属性,比较按照某特定属性划分后的数据的信息熵增益,选择信息熵增益最大的那个属性作为第一划分依据,然后继续选择第二属性,以此类推。
4.5 决策树分类算法Python实战
4.5.1 案例需求
我们的任务就是训练一个决策树分类器,输入身高和体重,分类器能给出这个人是胖子还是瘦子。
所用的训练数据如下,这个数据一共有8个样本,每个样本有2个属性,分别为头发和声音,第三列为性别标签,表示“男”或“女”。该数据保存在1.txt中。
| 头发 | 声音 | 性别 |
| 长 | 粗 | 男 |
| 短 | 粗 | 男 |
| 短 | 粗 | 男 |
| 长 | 细 | 女 |
| 短 | 细 | 女 |
| 短 | 粗 | 女 |
| 长 | 粗 | 女 |
| 长 | 粗 | 女 |
4.5.2 模型分析
决策树对于“是非”的二值逻辑的分枝相当自然。
本例决策树的任务是找到头发、声音将其样本两两分类,自顶向下构建决策树。
在这里,我们列出两种方案:
①先根据头发判断,若判断不出,再根据声音判断,于是画了一幅图,如下:

于是,一个简单、直观的决策树就这么出来了。头发长、声音粗就是男生;头发长、声音细就是女生;头发短、声音粗是男生;头发短、声音细是女生。
② 先根据声音判断,然后再根据头发来判断,决策树如下:
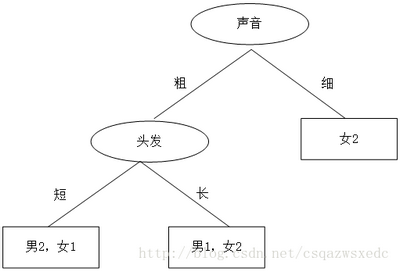
那么问题来了:方案①和方案②哪个的决策树好些?计算机做决策树的时候,面对多个特征,该如何选哪个特征为最佳多得划分特征?
划分数据集的大原则是:将无序的数据变得更加有序。
我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。于是我们这么想,如果我们能测量数据的复杂度,对比按不同特征分类后的数据复杂度,若按某一特征分类后复杂度减少的更多,那么这个特征即为最佳分类特征。为此,Claude Shannon定义了熵和信息增益,用熵来表示信息的复杂度,熵越大,则信息越复杂。信息增益表示两个信息熵的差值。
首先计算未分类前的熵,总共有8位同学,男生3位,女生5位
熵(总)= -3/8*log2(3/8)-5/8*log2(5/8)=0.9544
接着分别计算方案①和方案②分类后信息熵。
方案①首先按头发分类,分类后的结果为:长头发中有1男3女。短头发中有2男2女。
熵(长发)= -1/4*log2(1/4)-3/4*log2(3/4)=0.8113
熵(短发)= -2/4*log2(2/4)-2/4*log2(2/4)=1
熵(方案①)= 4/8*0.8113+4/8*1=0.9057 (4/8为长头发有4人,短头发有4人)
信息增益(方案①)= 熵(总)- 熵(方案①)= 0.9544 - 0.9057 = 0.0487
同理,按方案②的方法,首先按声音特征来分,分类后的结果为:声音粗中有3男3女。声音细中有0男2女。
熵(声音粗)= -3/6*log2(3/6)-3/6*log2(3/6)=1
熵(声音细)= -2/2*log2(2/2)=0
熵(方案②)= 6/8*1+2/8*0=0.75 (6/8为声音粗有6人,2/8为声音细有2人)
信息增益(方案②)= 熵(总)- 熵(方案②)= 0.9544 - 0.75 = 0.2087
按照方案②的方法,先按声音特征分类,信息增益更大,区分样本的能力更强,更具有代表性。
以上就是决策树ID3算法的核心思想。
4.5.3 python实现ID3算法
from math import log import operator def calcShannonEnt(dataSet): # 计算数据的熵(entropy) numEntries=len(dataSet) # 数据条数 labelCounts={} for featVec in dataSet: currentLabel=featVec[-1] # 每行数据的最后一个字(类别) if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 # 统计有多少个类以及每个类的数量 shannonEnt=0 for key in labelCounts: prob=float(labelCounts[key])/numEntries # 计算单个类的熵值 shannonEnt-=prob*log(prob,2) # 累加每个类的熵值 return shannonEnt def createDataSet1(): # 创造示例数据 dataSet = [['长', '粗', '男'], ['短', '粗', '男'], ['短', '粗', '男'], ['长', '细', '女'], ['短', '细', '女'], ['短', '粗', '女'], ['长', '粗', '女'], ['长', '粗', '女']] labels = ['头发', '声音'] # 两个特征 return dataSet, labels def splitDataSet(dataSet, axis, value): # 按某个特征分类后的数据 retDataSet = [] for featVec in dataSet: if featVec[axis] == value: reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet def chooseBestFeatureToSplit(dataSet): # 选择最优的分类特征 numFeatures = len(dataSet[0]) - 1 print(numFeatures) baseEntropy = calcShannonEnt(dataSet) # 原始的熵 bestInfoGain = 0 bestFeature = -1 for i in range(numFeatures): featList = [example[i] for example in dataSet] uniqueVals = set(featList) newEntropy = 0 for value in uniqueVals: subDataSet = splitDataSet(dataSet, i, value) prob = len(subDataSet) / float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) # 按特征分类后的熵 infoGain = baseEntropy - newEntropy # 原始熵与按特征分类后的熵的差值 if (infoGain > bestInfoGain): # 若按某特征划分后,熵值减少的最大,则次特征为最优分类特征 bestInfoGain = infoGain bestFeature = i return bestFeature def majorityCnt(classList): # 按分类后类别数量排序,比如:最后分类为2男1女,则判定为男: classCount={} for vote in classList: if vote not in classCount.keys(): classCount[vote]=0 classCount[vote]+=1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] def createTree(dataSet, labels): classList = [example[-1] for example in dataSet] # 类别:男或女 if classList.count(classList[0]) == len(classList): return classList[0] if len(dataSet[0]) == 1: return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet) # 选择最优特征 bestFeatLabel = labels[bestFeat] myTree = {bestFeatLabel:{}} # 分类结果以字典形式保存 del(labels[bestFeat]) featValues = [example[bestFeat] for example in dataSet] #print(featValues) uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:] myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) return myTree if __name__ == '__main__': dataSet, labels = createDataSet1() # 创造示例数据 print(createTree(dataSet, labels)) # 输出决策树模型结果
这时候会输出
{'声音': {'细': '女', '粗': {'头发': {'长': '女', '短': '男'}}}}
4.5.4 决策树的保存
一棵决策树的学习训练是非常耗费运算时间的,因此,决策树训练出来后,可进行保存,以便在预测新的数据时只需要直接加载训练好的决策树即可
本案例的代码中已经把决策树的结构写入了tree.dot中。打开该文件,很容易画出决策树,还可以看到决策树的更多分类信息。
本例的tree.dot如下所示:
digraph Tree { 0 [label="X[1] <= 55.0000 entropy = 0.954434002925 samples = 8", shape="box"] ; 1 [label="entropy = 0.0000 samples = 2 value = [ 2. 0.]", shape="box"] ; 0 -> 1 ; 2 [label="X[1] <= 70.0000 entropy = 0.650022421648 samples = 6", shape="box"] ; 0 -> 2 ; 3 [label="X[0] <= 1.6500 entropy = 0.918295834054 samples = 3", shape="box"] ; 2 -> 3 ; 4 [label="entropy = 0.0000 samples = 2 value = [ 0. 2.]", shape="box"] ; 3 -> 4 ; 5 [label="entropy = 0.0000 samples = 1 value = [ 1. 0.]", shape="box"] ; 3 -> 5 ; 6 [label="entropy = 0.0000 samples = 3 value = [ 0. 3.]", shape="box"] ; 2 -> 6 ; }
根据这个信息,决策树应该长的如下这个样子:

参考资料:
https://blog.csdn.net/csqazwsxedc/article/details/65697652

