上一节讲到人脸检测,现在讲一下人脸识别。具体是通过程序采集图像并进行训练,并且基于这些训练的图像对人脸进行动态识别。
人脸识别前所需要的人脸库可以通过两种方式获得:1.自己从视频获取图像 2.从人脸数据库免费获得可用人脸图像,如ORL人脸库(包含40个人每人10张人脸,总共400张人脸),ORL人脸库中的每一张图像大小为92x112。若要对这些样本进行人脸识别必须要在包含人脸的样本图像上进行人脸识别。这里提供自己准备图像识别出自己的方法。
1.采集人脸信息:通过摄像头采集人脸信息,10张以上即可,把图像大小调整为92x112,保存在一个指定的文件夹,文件名后缀为.png

def generator(data): ''' 打开摄像头,读取帧,检测该帧图像中的人脸,并进行剪切、缩放 生成图片满足以下格式: 1.灰度图,后缀为 .png 2.图像大小相同 params: data:指定生成的人脸数据的保存路径 '''name</span>=input(<span style="color: #800000;">'</span><span style="color: #800000;">my name:</span><span style="color: #800000;">'</span><span style="color: #000000;">) </span><span style="color: #008000;">#</span><span style="color: #008000;">如果路径存在则删除路径</span> path=<span style="color: #000000;">os.path.join(data,name) </span><span style="color: #0000ff;">if</span><span style="color: #000000;"> os.path.isdir(path): shutil.rmtree(path) </span><span style="color: #008000;">#</span><span style="color: #008000;">创建文件夹</span>os.mkdir(path)
#创建一个级联分类器
face_casecade=cv2.CascadeClassifier('../haarcascades/haarcascade_frontalface_default.xml')
#打开摄像头
camera=cv2.VideoCapture(0)
cv2.namedWindow('Dynamic')
#计数
count=1<span style="color: #0000ff;">while</span><span style="color: #000000;">(True): </span><span style="color: #008000;">#</span><span style="color: #008000;">读取一帧图像</span> ret,frame=<span style="color: #000000;">camera.read() </span><span style="color: #0000ff;">if</span><span style="color: #000000;"> ret: </span><span style="color: #008000;">#</span><span style="color: #008000;">转换为灰度图</span> gray_img=<span style="color: #000000;">cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) </span><span style="color: #008000;">#</span><span style="color: #008000;">人脸检测</span> face=face_casecade.detectMultiScale(gray_img,1.3,5<span style="color: #000000;">) </span><span style="color: #0000ff;">for</span> (x,y,w,h) <span style="color: #0000ff;">in</span><span style="color: #000000;"> face: </span><span style="color: #008000;">#</span><span style="color: #008000;">在原图上绘制矩形</span> cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),2<span style="color: #000000;">) </span><span style="color: #008000;">#</span><span style="color: #008000;">调整图像大小</span> new_frame=cv2.resize(frame[y:y+h,x:x+w],(92,112<span style="color: #000000;">)) </span><span style="color: #008000;">#</span><span style="color: #008000;">保存人脸</span> cv2.imwrite(<span style="color: #800000;">'</span><span style="color: #800000;">%s/%s.png</span><span style="color: #800000;">'</span>%<span style="color: #000000;">(path,str(count)),new_frame) count</span>+=1<span style="color: #000000;"> cv2.imshow(</span><span style="color: #800000;">'</span><span style="color: #800000;">Dynamic</span><span style="color: #800000;">'</span><span style="color: #000000;">,frame) </span><span style="color: #008000;">#</span><span style="color: #008000;">按下q键退出</span> <span style="color: #0000ff;">if</span> cv2.waitKey(100) & 0xff==ord(<span style="color: #800000;">'</span><span style="color: #800000;">q</span><span style="color: #800000;">'</span><span style="color: #000000;">): </span><span style="color: #0000ff;">break</span><span style="color: #000000;"> camera.release() cv2.destroyAllWindows()</span></pre>
该程序运行后会在指定的data路径下创建一个你输入的人名的文件夹用于存放采集到的图像,在这里我输入了wjy,结果如图

2.人脸识别
OpenCV有3中人脸识别方法,分别基于三个不同算法,分别为Eigenfaces,Fisherfaces和Local Binary Pattern Histogram
这些方法都有类似的一个过程,即先对数据集进行训练,对图像或视频中的人脸进行分析,并且从两个方面确定:1.是否识别到对应的目标,2.识别到的目标的置信度,在实际中通过阈值进行筛选,置信度高于阈值的人脸将被丢弃
这里介绍一下利用特征脸即Eigenfaces进行人脸识别算法,特征脸法本质上就是PCA降维,基本思路是先把图像灰度化,转化为单通道,再将它首位相接转换为列向量,假设图像的大小是20*20的,那么这个向量就是400维,但是维度太高算法复杂度也会升高,所以需要降维,再使用简单排序即可
#载入图像 读取ORL人脸数据库,准备训练数据 def LoadImages(data): ''' 加载图片数据用于训练 params: data:训练数据所在的目录,要求图片尺寸一样 ret: images:[m,height,width] m为样本数,height为高,width为宽 names:名字的集合 labels:标签 ''' images=[] names=[] labels=[]label</span>=<span style="color: #000000;">0 </span><span style="color: #008000;">#</span><span style="color: #008000;">遍历所有文件夹</span> <span style="color: #0000ff;">for</span> subdir <span style="color: #0000ff;">in</span><span style="color: #000000;"> os.listdir(data): subpath</span>=<span style="color: #000000;">os.path.join(data,subdir) </span><span style="color: #008000;">#</span><span style="color: #008000;">print('path',subpath)</span> <span style="color: #008000;">#</span><span style="color: #008000;">判断文件夹是否存在</span> <span style="color: #0000ff;">if</span><span style="color: #000000;"> os.path.isdir(subpath): </span><span style="color: #008000;">#</span><span style="color: #008000;">在每一个文件夹中存放着一个人的许多照片</span>names.append(subdir)
#遍历文件夹中的图片文件
for filename in os.listdir(subpath):
imgpath=os.path.join(subpath,filename)
img=cv2.imread(imgpath,cv2.IMREAD_COLOR)
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#cv2.imshow('1',img)
#cv2.waitKey(0)
images.append(gray_img)
labels.append(label)
label+=1
images=np.asarray(images)
#names=np.asarray(names)
labels=np.asarray(labels)
return images,labels,names#检验训练结果
def FaceRec(data):
#加载训练的数据
X,y,names=LoadImages(data)
#print('x',X)
model=cv2.face.EigenFaceRecognizer_create()
model.train(X,y)</span><span style="color: #008000;">#</span><span style="color: #008000;">打开摄像头</span> camera=<span style="color: #000000;">cv2.VideoCapture(0) cv2.namedWindow(</span><span style="color: #800000;">'</span><span style="color: #800000;">Dynamic</span><span style="color: #800000;">'</span><span style="color: #000000;">) </span><span style="color: #008000;">#</span><span style="color: #008000;">创建级联分类器</span> face_casecade=cv2.CascadeClassifier(<span style="color: #800000;">'</span><span style="color: #800000;">../haarcascades/haarcascade_frontalface_default.xml</span><span style="color: #800000;">'</span><span style="color: #000000;">) </span><span style="color: #0000ff;">while</span><span style="color: #000000;">(True): </span><span style="color: #008000;">#</span><span style="color: #008000;">读取一帧图像</span> <span style="color: #008000;">#</span><span style="color: #008000;">ret:图像是否读取成功</span> <span style="color: #008000;">#</span><span style="color: #008000;">frame:该帧图像</span> ret,frame=<span style="color: #000000;">camera.read() </span><span style="color: #008000;">#</span><span style="color: #008000;">判断图像是否读取成功</span> <span style="color: #008000;">#</span><span style="color: #008000;">print('ret',ret)</span> <span style="color: #0000ff;">if</span><span style="color: #000000;"> ret: </span><span style="color: #008000;">#</span><span style="color: #008000;">转换为灰度图</span> gray_img=<span style="color: #000000;">cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) </span><span style="color: #008000;">#</span><span style="color: #008000;">利用级联分类器鉴别人脸</span> faces=face_casecade.detectMultiScale(gray_img,1.3,5<span style="color: #000000;">) </span><span style="color: #008000;">#</span><span style="color: #008000;">遍历每一帧图像,画出矩形</span> <span style="color: #0000ff;">for</span> (x,y,w,h) <span style="color: #0000ff;">in</span><span style="color: #000000;"> faces: frame</span>=cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2) <span style="color: #008000;">#</span><span style="color: #008000;">蓝色</span> roi_gray=gray_img[y:y+h,x:x+<span style="color: #000000;">w] </span><span style="color: #0000ff;">try</span><span style="color: #000000;">: </span><span style="color: #008000;">#</span><span style="color: #008000;">将图像转换为宽92 高112的图像</span> <span style="color: #008000;">#</span><span style="color: #008000;">resize(原图像,目标大小,(插值方法)interpolation=,)</span> roi_gray=cv2.resize(roi_gray,(92,112),interpolation=<span style="color: #000000;">cv2.INTER_LINEAR) params</span>=<span style="color: #000000;">model.predict(roi_gray) </span><span style="color: #0000ff;">print</span>(<span style="color: #800000;">'</span><span style="color: #800000;">Label:%s,confidence:%.2f</span><span style="color: #800000;">'</span>%(params[0],params[1<span style="color: #000000;">])) </span><span style="color: #800000;">'''</span><span style="color: #800000;"> putText:给照片添加文字 putText(输入图像,'所需添加的文字',左上角的坐标,字体,字体大小,颜色,字体粗细) </span><span style="color: #800000;">'''</span><span style="color: #000000;"> cv2.putText(frame,names[params[0]],(x,y</span>-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2<span style="color: #000000;">) </span><span style="color: #0000ff;">except</span><span style="color: #000000;">: </span><span style="color: #0000ff;">continue</span><span style="color: #000000;"> cv2.imshow(</span><span style="color: #800000;">'</span><span style="color: #800000;">Dynamic</span><span style="color: #800000;">'</span><span style="color: #000000;">,frame) </span><span style="color: #008000;">#</span><span style="color: #008000;">按下q键退出</span> <span style="color: #0000ff;">if</span> cv2.waitKey(100) & 0xff==ord(<span style="color: #800000;">'</span><span style="color: #800000;">q</span><span style="color: #800000;">'</span><span style="color: #000000;">): </span><span style="color: #0000ff;">break</span><span style="color: #000000;"> camera.release() cv2.destroyAllWindows()</span></pre>
在程序中,我们用cv2.face.EigenFaceRecognizer_create()创建人脸识别的模型,通过图像数组和对应标签数组来训练模型,该函数有两个重要的参数,1.保留主成分的数目,2.指定的置信度阈值,为一个浮点型。
下面就是基本重复人脸检测的相关操作,通过检测到视频中的人脸进行人脸识别,有如下两个步骤:
1.将检测到的人脸图像调整为92x112,即需要和训练的图像的尺寸相同
2.调用predict()函数进行人脸预测,该函数会返回两个元素的数组,第一个是识别个体的标签,第二个是置信度,越小匹配度越高,0表示完全匹配,需要了解的是不同算法的置信度评分机制不同。
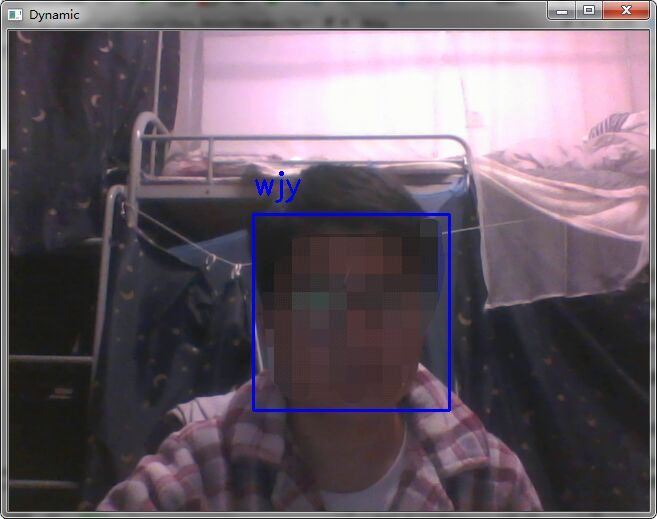
附上结果图
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 27 11:43:47 2018
@author: Administrator
"""
'''
调用opencv的库实现人脸识别
'''
import cv2
import numpy as np
import os
import shutil
#采集自己的人脸数据
def generator(data):
'''
打开摄像头,读取帧,检测该帧图像中的人脸,并进行剪切、缩放
生成图片满足以下格式:
1.灰度图,后缀为 .png
2.图像大小相同
params:
data:指定生成的人脸数据的保存路径
'''
name=input('my name:')
#如果路径存在则删除路径
path=os.path.join(data,name)
if os.path.isdir(path):
shutil.rmtree(path)
#创建文件夹
os.mkdir(path)
#创建一个级联分类器
face_casecade=cv2.CascadeClassifier('../haarcascades/haarcascade_frontalface_default.xml')
#打开摄像头
camera=cv2.VideoCapture(0)
cv2.namedWindow('Dynamic')
#计数
count=1
while(True):
#读取一帧图像
ret,frame=camera.read()
if ret:
#转换为灰度图
gray_img=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#人脸检测
face=face_casecade.detectMultiScale(gray_img,1.3,5)
for (x,y,w,h) in face:
#在原图上绘制矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),2)
#调整图像大小
new_frame=cv2.resize(frame[y:y+h,x:x+w],(92,112))
#保存人脸
cv2.imwrite('%s/%s.png'%(path,str(count)),new_frame)
count+=1
cv2.imshow('Dynamic',frame)
#按下q键退出
if cv2.waitKey(100) & 0xff==ord('q'):
break
camera.release()
cv2.destroyAllWindows()
#载入图像 读取ORL人脸数据库,准备训练数据
def LoadImages(data):
'''
加载图片数据用于训练
params:
data:训练数据所在的目录,要求图片尺寸一样
ret:
images:[m,height,width] m为样本数,height为高,width为宽
names:名字的集合
labels:标签
'''
images=[]
names=[]
labels=[]
label=0
#遍历所有文件夹
for subdir in os.listdir(data):
subpath=os.path.join(data,subdir)
#print('path',subpath)
#判断文件夹是否存在
if os.path.isdir(subpath):
#在每一个文件夹中存放着一个人的许多照片
names.append(subdir)
#遍历文件夹中的图片文件
for filename in os.listdir(subpath):
imgpath=os.path.join(subpath,filename)
img=cv2.imread(imgpath,cv2.IMREAD_COLOR)
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#cv2.imshow('1',img)
#cv2.waitKey(0)
images.append(gray_img)
labels.append(label)
label+=1
images=np.asarray(images)
#names=np.asarray(names)
labels=np.asarray(labels)
return images,labels,names
#检验训练结果
def FaceRec(data):
#加载训练的数据
X,y,names=LoadImages(data)
#print('x',X)
model=cv2.face.EigenFaceRecognizer_create()
model.train(X,y)
#打开摄像头
camera=cv2.VideoCapture(0)
cv2.namedWindow('Dynamic')
#创建级联分类器
face_casecade=cv2.CascadeClassifier('../haarcascades/haarcascade_frontalface_default.xml')
while(True):
#读取一帧图像
#ret:图像是否读取成功
#frame:该帧图像
ret,frame=camera.read()
#判断图像是否读取成功
#print('ret',ret)
if ret:
#转换为灰度图
gray_img=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#利用级联分类器鉴别人脸
faces=face_casecade.detectMultiScale(gray_img,1.3,5)
#遍历每一帧图像,画出矩形
for (x,y,w,h) in faces:
frame=cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2) #蓝色
roi_gray=gray_img[y:y+h,x:x+w]
try:
#将图像转换为宽92 高112的图像
#resize(原图像,目标大小,(插值方法)interpolation=,)
roi_gray=cv2.resize(roi_gray,(92,112),interpolation=cv2.INTER_LINEAR)
params=model.predict(roi_gray)
print('Label:%s,confidence:%.2f'%(params[0],params[1]))
'''
putText:给照片添加文字
putText(输入图像,'所需添加的文字',左上角的坐标,字体,字体大小,颜色,字体粗细)
'''
cv2.putText(frame,names[params[0]],(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2)
except:
continue
cv2.imshow('Dynamic',frame)
#按下q键退出
if cv2.waitKey(100) & 0xff==ord('q'):
break
camera.release()
cv2.destroyAllWindows()
if __name__=='__main__':
data='./face'
#generator(data)
FaceRec(data)
python三步实现人脸识别
Face Recognition软件包
这是世界上最简单的人脸识别库了。你可以通过Python引用或者命令行的形式使用它,来管理和识别人脸。
该软件包使用dlib中最先进的人脸识别深度学习算法,使得识别准确率在《Labled Faces in the world》测试基准下达到了99.38%。
它同时提供了一个叫face_recognition的命令行工具,以便你可以用命令行对一个文件夹中的图片进行识别操作。
特性
在图片中识别人脸
找到图片中所有的人脸


找到并操作图片中的脸部特征
获得图片中人类眼睛、鼻子、嘴、下巴的位置和轮廓


找到脸部特征有很多超级有用的应用场景,当然你也可以把它用在最显而易见的功能上:美颜功能(就像美图秀秀那样)。

鉴定图片中的脸
识别图片中的人是谁。


你甚至可以用这个软件包做人脸的实时识别。

这里有一个实时识别的例子:
1 | https://github.com/ageitgey/face_recognition/blob/master/examples/facerec_from_webcam_faster.py |
安装
环境要求
-
Python3.3+或者Python2.7
-
MacOS或者Linux(Windows不做支持,但是你可以试试,也许也能运行)
安装步骤
在MacOS或者Linux上安装
首先,确保你安装了dlib,以及该软件的Python绑定接口。如果没有的话,看这篇安装说明:
1 | https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf |
然后,用pip安装这个软件包:

如果你安装遇到问题,可以试试这个安装好了的虚拟机:
1 | https://medium.com/@ageitgey/try-deep-learning-in-python-now-with-a-fully-pre-configured-vm-1d97d4c3e9b |
在树莓派2+上安装
看这篇说明:
1 | https://gist.github.com/ageitgey/1ac8dbe8572f3f533df6269dab35df65 |
在Windows上安装
虽然Windows不是官方支持的,但是有热心网友写出了一个Windows上的使用指南,请看这里:
1 | https://github.com/ageitgey/face_recognition/issues/175#issue-257710508 |
使用已经配置好的虚拟机(支持VMWare和VirtualBox)
看这篇说明:
1 | https://medium.com/@ageitgey/try-deep-learning-in-python-now-with-a-fully-pre-configured-vm-1d97d4c3e9b |
使用方法
命令行接口
如果你已经安装了face_recognition,那么你的系统中已经有了一个名为face_recognition的命令,你可以使用它对图片进行识别,或者对一个文件夹中的所有图片进行识别。
首先你需要提供一个文件夹,里面是所有你希望系统认识的人的图片。其中每个人一张图片,图片以人的名字命名。

然后你需要准备另一个文件夹,里面是你要识别的图片。

然后你就可以运行face_recognition命令了,把刚刚准备的两个文件夹作为参数传入,命令就会返回需要识别的图片中都出现了谁。

输出中,识别到的每张脸都单独占一行,输出格式为
通过Python模块使用
你可以通过导入face_recognition模块来使用它,使用方式超级简单,文档在这里:https://face-recognition.readthedocs.io
自动找到图片中所有的脸

看看这个例子自己实践一下:
1 | https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py |
你还可以自定义替换人类识别的深度学习模型。
注意:想获得比较好的性能的话,你可能需要GPU加速(使用英伟达的CUDA库)。所以编译的时候你也需要开启dlib的GPU加速选项。

你也可以通过这个例子实践一下:
1 | https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture_cnn.py |
如果你有很多图片和GPU,你也可以并行快速识别,看这篇文章:
1 | https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_batches.py |
自动识别人脸特征

试试这个例子:
1 | https://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py |
识别人脸鉴定是哪个人

这里是一个例子:
1
https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py