1.读取
# 读取数据集
def read_dataset():
file_path = r'dataSMSSpamCollection'
sms = open(file_path, encoding='utf-8')
sms_data = []
sms_label = []
csv_reader = csv.reader(sms, delimiter=' ')
for line in csv_reader:
sms_label.append(line[0]) # 提取出标签
sms_data.append(preprocessing(line[1])) # 提取出特征
sms.close()
return sms_data, sms_label
2.数据预处理
# 预处理
def preprocessing(text):
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)] # 分词
stops = stopwords.words('english') # 使用英文的停用词表
tokens = [token for token in tokens if token not in stops] # 去除停用词
tokens = [token.lower() for token in tokens if len(token) >= 3] # 大小写,短词
lmtzr = WordNetLemmatizer()
tag = nltk.pos_tag(tokens) # 词性
tokens = [lmtzr.lemmatize(token, pos=get_wordnet_pos(tag[i][1])) for i, token in enumerate(tokens)] # 词性还原
preprocessed_text = ' '.join(tokens)
return preprocessed_text
3.数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)
# 划分数据集
def split_dataset(data, label):
x_train, x_test, y_train, y_test = train_test_split(data, label, test_size=0.2, random_state=0, stratify=label)
return x_train, x_test, y_train, y_test
4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
观察邮件与向量的关系
向量还原为邮件
# 把原始文本转化为tf-idf的特征矩阵
def tfidf_dataset(x_train,x_test):
tfidf = TfidfVectorizer()
X_train = tfidf.fit_transform(x_train) # X_train用fit_transform生成词汇表
X_test = tfidf.transform(x_test) # X_test要与X_train词汇表相同,因此在X_train进行fit_transform基础上进行transform操作
return X_train, X_test, tfidf
4.模型选择
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
# 模型选择(根据数据特点选择多项式分布)
def mnb_model(x_train, x_test, y_train, y_test):
mnb = MultinomialNB()
mnb.fit(x_train, y_train)
ypre_mnb = mnb.predict(x_test)
print("总数:", len(y_test))
print("预测正确数:", (ypre_mnb == y_test).sum())
return ypre_mnb

朴素贝叶斯模型被广泛应用于互联网新闻的分类、垃圾邮件的筛选等分类任务,它单独考量每一维度特征被分类的条件概率,然后综合这些概率对其所在的特征向量做出分类预测,即“假设各个维度上的特征被分类的条件概率之间是相互独立的”,该假设使得模型预测需要估计的参数规模从指数数量级减少到线性数量级,极大地节约了计算时间和空间。该模型在训练时没考虑各个特征之间的联系,对于数据特征关联性较强的分类任务表现不好
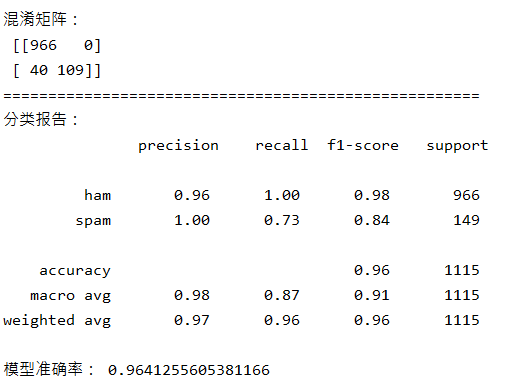
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
精确率(precision)的公式是 ,它计算的是所有"正确被检索的item(TP)"占所有"实际被检索到的(TP+FP)"的比例.
,它计算的是所有"正确被检索的item(TP)"占所有"实际被检索到的(TP+FP)"的比例.
F1值就是精确值和召回率的调和均值
# 模型评价:混淆矩阵,分类报告
def class_report(ypre_mnb, y_test):
conf_matrix = confusion_matrix(y_test, ypre_mnb)
print("=====================================================")
print("混淆矩阵:
", conf_matrix)
c = classification_report(y_test, ypre_mnb)
print("=====================================================")
print("分类报告:
", c)
print("模型准确率:", (conf_matrix[0][0] + conf_matrix[1][1]) / np.sum(conf_matrix))
6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
用CountVectorizer虽在总样本中表现看似优秀,但其实际对样本个体预测的误差要高于使用TfidfVectorizer。
