Scrapy
1. 简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy 使用了 Twisted异步网络库来处理网络通讯。
1.1.整体架构大致如下
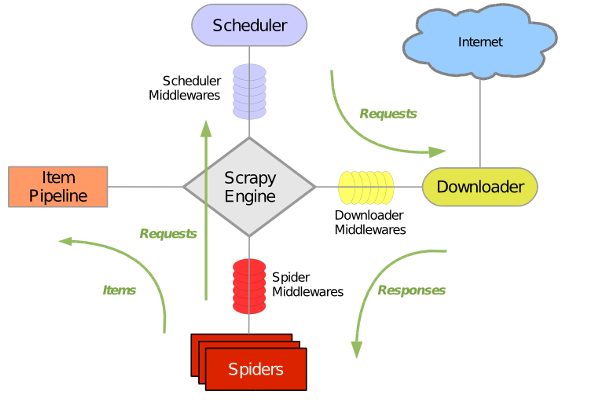
Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
1.2 运行流程
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
2 安装
安装wheel
pip install wheel
安装scrapy
pip install scrapy
3 Scrapy项目示例
此项目爬取豆瓣Top250 影视作品的信息 地址为http://movie.douban.com/top250
3.1 创建工程
创建工程 scrapy startproject XXXXX XXXXX代表你项目的名字
项目创建完会产生如下目录结构
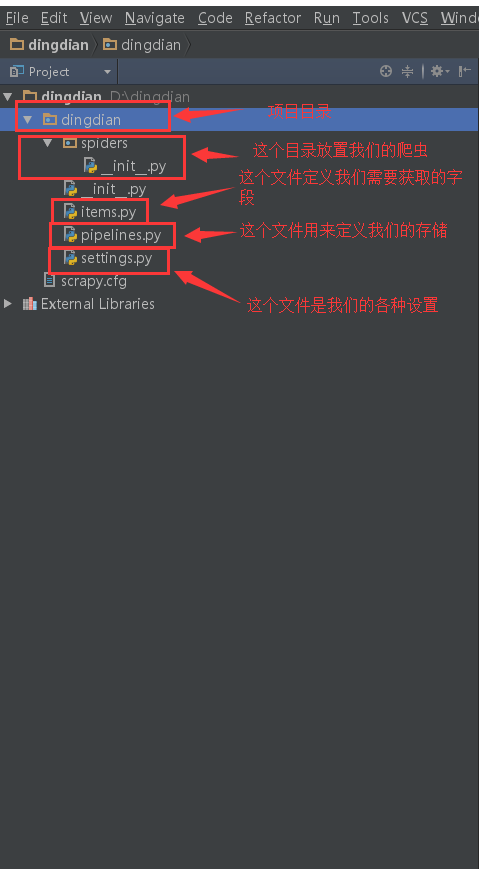
3.2 设置数据存储模板
设置储存模板 items.py
from scrapy import Item, Field class DoubanItem(Item): # define the fields for your item here like: # name = scrapy.Field() title = Field() movieInfo = Field() star = Field() quote = Field()
3.3编写爬虫
编写爬虫Sider 集成父类CrawSpider name 为到时执行爬虫的name
class Douban(CrawlSpider):
name = "douban"
start_urls = ['http://movie.douban.com/top250']
url = 'http://movie.douban.com/top250'
def parse(self, response):
# print response.body
item = DoubanItem()
selector = Selector(response)
# print selector
Movies = selector.xpath('//div[@class="info"]')
# print Movies
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
# 把两个名称合起来
fullTitle = ''
for each in title:
fullTitle += each
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,因此需要先进行判断
if quote:
quote = quote[0]
else:
quote = ''
# print fullTitle
# print movieInfo
# print star
# print quote
item['title'] = fullTitle
item['movieInfo'] = ';'.join(movieInfo)
item['star'] = star
item['quote'] = quote
yield item
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
# 第10页是最后一页,没有下一页的链接
if nextLink:
nextLink = nextLink[0]
print(nextLink)
yield Request(self.url + nextLink, callback=self.parse)
3.4 编写数据处理脚本
在这里可以对数据进行处理,或进行持久化保存到mysql,mongodb等数据库
from mongodb.dao import MONGO_CLIENT, DB_NAME,COLLECTION_NAME
class Douban250Pipeline(object):
def process_item(self, item, spider):
collection = MONGO_CLIENT[DB_NAME][COLLECTION_NAME]
collection.insert_one({
'title': item['title'],
'movieInfo': item['movieInfo'],
'star': item['star'],
'quote': item['quote']
})
print(item)
return item
3.5 修改配置文件
修改PIPELINES ITEM_PIPELINES={ 'douban250.pipelines.Douban250Pipeline':300, }
伪造身份 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
3.6 执行爬虫
scrapy crawl douban
#执行结果