运行环境:Anaconda3 + PyCharm + PyTorch + python3
这是《深度学习框架PyTorch入门与实践》的第七章示例,利用生成对抗网络生成动漫人物头像。
作者陈云的GitHub:https://github.com/chenyuntc/pytorch-book/tree/master/chapter07-AnimeGAN 这里有实现该示例的代码。
原书给的动漫人物头像数据集百度网盘链接https://pan.baidu.com/s/1eSifHcA 提取码:g5qa 失效了,不知道后续会不会补资源,先贴在这里。
这篇博客讲解详细,并且有可实现的代码及数据集百度网盘资源,建议参考:https://www.cnblogs.com/wanghui-garcia/p/10785579.html
如何安装visdom:https://zhuanlan.zhihu.com/p/138534069
本篇作为学习笔记,在代码中给一些注释。
model.py
定义生成器:
class NetG(nn.Module):
"""
生成器定义
"""
def __init__(self, opt):
super(NetG, self).__init__()
ngf = opt.ngf # 生成器feature map数
self.main = nn.Sequential(
# 输入是一个nz维度的噪声,我们可以认为它是一个1*1*nz的feature map
nn.ConvTranspose2d(opt.nz, ngf * 8, 4, 1, 0, bias=False),
# torch.nn.ConvTranspose2d(in_channels: int,
# out_channels: int,
# kernel_size: Union[T, Tuple[T, T]],
# stride: Union[T, Tuple[T, T]] = 1,
# padding: Union[T, Tuple[T, T]] = 0,
# output_padding: Union[T, Tuple[T, T]] = 0,
# groups: int = 1, bias: bool = True,
# dilation: int = 1,
# padding_mode: str = 'zeros')
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# torch.nn.ReLU(inplace: bool = False)
# ReLU输出为max(0, x)
# 输出形状:(ngf * 8) * 4 * 4
# 上一步的输出形状:(ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 上一步的输出形状: (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 上一步的输出形状: (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上一步的输出形状:(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh() # 输出范围 -1~1 故而采用Tanh
# 输出形状:3 x 96 x 96
)
def forward(self, input):
return self.main(input)
定义判别器:
class NetD(nn.Module): """ 判别器定义 """ def __init__(self, opt): super(NetD, self).__init__() ndf = opt.ndf self.main = nn.Sequential( # 输入 3 x 96 x 96 nn.Conv2d(3, ndf, 5, 3, 1, bias=False), nn.LeakyReLU(0.2, inplace=True), # torch.nn.LeakyReLU(negative_slope: float = 0.01, inplace: bool = False) # LeakyReLU(x)=max(0,x)+negative_slope∗min(0,x) # 与ReLU相比,LeakyReLU的输出中小于0的部分为趋近于0的负数 # 输出 (ndf) x 32 x 32 nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 2), nn.LeakyReLU(0.2, inplace=True), # 输出 (ndf*2) x 16 x 16 nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 4), nn.LeakyReLU(0.2, inplace=True), # 输出 (ndf*4) x 8 x 8 nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 8), nn.LeakyReLU(0.2, inplace=True), # 输出 (ndf*8) x 4 x 4 nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False), nn.Sigmoid() # 输出一个数(概率) ) def forward(self, input): return self.main(input).view(-1)
main.py
模型配置参数:
# coding:utf8 import os import ipdb import torch as t import torchvision as tv import tqdm from model import NetG, NetD from torchnet.meter import AverageValueMeter class Config(object): # data_path = 'data/' # 数据集存放路径 data_path = 'E:/pycharm projects/book1/chapter7/data/' # 存放图片的文件夹。注意,需要在data中建立一个文件夹,保存图片,才能使用dataloader num_workers = 4 # 多进程加载数据所用的进程数 image_size = 96 # 图片尺寸 batch_size = 256 max_epoch = 1 lr1 = 2e-4 # 生成器的学习率 lr2 = 2e-4 # 判别器的学习率 beta1 = 0.5 # Adam优化器的beta1参数 gpu = True # 是否使用GPU nz = 100 # 噪声维度 ngf = 64 # 生成器feature map数 ndf = 64 # 判别器feature map数 # save_path = 'imgs/' # 生成图片保存路径 save_path = 'E:/pycharm projects/book1/chapter7/images' vis = True # 是否使用visdom可视化 env = 'GAN' # visdom的env,在窗口工具栏中中选择该环境,显示训练图片结果 plot_every = 20 # 每间隔20 batch,visdom画图一次 debug_file = 'debug/debug.txt' # 存在该文件则进入debug模式 d_every = 1 # 每1个batch训练一次判别器 g_every = 5 # 每5个batch训练一次生成器 save_every = 10 # 每10个epoch保存一次模型 netd_path = None # 'checkpoints/netd_.pth' #预训练模型 netg_path = None # 'checkpoints/netg_211.pth' # 只测试不训练 gen_img = 'result.png' # 从512张生成的图片中保存最好的64张 gen_num = 64 gen_search_num = 512 gen_mean = 0 # 噪声的均值 gen_std = 1 # 噪声的方差 opt = Config()
训练:
def train(**kwargs): # 可以接收任意数量关键词参数的kwargs for k_, v_ in kwargs.items(): setattr(opt, k_, v_) # setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的 # setattr(object, name, value) device = t.device('cuda') if opt.gpu else t.device('cpu') if opt.vis: from visualize import Visualizer vis = Visualizer(opt.env) # 数据 transforms = tv.transforms.Compose([ tv.transforms.Resize(opt.image_size), # torchvision.transforms.Resize(size, interpolation=2) 重新定义尺寸 tv.transforms.CenterCrop(opt.image_size), # torchvision.transforms.CenterCrop(size) 在中心裁剪给定的图像 tv.transforms.ToTensor(), tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms) dataloader = t.utils.data.DataLoader(dataset, batch_size=opt.batch_size, shuffle=True, num_workers=opt.num_workers, drop_last=True ) # 网络 netg, netd = NetG(opt), NetD(opt) # 将定义的参数输入网络中 map_location = lambda storage, loc: storage #将Tensor默认加载入内存中,待有需要时再移至显存中 if opt.netd_path: netd.load_state_dict(t.load(opt.netd_path, map_location=map_location)) if opt.netg_path: netg.load_state_dict(t.load(opt.netg_path, map_location=map_location)) netd.to(device) netg.to(device) # 定义优化器和损失 optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999)) # torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False) optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999)) criterion = t.nn.BCELoss().to(device) # 计算二分类误差 # 真图片label为1,假图片label为0 # noises为生成网络的输入 true_labels = t.ones(opt.batch_size).to(device) fake_labels = t.zeros(opt.batch_size).to(device) fix_noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device) noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device) errord_meter = AverageValueMeter() # 测量并返回添加到其中的任何数字集合的平均值和标准偏差。 例如,测量一组示例中的平均损失很有用。 errorg_meter = AverageValueMeter() epochs = range(opt.max_epoch) for epoch in iter(epochs): for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)): real_img = img.to(device) if ii % opt.d_every == 0: # 训练判别器 optimizer_d.zero_grad() # 梯度清零 # 尽可能的把真图片判别为正确 output = netd(real_img) error_d_real = criterion(output, true_labels) error_d_real.backward() # 反向传播 # 尽可能把假图片判别为错误 noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1)) fake_img = netg(noises).detach() # 根据噪声生成假图 # detach()进行计算图截断,避免反向传播将梯度传到生成器中 output = netd(fake_img) error_d_fake = criterion(output, fake_labels) error_d_fake.backward() optimizer_d.step() # 更新参数 error_d = error_d_fake + error_d_real errord_meter.add(error_d.item()) if ii % opt.g_every == 0: # 训练生成器 optimizer_g.zero_grad() noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1)) fake_img = netg(noises) output = netd(fake_img) error_g = criterion(output, true_labels) error_g.backward() optimizer_g.step() errorg_meter.add(error_g.item()) if opt.vis and ii % opt.plot_every == opt.plot_every - 1: ## 可视化 import os if os.path.exists(opt.debug_file): ipdb.set_trace() fix_fake_imgs = netg(fix_noises) vis.images(fix_fake_imgs.detach().cpu().numpy()[:64] * 0.5 + 0.5, win='fixfake') vis.images(real_img.data.cpu().numpy()[:64] * 0.5 + 0.5, win='real') vis.plot('errord', errord_meter.value()[0]) vis.plot('errorg', errorg_meter.value()[0]) if (epoch+1) % opt.save_every == 0: # 保存模型、图片 tv.utils.save_image(fix_fake_imgs.data[:64], '%s/%s.png' % (opt.save_path, epoch), normalize=True, range=(-1, 1)) t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch) t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch) errord_meter.reset() errorg_meter.reset()
测试(生成):
@t.no_grad() # 数据不需要计算梯度,也不会进行反向传播 def generate(**kwargs): """ 随机生成动漫头像,并根据netd的分数选择较好的 """ for k_, v_ in kwargs.items(): setattr(opt, k_, v_) device = t.device('cuda') if opt.gpu else t.device('cpu') netg, netd = NetG(opt).eval(), NetD(opt).eval() # Sets the module in evaluation mode 置为评价模式,与训练模式不同,有些参数不需要存储 noises = t.randn(opt.gen_search_num, opt.nz, 1, 1).normal_(opt.gen_mean, opt.gen_std) noises = noises.to(device) map_location = lambda storage, loc: storage netd.load_state_dict(t.load(opt.netd_path, map_location=map_location)) netg.load_state_dict(t.load(opt.netg_path, map_location=map_location)) netd.to(device) netg.to(device) # 生成图片,并计算图片在判别器的分数 fake_img = netg(noises) scores = netd(fake_img).detach() # 此处可以不用detach()? # 挑选最好的某几张 indexs = scores.topk(opt.gen_num)[1] result = [] for ii in indexs: result.append(fake_img.data[ii]) # 保存图片 tv.utils.save_image(t.stack(result), opt.gen_img, normalize=True, range=(-1, 1))
执行main函数:
if __name__ == '__main__': import fire fire.Fire() train(gpu=True, vis=True, batch_size=256, max_epoch=200) # generate
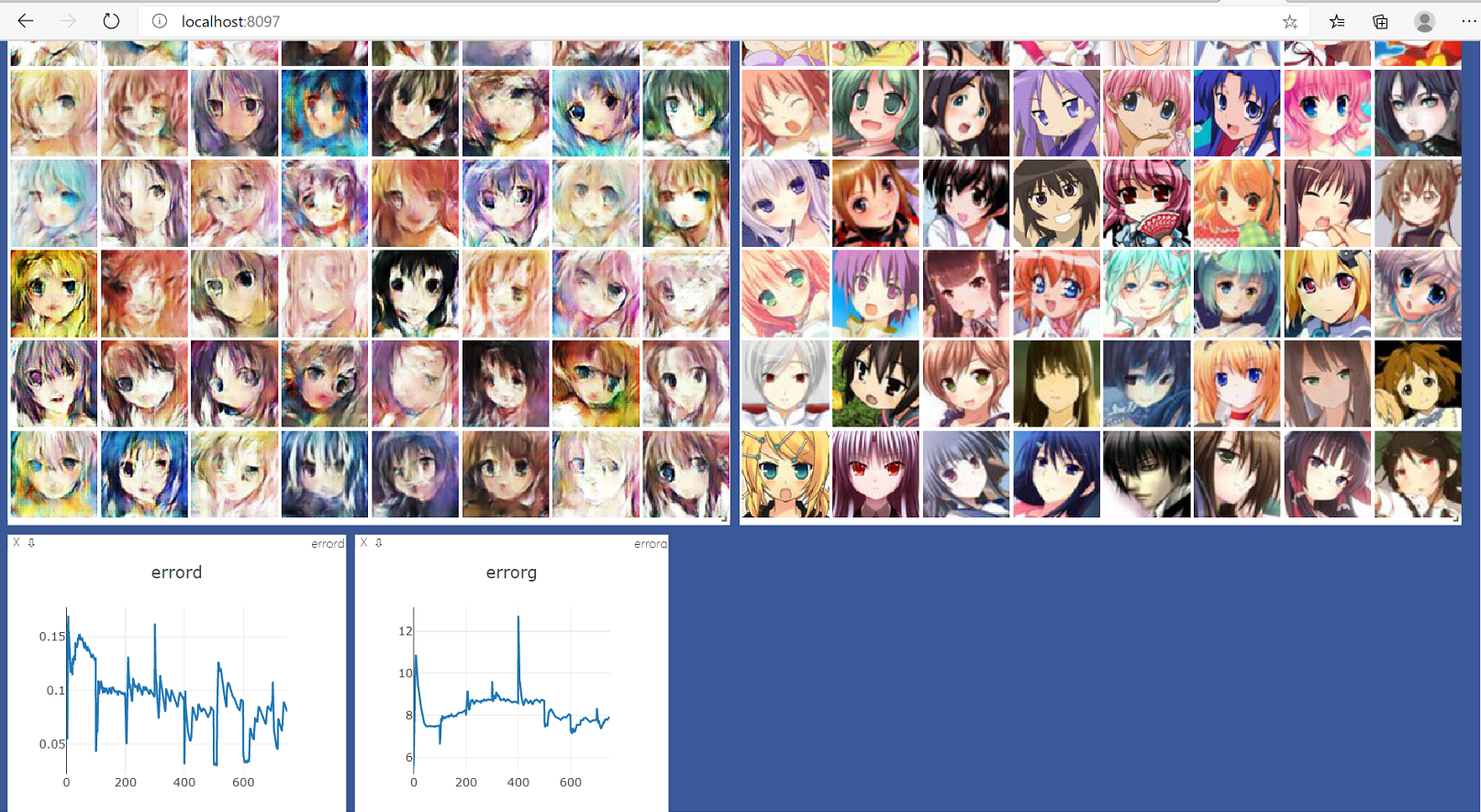
训练过程在visdom中显示,左边是生成的动漫头像,右边是训练样本,下面两个分别是判别和生成器的误差。