26.1 用户行为数仓业务总结
26.1.1 数仓分几层?每层做什么的?
1)ODS层(原始数据层)
存储原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
2)DWD层(明细层)
对ODS层数据进行清洗(去除空值、脏数据,超过极限范围的数据)
3)DWS层(服务数据层)
以DWD层为基础,进行轻度汇总。比如:用户当日、设备当日、商品当日。
4)ADS层(数据应用层)
26.1.2 Tez引擎优点?
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
26.1.3 在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题?
自定义过。 用UDF函数解析公共字段;用UDTF函数解析事件字段。
26.1.4 如何分析用户活跃?
在启动日志中统计不同设备id 出现次数。
26.1.5 如何分析用户新增?
用活跃用户表 left join 用户新增表,用户新增表中mid为空的即为用户新增。
26.1.6 如何分析用户1天留存?
留存用户=前一天新增 join 今天活跃 用户留存率=留存用户/前一天新增
26.1.7 如何分析沉默用户?
按照设备id对日活表分组,登录次数为1,且是在一周前登录。
26.1.8 如何分析本周回流用户?
本周活跃left join本周新增 left join上周活跃,且本周新增id和上周活跃id都为null
26.1.9 如何分析流失用户?
按照设备id对日活表分组,且七天内没有登录过。
26.1.10 如何分析最近连续3周活跃用户数?
按照设备id对周活进行分组,统计次数等于3次。
26.1.11 如何分析最近七天内连续三天活跃用户数?
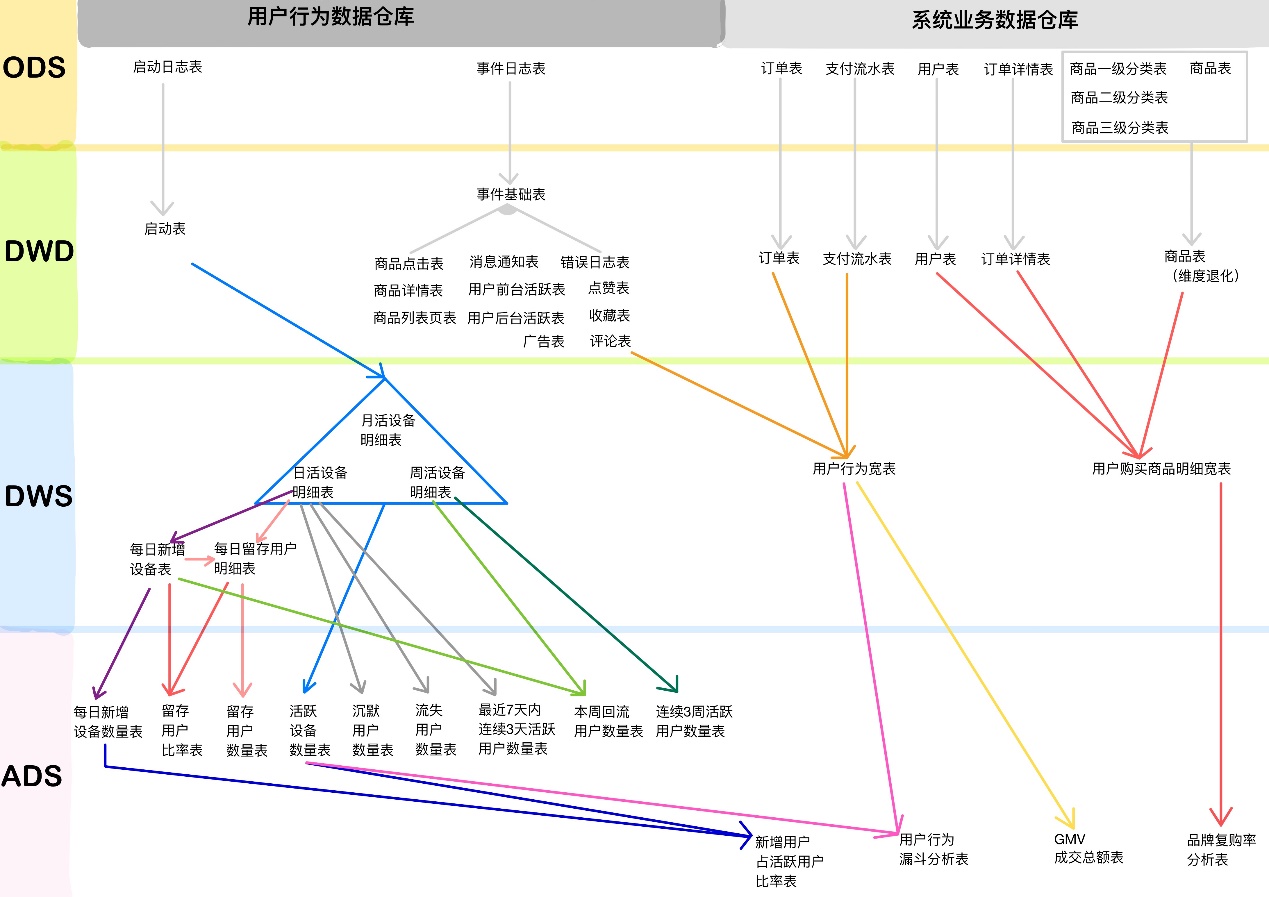
1)查询出最近7天的活跃用户,并对用户活跃日期进行排名 2)计算用户活跃日期及排名之间的差值 3)对同用户及差值分组,统计差值个数 4)将差值相同个数大于等于3的数据取出,然后去重,即为连续3天及以上活跃的用户 21.1.12 整个文档中涉及的所有层级及表
26.2 Hive总结
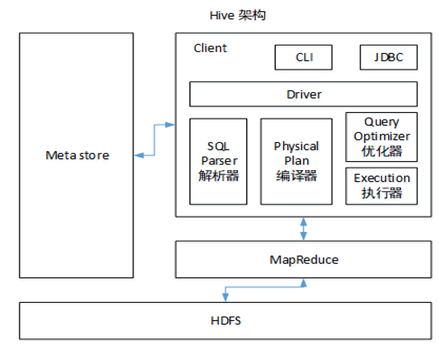
26.2.1 Hive的架构
26.2.2 Hive和数据库比较
Hive 和数据库除了拥有类似的查询语言,再无类似之处。
1)数据存储位置
Hive 存储在 HDFS 。数据库将数据保存在块设备或者本地文件系统中。
2)数据更新
Hive中不建议对数据的改写。而数据库中的数据通常是需要经常进行修改的,
3)执行延迟
Hive 执行延迟较高。数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
4)数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
26.2.3 内部表和外部表
1)管理表:当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。 2)外部表:删除该表并不会删除掉原始数据,删除的是表的元数据 21.2.4 4个By区别 1)Sort By:分区内有序; 2)Order By:全局排序,只有一个Reducer; 3)Distrbute By:类似MR中Partition,进行分区,结合sort by使用。 4) Cluster By:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
26.2.5 窗口函数
1)窗口函数: (1) OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。常用partition by 分区order by排序。 (2)CURRENT ROW:当前行 (3)n PRECEDING:往前n行数据 (4) n FOLLOWING:往后n行数据 (5)UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点 (6) LAG(col,n):往前第n行数据 (7)LEAD(col,n):往后第n行数据 (8) NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。 2)排序函数: (1)RANK() 排序相同时会重复,总数不会变 (2)DENSE_RANK() 排序相同时会重复,总数会减少 (3)ROW_NUMBER() 会根据顺序计算
26.2.6 在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题?
1)自定义过。 2)用UDF函数解析公共字段;用UDTF函数解析事件字段。 3)自定义UDF步骤:定义一个类继承UDF,重写evaluate方法 4)自定义UDTF步骤:定义一个类继承GenericUDTF,重写初始化方法、关闭方法和process方法。
26.2.7 Hive优化
1)MapJoin 如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
2)行列过滤 列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。 行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。 3)采用分桶技术
4)采用分区技术 5)合理设置Map数 (1)通常情况下,作业会通过input的目录产生一个或者多个map任务。 主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。 (2)是不是map数越多越好? 答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。 (3)是不是保证每个map处理接近128m的文件块,就高枕无忧了? 答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。 针对上面的问题2和3,我们需要采取两种方式来解决:即减少map数和增加map数; 6)小文件进行合并 在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
7)合理设置Reduce数 Reduce个数并不是越多越好 (1)过多的启动和初始化Reduce也会消耗时间和资源; (2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题; 在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适;
8)常用参数 // 输出合并小文件
SET hive.merge.mapfiles = true; -- 默认true,在map-only任务结束时合并小文件
SET hive.merge.mapredfiles = true; -- 默认false,在map-reduce任务结束时合并小文件
SET hive.merge.size.per.task = 268435456; -- 默认256M
SET hive.merge.smallfiles.avgsize = 16777216; -- 当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge