转载自:http://blog.csdn.net/xuanjiewu/article/details/50636465
假设我们有两张表。Table A 是左边的表。Table B 是右边的表。其各有四条记录,其中有两条记录name是相同的,如下所示:让我们看看不同JOIN的不同。

1. INNER JOIN
select * from tablea a join tableb b on a.name = b.name;


inner join 查询的是交集中的数据
其中join的是(inner join)的缩写
2. FULL [OUTER] JOIN
(1)
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
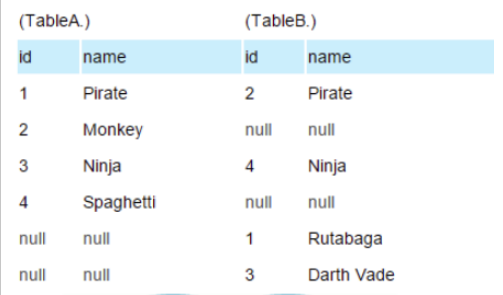
Full outer join 产生A和B的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。
可以使用IFNULL判断。
注意:这个在获取到数据进行展示的时候,要注意NULL的判断。
注:
mysql 5.5并不支持full join

但是可以使用union all 来变相实现,并不是很方便

使用一个左连接一个右连接,然后加上一个union的效果,就与fulljoin的效果一样了

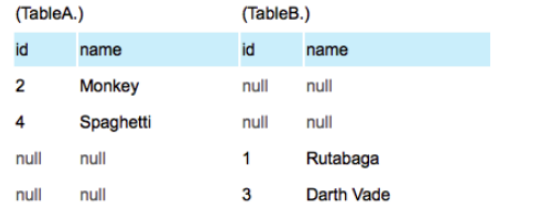
(2) 同时使用ISNULL 的判断,可以取得A和B两者没有交集的数据集。
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableA.id IS null OR TableB.id IS null
总结:这个很好用,可以用来对生产或者测试上的数据进行补数据的操作。mysql可以使用以上方法仿full join

3. LEFT [OUTER] JOIN
(1) SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name
注意:这个可能很常用,但是注意B中匹配到了才有值,没有匹配到会变成NULL。相当于以table A为主表,table B为附表,A表中所有数据全都查询出来,B表中与A表有相对应数据就显示,
没有就制空
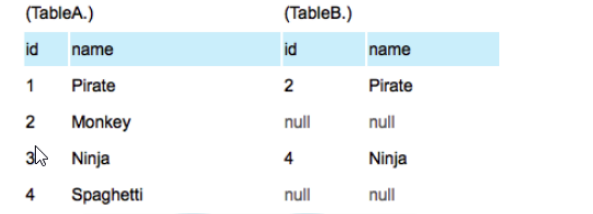
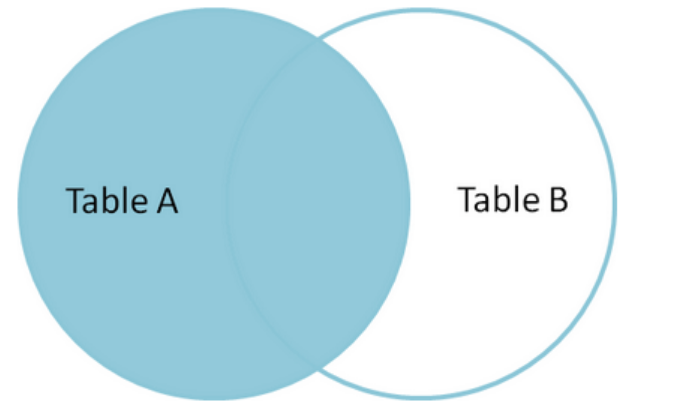
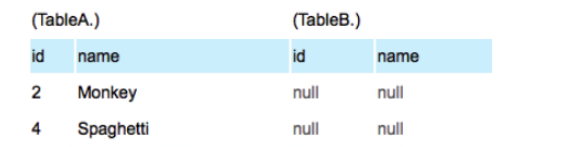
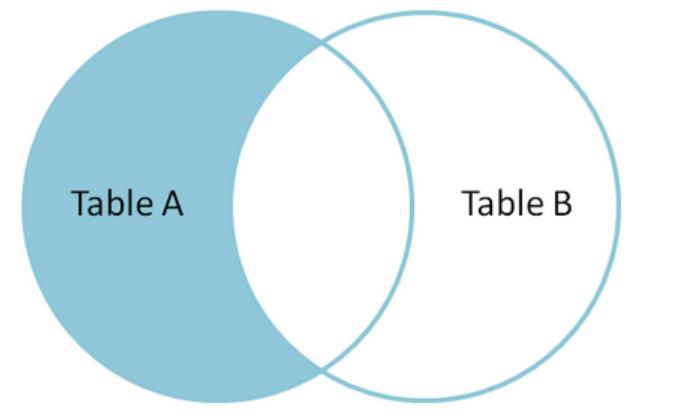
(2) LEFT JOIN 结合where IS NULL ,可以取得只有在A中的数据集。
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableB.id IS null
4. RIGHT [OUTER] JOIN
RIGHT OUTER JOIN 是后面的表为基础,与LEFT OUTER JOIN用法类似。这里不介绍了。
5. UNION 与 UNION ALL
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意,a。 UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。
b。每条 SELECT 语句中的列的顺序必须相同。
c。UNION 只选取记录,每一行的数据都是不一样的。而UNION ALL会列出所有记录,重复的也会列出来

(1)
select name from tablea union select name from tableb;
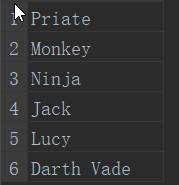
(3) 注意:
SELECT * FROM TableA UNION SELECT * FROM TableB
由于 id 1 Pirate 与 id 2 Pirate 并不相同,不合并

还需要注意的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。表达式如下:
select * from tablea cross join tableb; select * from tablea,tableb;
这两个SQL是一样的, 这个笛卡尔乘积会产生 4 x 4 = 16 条记录,
一般来说,我们很少用到这个语法。但是我们得小心,如果是使用嵌套的select语句,再加上系统对SQL都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。
这里我们看出
SELECT 选择的是从‘结果集1’中取得某几列。 FROM 是从 哪些 ‘数据源’中获取数据,而这些数据源是可以通过各种JOIN进行挑选的。 WHERE 再加上where 从 select出的‘结果集2’ 中限制某些数据 LIMIT 进而限制挑选, GROUP 可以重新挑选组合集合。 ORDER BY进行结果的排序等。
说到底,SQL是对集合的获取。