基本概念
Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习。
NRT
Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索,有一段非常小的延迟(大约1秒左右),二是基于Elasticsearch的搜索和分析操作,耗时可以达到秒级。
Cluster
集群,对外提供索引和搜索的服务,包含一个或多个节点,每个节点属于哪个集群是通过集群名称来决定的(默认名称是elasticsearch),集群名称搞错了后果很严重。命名建议是研发、测试环境、准生产、生产环境用不同的名称增加区分度,例如研发使用es-dev,测试使用es-test,准生产使用es-stg,生产环境使用es-pro这样的名字来区分。如果是中小型应用,集群可以只有一个节点。
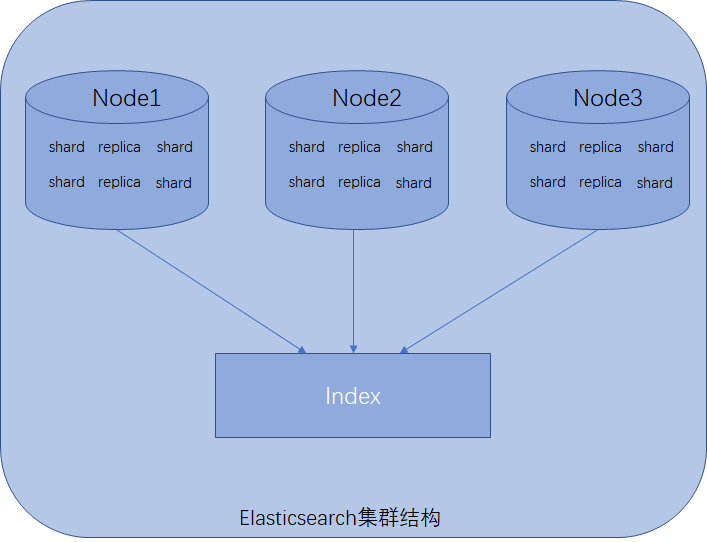
Node
单独一个Elasticsearch服务器实例称为一个node,node是集群的一部分,每个node有独立的名称,默认是启动时获取一个UUID作为名称,也可以自行配置,node名称特别重要,Elasticsearch集群是通过node名称进行管理和通信的,一个node只能加入一个Elasticsearch集群当中,集群提供完整的数据存储,索引和搜索的功能,它下面的每个node分摊上述功能(每条数据都会索引到node上)。
shard
分片,是单个Lucene索引,由于单台机器的存储容量是有限的(如1TB),而Elasticsearch索引的数据可能特别大(PB级别,并且30GB/天的写入量),单台机器无法存储全部数据,就需要将索引中的数据切分为多个shard,分布在多台服务器上存储。利用shard可以很好地进行横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升集群整体的吞吐量和性能。
shard在使用时比较简单,只需要在创建索引时指定shard的数量即可,剩下的都交给Elasticsearch来完成,只是创建索引时一旦指定shard数量,后期就不能再更改了。
replica
索引副本,完全拷贝shard的内容,shard与replica的关系可以是一对多,同一个shard可以有一个或多个replica,并且同一个shard下的replica数据完全一样,replica作为shard的数据拷贝,承担以下三个任务:
- shard故障或宕机时,其中一个replica可以升级成shard。
- replica保证数据不丢失(冗余机制),保证高可用。
- replica可以分担搜索请求,提升整个集群的吞吐量和性能。
shard的全称叫primary shard,replica全称叫replica shard,primary shard数量在创建索引时指定,后期不能修改,replica shard后期可以修改。默认每个索引的primary shard值为5,replica shard值为1,含义是5个primary shard,5个replica shard,共10个shard。
因此Elasticsearch最小的高可用配置是2台服务器。
Index
索引,具有相同结构的文档集合,类似于关系型数据库的数据库实例(6.0.0版本type废弃后,索引的概念下降到等同于数据库表的级别)。一个集群里可以定义多个索引,如客户信息索引、商品分类索引、商品索引、订单索引、评论索引等等,分别定义自己的数据结构。
索引命名要求全部使用小写,建立索引、搜索、更新、删除操作都需要用到索引名称。
type
类型,原本是在索引(Index)内进行的逻辑细分,但后来发现企业研发为了增强可阅读性和可维护性,制订的规范约束,同一个索引下很少还会再使用type进行逻辑拆分(如同一个索引下既有订单数据,又有评论数据),因而在6.0.0版本之后,此定义废弃。
Document
文档,Elasticsearch最小的数据存储单元,JSON数据格式,类似于关系型数据库的表记录(一行数据),结构定义多样化,同一个索引下的document,结构尽可能相同。
工作原理
简单地了解一下Elasticsearch的工作原理。
启动过程
当Elasticsearch的node启动时,默认使用广播寻找集群中的其他node,并与之建立连接,如果集群已经存在,其中一个节点角色特殊一些,叫coordinate node(协调者,也叫master节点),负责管理集群node的状态,有新的node加入时,会更新集群拓扑信息。如果当前集群不存在,那么启动的node就自己成为coordinate node。
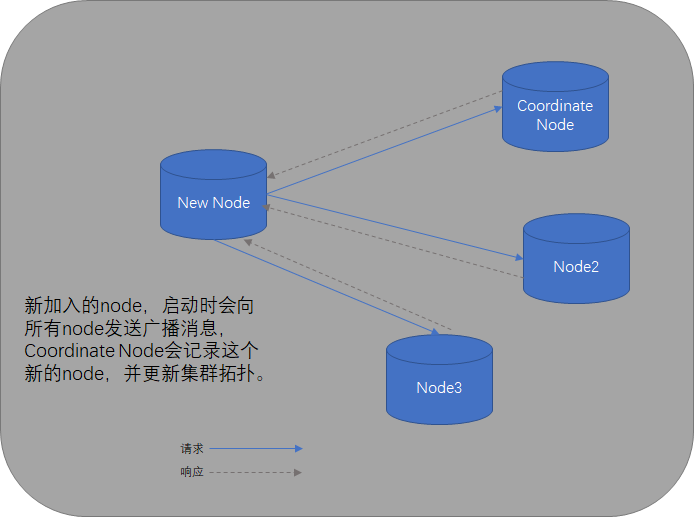
应用程序与集群通信过程
虽然Elasticsearch设置了Coordinate Node用来管理集群,但这种设置对客户端(应用程序)来说是透明的,客户端可以请求任何一个它已知的node,如果该node是集群当前的Coordinate,那么它会将请求转发到相应的Node上进行处理,如果该node不是Coordinate,那么该node会先将请求转交给Coordinate Node,再由Coordinate进行转发,搓着各node返回的数据全部交由Coordinate Node进行汇总,最后返回给客户端。
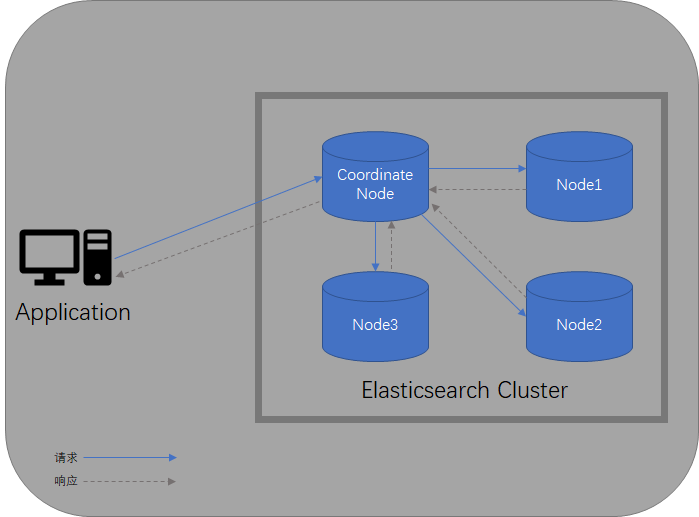
集群内node有效性检测
正常工作时,Coordinate Node会定期与拓扑结构中的Node进行通信,检测实例是否正常工作,如果在指定的时间周期内,Node无响应,那么集群会认为该Node已经宕机。集群会重新进行均衡:
- 重新分配宕机的Node,其他Node中有该Node的replica shard,选出一个replica shard,升级成为primary shard。
- 重新安置新的shard。
- 拓扑更新,分发给该Node的请求重新映射到目前正常的Node上。
小结
本篇章简单的向大家介绍了一下Elasticsearch的基本概念和工作原理,让大家有个比较浅显的认识,后续会结合实际的例子,来了解一下Elasticsearch基本的用法。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区
