环境:Centos6.9+jdk+hadoop
1.下载hadoop的tar包,这里以hadoop2.6.5版本为例,下载地址https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
2.修改linux虚拟机的主机名HOSTNAME的值改为hadoop01.zjl.com
# vi /etc/sysconfig/network
NETWORKING=yes HOSTNAME=hadoop01.zjl.com
3.配置主机名和IP地址的映射,在/etc/hosts文件末尾 追加192.168.0.131 hadoop01.zjl.com hadoop01
# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.0.131 hadoop01.zjl.com hadoop01
4.关闭防火墙后,重启虚拟机,是步骤2、3、4的配置生效
service iptables stop
service ip6tables stop
service iptables status
service ip6tables status
chkconfig iptables off
chkconfig ip6tablesoff
vi /etc/selinux/config
SELINUX=disabled
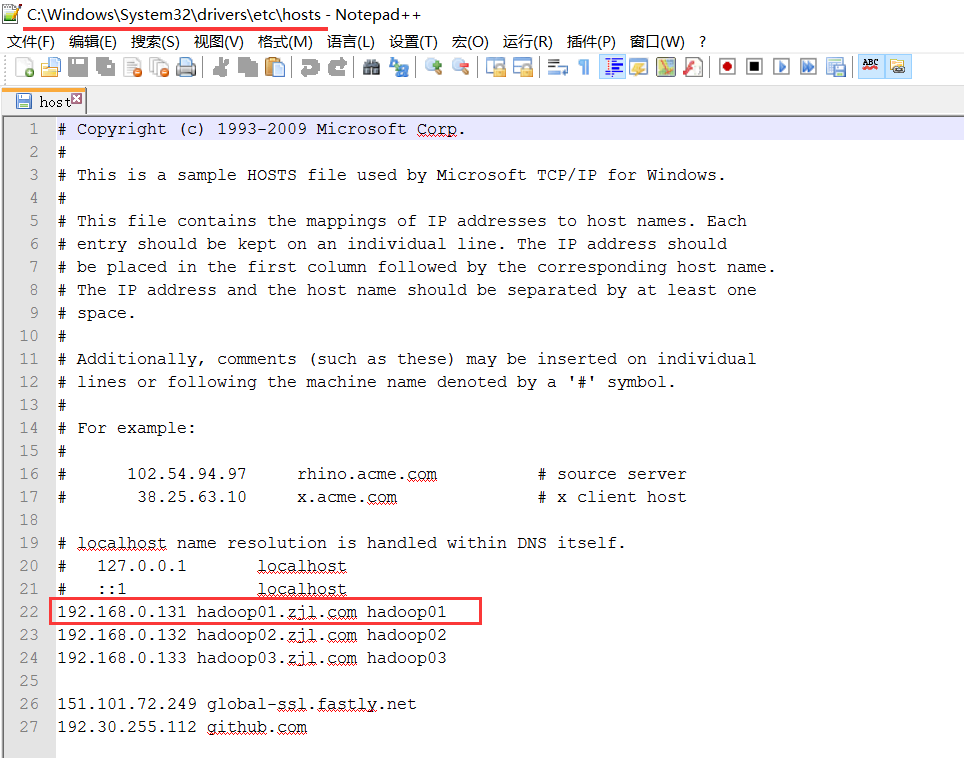
5.在物理机的hosts文件中配置192.168.0.131 hadoop01.zjl.com hadoop01,我的物理机是win10 64位操作系统,hosts文件的位置是C:WindowsSystem32driversetchosts
6.(1)执行# rpm -qa|grep java,发现虚拟机中没装过jdk,如果装过可以用# rpm -e --nodeps来卸载
(2)jdk安装包没有执行权限
# ll jdk-8u131-linux-x64.tar.gz -rw-rw-r--. 1 hadoop hadoop 185540433 May 20 22:57 jdk-8u131-linux-x64.tar.gz
(3)给安装包授予执行权限
$ chmod u+x jdk-8u131-linux-x64.tar.gz
(4)解压安装
$ tar -zxvf jdk-8u131-linux-x64.tar.gz -C /opt/modules/
7.(1)配置环境变量
# vi /etc/profile # set java environment export JAVA_HOME=/opt/modules/jdk1.8.0_131 export PATH=$PATH:$JAVA_HOME/bin
(2)使环境变量的 配置生效
# source /etc/profile
(3)执行java命令,检验配置是否生效
# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
8.解压hadoop安装包
$ tar -zxvf hadoop-2.6.5.tar.gz -C /opt/modules/
9.在etc/hadoop/hadoop-env.sh文件中设置JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_131
10.默认情况下,Hadoop配置为以非分布式模式运行,作为单个Java进程,
本地模式:mapreduce程序运行在本地,只需启动JVM
以下示例复制未打包的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+' $ cat output/*
依次执行上述命令后如果没有报错,则说明mapreduce程序运行成功
11.NameNode,DataNode,HDFS文件系统配置
(1)etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <!-- 如果没有配置,默认会从本地文件系统读取数据,步骤11就是读取本地文件系统的数据 --> <value>hdfs://hadoop01.zjl.com:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <!-- hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中 --> <value>/opt/modules/hadoop-2.6.5/data/tmp</value> </property> </configuration>
(2)创建目录/opt/modules/hadoop-2.6.5/data/tmp
$ mkdir -p data/tmp
(3)etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
12.执行
(1)格式化文件系统:
$ bin/hdfs namenode -format
(2)启动NameNode守护进程和DataNode守护进程:
$ sbin/start-dfs.sh
(3)执行jps命令查询java守护进程,若出现NameNode,DataNode,SecondaryNameNode等进程,则启动成功
$ jps 5296 Jps 4902 NameNode 5016 DataNode 5178 SecondaryNameNode
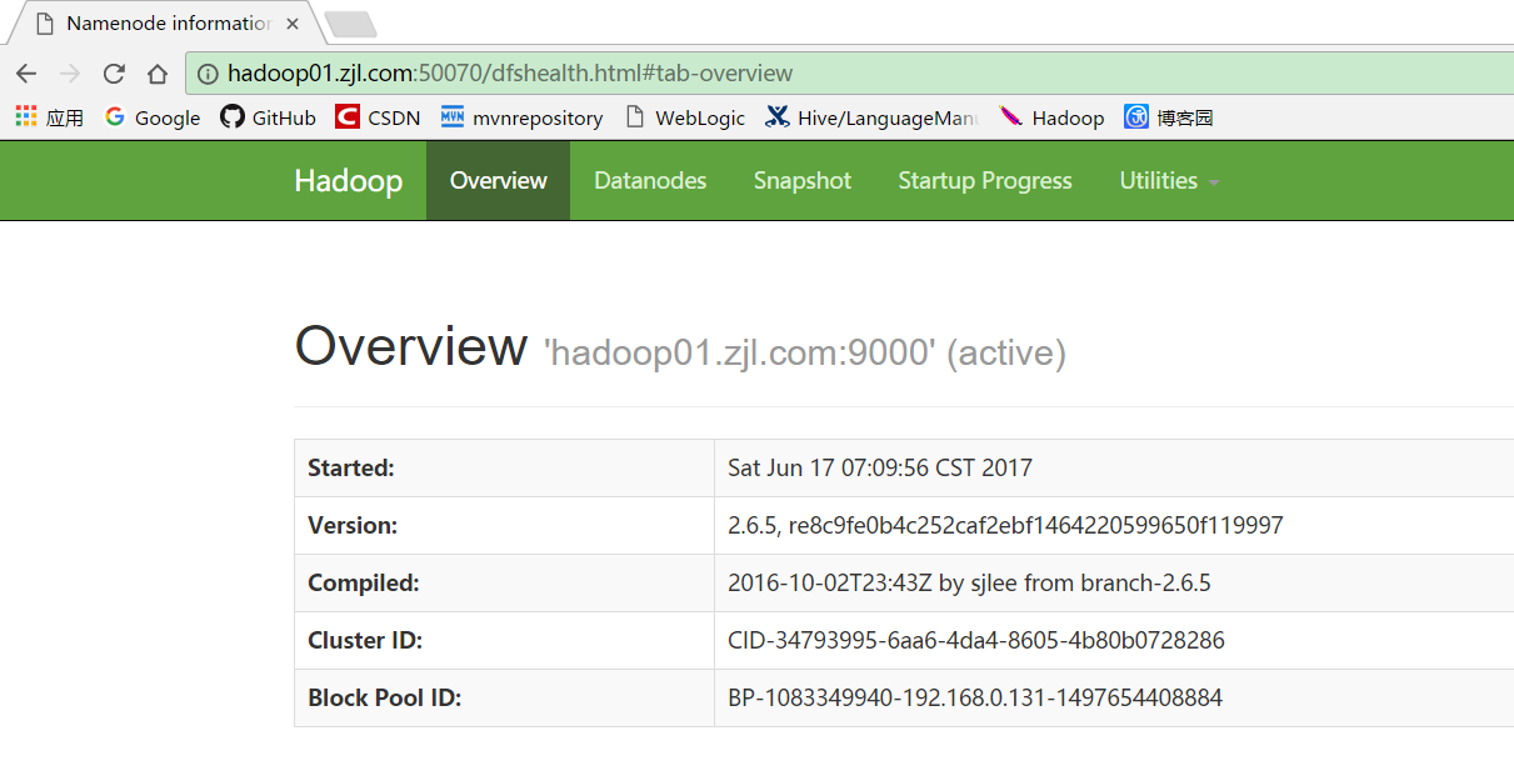
(4)在浏览器地址栏输入http://hadoop01.zjl.com:50070,回车,出现下图所示页面
13.单节点上的YARN的配置
(1)在etc/hadoop/yarn-env.sh文件中配置export JAVA_HOME=/opt/modules/jdk1.8.0_131
(2)etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01.zjl.com</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<property>
<name>yarn.log-aggregation-enable</name>
<!-- yarn的日志聚集 -->
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<!-- yarn的日志聚集 -->
<value>10080</value>
</property>
</configuration>
(3)将etc/hadoop/slaves文件中的localhost换成主机名hadoop01.zjl.com,slaves表示从节点,指向DataNode和NodeManager所在的机器
(4)启动ResourceManager守护程序和NodeManager守护程序:
$ sbin/start-yarn.sh
(5)执行jps命令查询java守护进程,若出现了NodeManager和NameNode进程,说明yarn启动成功
$ jps 6851 NodeManager 4902 NameNode 7158 Jps 5016 DataNode 5178 SecondaryNameNode 6763 ResourceManager
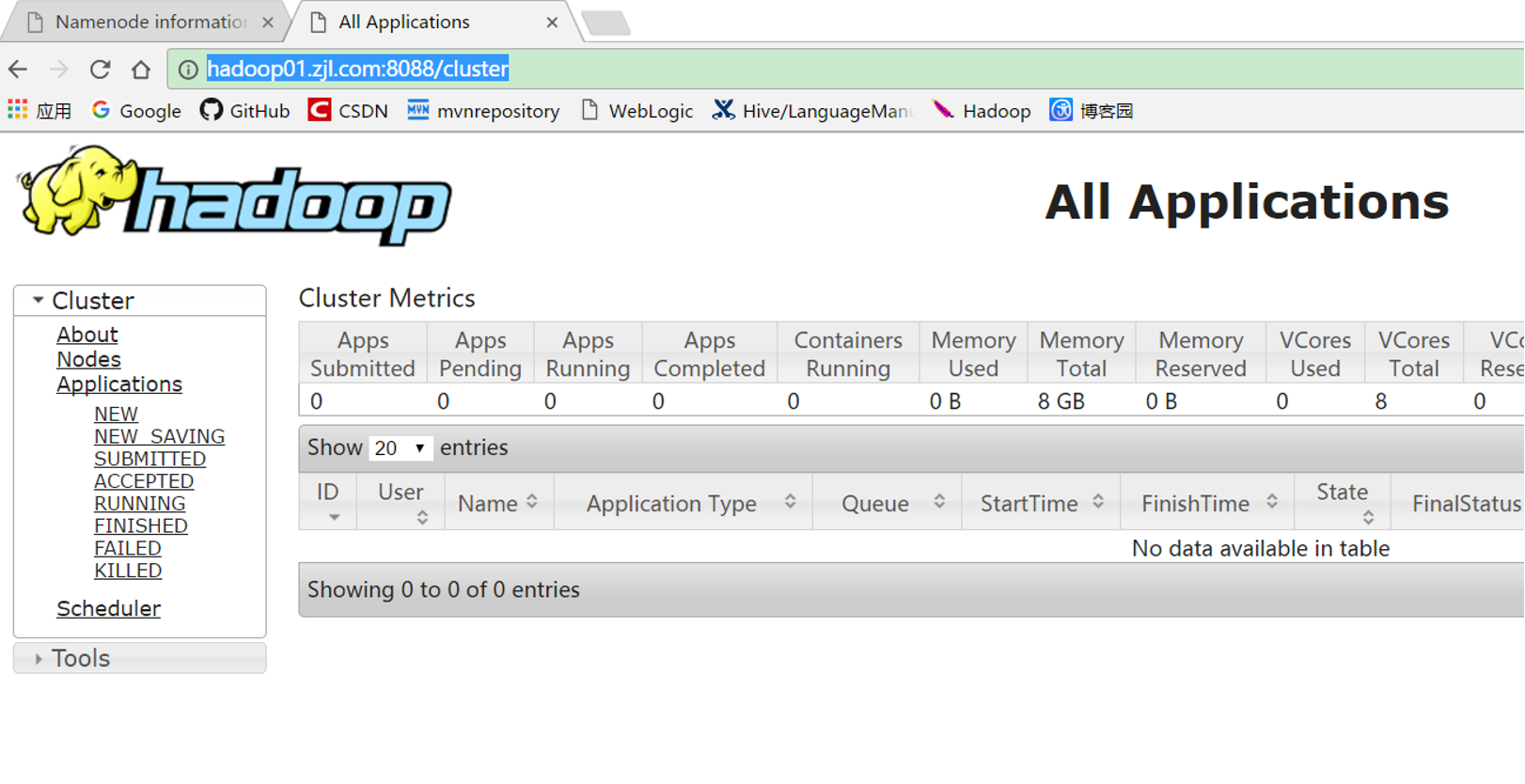
(6)在浏览器地址栏输入http://hadoop01.zjl.com:8088/cluster,回车,出现下图所示页面
14.使Mapreduce能够在yarn上运行
(1)在etc/hadoop/mapred-env.sh文件中配置export JAVA_HOME=/opt/modules/jdk1.8.0_131
(2)将etc/hadoop/mapred-site.xml.template重命名为mapred-site.xml,添加配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(3)在yarn上运行MapReduce示例程序,如果没报错,则MapReduce程序启动成功
$ hdfs dfs -mkdir -p input $ hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml input $ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+'