参考资料:Elasticsearch: 权威指南
在线地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
注:我用的ElasticSearch版本是6.5 使用的命令部分会和书中的不一样
1. 高阶概念
类似于 DSL 查询表达式,聚合也有可组合的语法:独立单元的功能可以被混合起来提供你需要的自定义行为。这意味着只需要学习很少的基本概念,就可以得到几乎无尽的组合。 要掌握聚合,你只需要明白两个主要的概念:
桶(Buckets) 满足特定条件的文档的集合。
指标(Metrics) 对桶内的文档进行统计计算。
这就是全部了!每个聚合都是一个或者多个桶和零个或者多个指标的组合。翻译成粗略的SQL语句来解释吧:
SELECT COUNT(color) ⑴
FROM table
GROUP BY color ⑵
⑴ COUNT(color) 相当于指标。
⑵ GROUP BY color 相当于桶。
桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
1.1 桶
桶 简单来说就是满足特定条件的文档的集合:
一个雇员属于 男性 桶或者 女性 桶
奥尔巴尼属于 纽约 桶
日期2014-10-28属于 十月 桶
当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件。如果匹配到,文档将放入相应的桶并接着进行聚合操作。 桶也可以被嵌套在其他桶里面,提供层次化的或者有条件的划分方案。
例如,辛辛那提会被放入俄亥俄州这个桶,而 整个 俄亥俄州桶会被放入美国这个桶。
Elasticsearch 有很多种类型的桶,能让你通过很多种方式来划分文档(时间、最受欢迎的词、年龄区间、地理位置等等)。其实根本上都是通过同样的原理进行操作:基于条件来划分文档
1.2 指标
桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶是一种达到目的的手段:它提供了一种给文档分组的方法来让我们可以计算感兴趣的指标。
大多数指标是简单的数学运算(例如最小值、平均值、最大值,还有汇总),这些是通过文档的值来计算。在实践中,指标能让你计算像平均薪资、最高出售价格、95%的查询延迟这样的数据。
1.3 桶和指标的组合
聚合 是由桶和指标组成的。
聚合可能只有一个桶,可能只有一个指标,或者可能两个都有。也有可能有一些桶嵌套在其他桶里面。
例如,我们可以通过所属国家来划分文档(桶),然后计算每个国家的平均薪酬(指标)。
由于桶可以被嵌套,我们可以实现非常多并且非常复杂的聚合:
1.通过国家划分文档(桶)
2.然后通过性别划分每个国家(桶)
3.然后通过年龄区间划分每种性别(桶)
4.最后,为每个年龄区间计算平均薪酬(指标)
最后将告诉你每个 <国家, 性别, 年龄> 组合的平均薪酬。
所有的这些都在一个请求内完成并且只遍历一次数据!
2. 尝试聚合
我们可以用以下几页定义不同的聚合和它们的语法, 但学习聚合的最佳途径就是用实例来说明。 一旦我们获得了聚合的思想,以及如何合理地嵌套使用它们,那么语法就变得不那么重要了。所以让我们先看一个例子。我们将会创建一些对汽车经销商有用的聚合,数据是关于汽车交易的信息:车型、制造商、售价、何时被出售等。 首先我们批量索引一些数据:
PUT /cars { "settings" : { "index" : { "number_of_replicas" : "1", "number_of_shards" : "1" } }, "mappings" : { "transactions" : { "properties" : { "color" : { "type" : "keyword", "index" : true }, "make" : { "type" : "keyword", "index" : true } } } } }
创建映射语句,我用的6.5版本,text类型因为会参与分词,已经不允许聚合了。所以把color和make设置为keyword类型。下面是新增的数据。
POST /cars/transactions/_bulk { "index": {}} { "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" } { "index": {}} { "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" } { "index": {}} { "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" } { "index": {}} { "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
有了数据,开始构建我们的第一个聚合。汽车经销商可能会想知道哪个颜色的汽车销量最好,用聚合可以轻易得到结果,用 terms 桶操作:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "popular_colors" : { "terms" : { "field" : "color" } } } }
* 聚合操作被置于顶层参数 aggs 之下(如果你愿意,完整形式 aggregations 同样有效)。
* 然后,可以为聚合指定一个我们想要名称,本例中是: popular_colors 。最后,定义单个桶的类型 terms 。
聚合是在特定搜索结果背景下执行的, 这也就是说它只是查询请求的另外一个顶层参数(例如,使用 /_search 端点)。聚合可以与查询结对,但我们会晚些在 限定聚合的范围(Scoping Aggregations) 中来解决这个问题。
可能会注意到我们将 size 设置成 0 。我们并不关心搜索结果的具体内容,所以将返回记录数设置为 0 来提高查询速度。 设置 size: 0 与 Elasticsearch 1.x 中使用 count 搜索类型等价。
然后我们为聚合定义一个名字,名字的选择取决于使用者,响应的结果会以我们定义的名字为标签,这样应用就可以解析得到的结果。 随后我们定义聚合本身,在本例中,我们定义了一个单 terms 桶。
这个 terms 桶会为每个碰到的唯一词项动态创建新的桶。 因为我们告诉它使用 color 字段,所以 terms 桶会为每个颜色动态创建新桶。 让我们运行聚合并查看结果:
"hits" : { "total" : 8, "max_score" : 0.0, "hits" : [ ] }, "aggregations" : { "popular_colors" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "red", "doc_count" : 4 }, { "key" : "blue", "doc_count" : 2 }, { "key" : "green", "doc_count" : 2 } ] } } }
* 因为我们设置了 size 参数,所以不会有 hits 搜索结果返回。
* popular_colors 聚合是作为 aggregations 字段的一部分被返回的。
* 每个桶的 key 都与 color 字段里找到的唯一词对应。它总会包含 doc_count 字段,告诉我们包含该词项的文档数量。
* 每个桶的数量代表该颜色的文档数量。
响应包含多个桶,每个对应一个唯一颜色(例如:红 或 绿)。每个桶也包括 聚合进 该桶的所有文档的数量。例如,有四辆红色的车。
前面的这个例子完全是实时执行的:一旦文档可以被搜到,它就能被聚合。这也就意味着我们可以直接将聚合的结果源源不断的传入图形库,然后生成实时的仪表盘。 不久,你又销售了一辆银色的车,我们的图形就会立即动态更新银色车的统计信息。
2.1 增加度量指标
前面的例子告诉我们每个桶里面的文档数量,这很有用。但通常,我们的应用需要提供更复杂的文档度量。 例如,每种颜色汽车的平均价格是多少? 为了获取更多信息,我们需要告诉 Elasticsearch 使用哪个字段,计算何种度量。这需要将度量 嵌套 在桶内,度量会基于桶内的文档计算统计结果。 让我们继续为汽车的例子加入 average 平均度量:
GET /cars/transactions/_search { "size" : 0, "aggs": { "colors": { "terms": { "field": "color" }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }
* 为度量新增 aggs 层。为度量指定名字: avg_price 。 最后,为 price 字段定义 avg 度量。
正如所见,我们用前面的例子加入了新的 aggs 层。这个新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格。
正如 颜色 的例子,我们需要给度量起一个名字( avg_price )这样可以稍后根据名字获取它的值。最后,我们指定度量本身( avg )以及我们想要计算平均值的字段( price ):
{ ... "aggregations": { "colors": { "buckets": [ { "key": "red", "doc_count": 4, "avg_price": { "value": 32500 } }, { "key": "blue", "doc_count": 2, "avg_price": { "value": 20000 } }, { "key": "green", "doc_count": 2, "avg_price": { "value": 21000 } } ] } } ... }
* 响应中的新字段 avg_price 。
尽管响应只发生很小改变,实际上我们获得的数据是增长了。之前,我们知道有四辆红色的车,现在,红色车的平均价格是 $32,500 美元。这个信息可以直接显示在报表或者图形中。
2.2 嵌套桶
在我们使用不同的嵌套方案时,聚合的力量才能真正得以显现。 在前例中,我们已经看到如何将一个度量嵌入桶中,它的功能已经十分强大了。
但真正令人激动的分析来自于将桶嵌套进 另外一个桶 所能得到的结果。 现在,我们想知道每个颜色的汽车制造商的分布:
GET /cars/transactions/_search { "size" : 0, "aggs": { "colors": { "terms": { "field": "color" }, "aggs": { "avg_price": { "avg": { "field": "price" } }, "make": { "terms": { "field": "make" } } } } } }
* 注意前例中的 avg_price 度量仍然保持原位。另一个聚合 make 被加入到了 color 颜色桶中。这个聚合是 terms 桶,它会为每个汽车制造商生成唯一的桶。
这里发生了一些有趣的事。 首先,我们可能会观察到之前例子中的 avg_price 度量完全没有变化,还在原来的位置。一个聚合的每个 层级 都可以有多个度量或桶, avg_price 度量告诉我们每种颜色汽车的平均价格。它与其他的桶和度量相互独立。 这对我们的应用非常重要,因为这里面有很多相互关联,但又完全不同的度量需要收集。聚合使我们能够用一次数据请求获得所有的这些信息。另外一件值得注意的重要事情是我们新增的这个 make 聚合,它是一个 terms 桶(嵌套在 colors 、 terms 桶内)。这意味着它会为数据集中的每个唯一组合生成( color 、 make )元组。
部分结果如下:
{ ... "aggregations": { "colors": { "buckets": [ { "key": "red", "doc_count": 4, "make": { "buckets": [ { "key": "honda", "doc_count": 3 }, { "key": "bmw", "doc_count": 1 } ] }, "avg_price": { "value": 32500 } }, ... }
* 正如期望的那样,新的聚合嵌入在每个颜色桶中。现在我们看见按不同制造商分解的每种颜色下车辆信息。最终,我们看到前例中的 avg_price 度量仍然维持不变。
响应结果告诉我们以下几点: 红色车有四辆。红色车的平均售价是 $32,500 美元。其中三辆是 Honda 本田制造,一辆是 BMW 宝马制造。
2.3 最后的修改
让我们回到话题的原点,在进入新话题之前,对我们的示例做最后一个修改, 为每个汽车生成商计算最低和最高的价格:
GET /cars/transactions/_search { "size" : 0, "aggs": { "colors": { "terms": { "field": "color" }, "aggs": { "avg_price": { "avg": { "field": "price" } }, "make" : { "terms" : { "field" : "make" }, "aggs" : { "min_price" : { "min": { "field": "price"} }, "max_price" : { "max": { "field": "price"} } } } } } } }
我们需要增加另外一个嵌套的 aggs 层级。然后包括 min 最小度量。以及 max 最大度量。
得到以下输出(只显示部分结果):
{ ... "aggregations": { "colors": { "buckets": [ { "key": "red", "doc_count": 4, "make": { "buckets": [ { "key": "honda", "doc_count": 3, "min_price": { "value": 10000 }, "max_price": { "value": 20000 } }, { "key": "bmw", "doc_count": 1, "min_price": { "value": 80000 }, "max_price": { "value": 80000 } } ] }, "avg_price": { "value": 32500 } }, ...
* min 和 max 度量现在出现在每个汽车制造商( make )下面。
有了这两个桶,我们可以对查询的结果进行扩展并得到以下信息: 有四辆红色车。红色车的平均售价是 $32,500 美元。其中三辆红色车是 Honda 本田制造,一辆是 BMW 宝马制造。最便宜的红色本田售价为 $10,000 美元。最贵的红色本田售价为 $20,000 美元。
3. 条形图
聚合还有一个令人激动的特性就是能够十分容易地将它们转换成图表和图形。我们正在通过示例数据来完成各种各样的聚合分析,最终,我们将会发现聚合功能是非常强大的。直方图 histogram 特别有用。
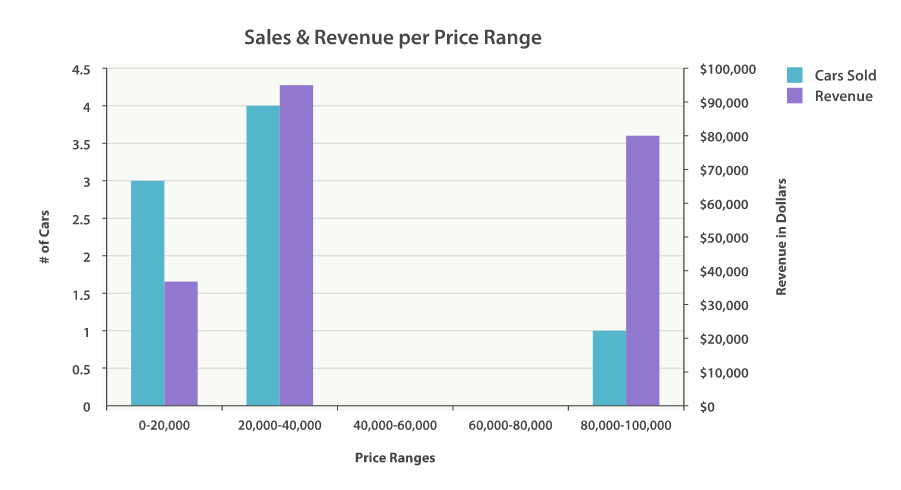
它本质上是一个条形图,如果有创建报表或分析仪表盘的经验,那么我们会毫无疑问的发现里面有一些图表是条形图。创建直方图需要指定一个区间,如果我们要为售价创建一个直方图,可以将间隔设为 20,000。这样做将会在每个 $20,000 档创建一个新桶,然后文档会被分到对应的桶中。 对于仪表盘来说,我们希望知道每个售价区间内汽车的销量。我们还会想知道每个售价区间内汽车所带来的收入,可以通过对每个区间内已售汽车的售价求和得到。 可以用 histogram 和一个嵌套的 sum 度量得到我们想要的答案:
GET /cars/transactions/_search { "size" : 0, "aggs":{ "price":{ "histogram":{ "field": "price", "interval": 20000 }, "aggs":{ "revenue": { "sum": { "field" : "price" } } } } } }
histogram 桶要求两个参数:一个数值字段以及一个定义桶大小间隔。sum 度量嵌套在每个售价区间内,用来显示每个区间内的总收入。
如我们所见,查询是围绕 price 聚合构建的,它包含一个 histogram 桶。它要求字段的类型必须是数值型的同时需要设定分组的间隔范围。 间隔设置为 20,000 意味着我们将会得到如 [0-19999, 20000-39999, ...] 这样的区间。 接着,我们在直方图内定义嵌套的度量,这个 sum 度量,它会对落入某一具体售价区间的文档中 price 字段的值进行求和。 这可以为我们提供每个售价区间的收入,从而可以发现到底是普通家用车赚钱还是奢侈车赚钱。
响应结果如下:
{ ... "aggregations": { "price": { "buckets": [ { "key": 0, "doc_count": 3, "revenue": { "value": 37000 } }, { "key": 20000, "doc_count": 4, "revenue": { "value": 95000 } }, { "key": 80000, "doc_count": 1, "revenue": { "value": 80000 } } ] } } }
结果很容易理解,不过应该注意到直方图的键值是区间的下限。键 0 代表区间 0-19,999 ,键 20000 代表区间 20,000-39,999 ,等等。
做成柱形图后的效果如下:
当然,我们可以为任何聚合输出的分类和统计结果创建条形图,而不只是 直方图 桶。让我们以最受欢迎 10 种汽车以及它们的平均售价、标准差这些信息创建一个条形图。 我们会用到 terms 桶和 extended_stats 度量:
GET /cars/transactions/_search { "size" : 0, "aggs": { "makes": { "terms": { "field": "make", "size": 10 }, "aggs": { "stats": { "extended_stats": { "field": "price" } } } } } }
上述代码会按受欢迎度返回制造商列表以及它们各自的统计信息。我们对其中的 stats.avg 、 stats.count 和 stats.std_deviation 信息特别感兴趣,并用 它们计算出标准差: std_err = std_deviation / count
4. 按时间统计
如果搜索是在 Elasticsearch 中使用频率最高的,那么构建按时间统计的 date_histogram 紧随其后。
为什么你会想用 date_histogram 呢?假设你的数据带时间戳。 无论是什么数据(Apache 事件日志、股票买卖交易时间、棒球运动时间)只要带有时间戳都可以进行 date_histogram 分析。当你的数据有时间戳,你总是想在 时间 维度上构建指标分析:
今年每月销售多少台汽车?
这只股票最近 12 小时的价格是多少?
我们网站上周每小时的平均响应延迟时间是多少?
虽然通常的 histogram 都是条形图,但 date_histogram 倾向于转换成线状图以展示时间序列。 许多公司用 Elasticsearch 仅仅 只是为了分析时间序列数据。date_histogram 分析是它们最基本的需要。date_histogram 与 通常的 histogram 类似。 但不是在代表数值范围的数值字段上构建 buckets,而是在时间范围上构建 buckets。 因此每一个 bucket 都被定义成一个特定的日期大小 (比如, 1个月 或 2.5 天 )。
我们的第一个例子将构建一个简单的折线图来回答如下问题: 每月销售多少台汽车?
GET /cars/transactions/_search { "size" : 0, "aggs": { "sales": { "date_histogram": { "field": "sold", "interval": "month", "format": "yyyy-MM-dd" } } } }
* 时间间隔要求是日历术语 (如每个 bucket 1 个月)。
* 我们提供日期格式以便 buckets 的键值便于阅读。
我们的查询只有一个聚合,每月构建一个 bucket。这样我们可以得到每个月销售的汽车数量。 另外还提供了一个额外的 format 参数以便 buckets 有 "好看的" 键值。 然而在内部,日期仍然是被简单表示成数值。这可能会使得 UI 设计者抱怨,因此可以提供常用的日期格式进行格式化以更方便阅读。结果既符合预期又有一点出人意料(看看你是否能找到意外之处):
{ ... "aggregations": { "sales": { "buckets": [ { "key_as_string": "2014-01-01", "key": 1388534400000, "doc_count": 1 }, { "key_as_string": "2014-02-01", "key": 1391212800000, "doc_count": 1 }, { "key_as_string": "2014-05-01", "key": 1398902400000, "doc_count": 1 }, { "key_as_string": "2014-07-01", "key": 1404172800000, "doc_count": 1 }, { "key_as_string": "2014-08-01", "key": 1406851200000, "doc_count": 1 }, { "key_as_string": "2014-10-01", "key": 1412121600000, "doc_count": 1 }, { "key_as_string": "2014-11-01", "key": 1414800000000, "doc_count": 2 } ] ... }
聚合结果已经完全展示了。正如你所见,我们有代表月份的 buckets,每个月的文档数目,以及美化后的 key_as_string 。
4.1 返回空 Buckets
注意到结果末尾处的奇怪之处了吗? 是的,结果没错。我们的结果少了一些月份!date_histogram (和 histogram 一样)默认只会返回文档数目非零的 buckets。
这意味着你的 histogram 总是返回最少结果。通常,你并不想要这样。对于很多应用,你可能想直接把结果导入到图形库中,而不想做任何后期加工。
事实上,即使 buckets 中没有文档我们也想返回。可以通过设置两个额外参数来实现这种效果:
GET /cars/transactions/_search { "size" : 0, "aggs": { "sales": { "date_histogram": { "field": "sold", "interval": "month", "format": "yyyy-MM-dd", "min_doc_count" : 0, "extended_bounds" : { "min" : "2014-01-01", "max" : "2014-12-31" } } } } }
* 这个参数强制返回空 buckets。 这个参数强制返回整年。
这两个参数会强制返回一年中所有月份的结果,而不考虑结果中的文档数目。
min_doc_count 非常容易理解:它强制返回所有 buckets,即使 buckets 可能为空。 extended_bounds 参数需要一点解释。 min_doc_count 参数强制返回空 buckets,但是 Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets。 因此如果你的数据只落在了 4 月和 7 月之间,那么你只能得到这些月份的 buckets(可能为空也可能不为空)。
因此为了得到全年数据,我们需要告诉 Elasticsearch 我们想要全部 buckets, 即便那些 buckets 可能落在最小日期 之前 或 最大日期 之后 。
4.2 扩展例子
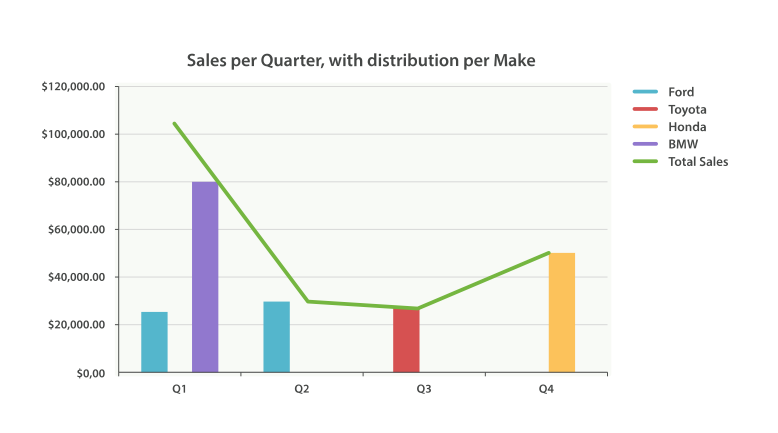
正如我们已经见过很多次,buckets 可以嵌套进 buckets 中从而得到更复杂的分析。作为例子,我们构建聚合以便按季度展示所有汽车品牌总销售额。同时按季度、按每个汽车品牌计算销售总额,以便可以找出哪种品牌最赚钱:
GET /cars/transactions/_search { "size" : 0, "aggs": { "sales": { "date_histogram": { "field": "sold", "interval": "quarter", "format": "yyyy-MM-dd", "min_doc_count" : 0, "extended_bounds" : { "min" : "2014-01-01", "max" : "2014-12-31" } }, "aggs": { "per_make_sum": { "terms": { "field": "make" }, "aggs": { "sum_price": { "sum": { "field": "price" } } } }, "total_sum": { "sum": { "field": "price" } } } } } }
* 注意我们把时间间隔从 month 改成了 quarter 。 计算每种品牌的总销售金额。 也计算所有全部品牌的汇总销售金额。
得到的结果(截去了一大部分)如下:
{ .... "aggregations": { "sales": { "buckets": [ { "key_as_string": "2014-01-01", "key": 1388534400000, "doc_count": 2, "total_sum": { "value": 105000 }, "per_make_sum": { "buckets": [ { "key": "bmw", "doc_count": 1, "sum_price": { "value": 80000 } }, { "key": "ford", "doc_count": 1, "sum_price": { "value": 25000 } } ] } }, ... }
我们把结果绘成图,如下图,“按品牌分布的每季度销售额” 所示的总销售额的折线图和每个品牌(每季度)的柱状图。
5. 范围限定的聚合
所有聚合的例子到目前为止,你可能已经注意到,我们的搜索请求省略了一个 query 。整个请求只不过是一个聚合。 聚合可以与搜索请求同时执行,但是我们需要理解一个新概念: 范围 。默认情况下,聚合与查询是对同一范围进行操作的,也就是说,聚合是基于我们查询匹配的文档集合进行计算的。
因为聚合总是对查询范围内的结果进行操作的,所以一个隔离的聚合实际上是在对 match_all 的结果范围操作,即所有的文档。
一旦有了范围的概念,我们就能更进一步对聚合进行自定义。我们前面所有的示例都是对 所有 数据计算统计信息的:销量最高的汽车,所有汽车的平均售价,最佳销售月份等等。
利用范围,我们可以问“福特在售车有多少种颜色?”诸如此类的问题。可以简单的在请求中加上一个查询(本例中为 match 查询):
GET /cars/transactions/_search { "query" : { "match" : { "make" : "ford" } }, "aggs" : { "colors" : { "terms" : { "field" : "color" } } } }
因为我们没有指定 "size" : 0 ,所以搜索结果和聚合结果都被返回了:
{ ... "hits": { "total": 2, "max_score": 1.6931472, "hits": [ { "_source": { "price": 25000, "color": "blue", "make": "ford", "sold": "2014-02-12" } }, { "_source": { "price": 30000, "color": "green", "make": "ford", "sold": "2014-05-18" } } ] }, "aggregations": { "colors": { "buckets": [ { "key": "blue", "doc_count": 1 }, { "key": "green", "doc_count": 1 } ] } } }
看上去这并没有什么,但却对高大上的仪表盘来说至关重要。 加入一个搜索栏可以将任何静态的仪表板变成一个实时数据搜索设备。 这让用户可以搜索数据,查看所有实时更新的图形(由于聚合的支持以及对查询范围的限定)。 这是 Hadoop 无法做到的!
5.1 全局桶
通常我们希望聚合是在查询范围内的,但有时我们也想要搜索它的子集,而聚合的对象却是 所有 数据。 例如,比方说我们想知道福特汽车与 所有 汽车平均售价的比较。我们可以用普通的聚合(查询范围内的)得到第一个信息,然后用 全局 桶获得第二个信息。 全局 桶包含 所有 的文档,它无视查询的范围。因为它还是一个桶,我们可以像平常一样将聚合嵌套在内:
GET /cars/transactions/_search { "size" : 0, "query" : { "match" : { "make" : "ford" } }, "aggs" : { "single_avg_price": { "avg" : { "field" : "price" } }, "all": { "global" : {}, "aggs" : { "avg_price": { "avg" : { "field" : "price" } } } } } }
* 聚合操作在查询范围内(例如:所有文档匹配 ford ) global 全局桶没有参数。 聚合操作针对所有文档,忽略汽车品牌。
single_avg_price 度量计算是基于查询范围内所有文档,即所有 福特 汽车。avg_price 度量是嵌套在 全局 桶下的,这意味着它完全忽略了范围并对所有文档进行计算。聚合返回的平均值是所有汽车的平均售价。
6. 过滤和聚合
聚合范围限定还有一个自然的扩展就是过滤。因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上。
6.4 小结
选择合适类型的过滤(如:搜索命中、聚合或两者兼有)通常和我们期望如何表现用户交互有关。选择合适的过滤器(或组合)取决于我们期望如何将结果呈现给用户。
在 filter 过滤中的 non-scoring 查询,同时影响搜索结果和聚合结果。
filter 桶影响聚合。
post_filter 只影响搜索结果。
7. 多桶排序
多值桶( terms 、 histogram 和 date_histogram )动态生成很多桶。 Elasticsearch 是如何决定这些桶展示给用户的顺序呢?
默认的,桶会根据 doc_count 降序排列。这是一个好的默认行为,因为通常我们想要找到文档中与查询条件相关的最大值:售价、人口数量、频率。但有些时候我们希望能修改这个顺序,不同的桶有着不同的处理方式。
7.1 内置排序
这些排序模式是桶 固有的 能力:它们操作桶生成的数据 ,比如 doc_count 。 它们共享相同的语法,但是根据使用桶的不同会有些细微差别。
让我们做一个 terms 聚合但是按 doc_count 值的升序排序:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "colors" : { "terms" : { "field" : "color", "order": { "_count" : "asc" } } } } }
* 用关键字 _count ,我们可以按 doc_count 值的升序排序。
我们为聚合引入了一个 order 对象, 它允许我们可以根据以下几个值中的一个值进行排序:
_count 按文档数排序。对 terms 、 histogram 、 date_histogram 有效。
_term 按词项的字符串值的字母顺序排序。只在 terms 内使用。
_key 按每个桶的键值数值排序(理论上与 _term 类似)。 只在 histogram 和 date_histogram 内使用。
7.2 按度量排序
有时,我们会想基于度量计算的结果值进行排序。 在我们的汽车销售分析仪表盘中,我们可能想按照汽车颜色创建一个销售条状图表,但按照汽车平均售价的升序进行排序。
我们可以增加一个度量,再指定 order 参数引用这个度量即可:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "colors" : { "terms" : { "field" : "color", "order": { "avg_price" : "asc" } }, "aggs": { "avg_price": { "avg": {"field": "price"} } } } } }
* 计算每个桶的平均售价。
* 桶按照计算平均值的升序排序。
我们可以采用这种方式用任何度量排序,只需简单的引用度量的名字。不过有些度量会输出多个值。 extended_stats 度量是一个很好的例子:它输出好几个度量值。
如果我们想使用多值度量进行排序, 我们只需以关心的度量为关键词使用点式路径:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "colors" : { "terms" : { "field" : "color", "order": { "stats.variance" : "asc" } }, "aggs": { "stats": { "extended_stats": {"field": "price"} } } } } }
使用 . 符号,根据感兴趣的度量进行排序。
在上面这个例子中,我们按每个桶的方差来排序,所以这种颜色售价方差最小的会排在结果集最前面。
7.3 基于“深度”度量排序
在前面的示例中,度量是桶的直接子节点。平均售价是根据每个 term 来计算的。 在一定条件下,我们也有可能对 更深 的度量进行排序,比如孙子桶或从孙桶。
我们可以定义更深的路径,将度量用尖括号( > )嵌套起来,像这样: my_bucket>another_bucket>metric 。
需要提醒的是嵌套路径上的每个桶都必须是 单值 的。 filter 桶生成 一个单值桶:所有与过滤条件匹配的文档都在桶中。 多值桶(如:terms )动态生成许多桶,无法通过指定一个确定路径来识别。
目前,只有三个单值桶: filter 、 global 和 reverse_nested 。让我们快速用示例说明,创建一个汽车售价的直方图,但是按照红色和绿色(不包括蓝色)车各自的方差来排序:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "colors" : { "histogram" : { "field" : "price", "interval": 20000, "order": { "red_green_cars>stats.variance" : "asc" } }, "aggs": { "red_green_cars": { "filter": { "terms": {"color": ["red", "green"]}}, "aggs": { "stats": {"extended_stats": {"field" : "price"}} } } } } } }
* 按照嵌套度量的方差对桶的直方图进行排序。
* 因为我们使用单值过滤器 filter ,我们可以使用嵌套排序。
* 按照生成的度量对统计结果进行排序。
本例中,可以看到我们如何访问一个嵌套的度量。 stats 度量是 red_green_cars 聚合的子节点,而 red_green_cars 又是 colors 聚合的子节点。 为了根据这个度量排序,我们定义了路径 red_green_cars>stats.variance 。我们可以这么做,因为 filter 桶是个单值桶。
8. 近似聚合
如果所有的数据都在一台机器上,那么生活会容易许多。 CS201 课上教的经典算法就足够应付这些问题。如果所有的数据都在一台机器上,那么也就不需要像 Elasticsearch 这样的分布式软件了。不过一旦我们开始分布式存储数据,就需要小心地选择算法。
有些算法可以分布执行,到目前为止讨论过的所有聚合都是单次请求获得精确结果的。这些类型的算法通常被认为是 高度并行的 ,因为它们无须任何额外代价,就能在多台机器上并行执行。比如当计算 max 度量时,以下的算法就非常简单:(1)把请求广播到所有分片。(2)查看每个文档的 price 字段。如果 price > current_max ,将 current_max 替换成 price 。(3)返回所有分片的最大 price 并传给协调节点。(4)找到从所有分片返回的最大 price 。这是最终的最大值。
这个算法可以随着机器数的线性增长而横向扩展,无须任何协调操作(机器之间不需要讨论中间结果),而且内存消耗很小(一个整型就能代表最大值)。
不幸的是,不是所有的算法都像获取最大值这样简单。更加复杂的操作则需要在算法的性能和内存使用上做出权衡。对于这个问题,我们有个三角因子模型:大数据、精确性和实时性。
我们需要选择其中两项:
精确 + 实时:数据可以存入单台机器的内存之中,我们可以随心所欲,使用任何想用的算法。结果会 100% 精确,响应会相对快速。
大数据 + 精确:传统的 Hadoop。可以处理 PB 级的数据并且为我们提供精确的答案,但它可能需要几周的时间才能为我们提供这个答案。
大数据 + 实时:近似算法为我们提供准确但不精确的结果。
Elasticsearch 目前支持两种近似算法( cardinality 和 percentiles )。 它们会提供准确但不是 100% 精确的结果。 以牺牲一点小小的估算错误为代价,这些算法可以为我们换来高速的执行效率和极小的内存消耗。
对于 大多数 应用领域,能够 实时 返回高度准确的结果要比 100% 精确结果重要得多。乍一看这可能是天方夜谭。有人会叫 “我们需要精确的答案!” 。但仔细考虑 0.5% 误差所带来的影响:99% 的网站延时都在 132ms 以下。0.5% 的误差对以上延时的影响在正负 0.66ms 。近似计算的结果会在毫秒内返回,而“完全正确”的结果就可能需要几秒,甚至无法返回。
只要简单的查看网站的延时情况,难道我们会在意近似结果是 132.66ms 而不是 132ms 吗?当然,不是所有的领域都能容忍这种近似结果,但对于绝大多数来说是没有问题的。接受近似结果更多的是一种 文化观念上 的壁垒而不是商业或技术上的需要。
8.1 统计去重后的数量
Elasticsearch 提供的首个近似聚合是 cardinality (注:基数)度量。 它提供一个字段的基数,即该字段的 distinct 或者 unique 值的数目。 你可能会对 SQL 形式比较熟悉:
SELECT COUNT(DISTINCT color) FROM cars
去重是一个很常见的操作,可以回答很多基本的业务问题:网站独立访客是多少?卖了多少种汽车?每月有多少独立用户购买了商品?
我们可以用 cardinality 度量确定经销商销售汽车颜色的数量:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "distinct_colors" : { "cardinality" : { "field" : "color" } } } }
返回的结果表明已经售卖了三种不同颜色的汽车:
... "aggregations": { "distinct_colors": { "value": 3 } } ...
可以让我们的例子变得更有用:每月有多少颜色的车被售出?为了得到这个度量,我们只需要将一个 cardinality 度量嵌入一个 date_histogram :
GET /cars/transactions/_search { "size" : 0, "aggs" : { "months" : { "date_histogram": { "field": "sold", "interval": "month" }, "aggs": { "distinct_colors" : { "cardinality" : { "field" : "color" } } } } } }
学会权衡
正如我们本章开头提到的, cardinality 度量是一个近似算法。 它是基于 HyperLogLog++ (HLL)算法的。 HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。
我们不需要理解技术细节(如果确实感兴趣,可以阅读这篇论文), 但我们最好应该关注一下这个算法的 特性 :可配置的精度,用来控制内存的使用(更精确 = 更多内存)。小的数据集精度是非常高的。我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
要配置精度,我们必须指定 precision_threshold 参数的值。 这个阈值定义了在何种基数水平下我们希望得到一个近乎精确的结果。参考以下示例:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "distinct_colors" : { "cardinality" : { "field" : "color", "precision_threshold" : 100 } } } }
* precision_threshold 接受 0–40,000 之间的数字,更大的值还是会被当作 40,000 来处理。
示例会确保当字段唯一值在 100 以内时会得到非常准确的结果。尽管算法是无法保证这点的,但如果基数在阈值以下,几乎总是 100% 正确的。高于阈值的基数会开始节省内存而牺牲准确度,同时也会对度量结果带入误差。
对于指定的阈值,HLL 的数据结构会大概使用 precision_threshold * 8 字节的内存,所以就必须在牺牲内存和获得额外的准确度间做平衡。
在实际应用中, 100 的阈值可以在唯一值为百万的情况下仍然将误差维持 5% 以内。
速度优化
如果想要获得唯一值的数目, 通常 需要查询整个数据集合(或几乎所有数据)。 所有基于所有数据的操作都必须迅速,原因是显然的。 HyperLogLog 的速度已经很快了,它只是简单的对数据做哈希以及一些位操作。
但如果速度对我们至关重要,可以做进一步的优化。 因为 HLL 只需要字段内容的哈希值,我们可以在索引时就预先计算好。 就能在查询时跳过哈希计算然后将哈希值从 fielddata 直接加载出来。
预先计算哈希值只对内容很长或者基数很高的字段有用,计算这些字段的哈希值的消耗在查询时是无法忽略的。
尽管数值字段的哈希计算是非常快速的,存储它们的原始值通常需要同样(或更少)的内存空间。这对低基数的字符串字段同样适用,Elasticsearch 的内部优化能够保证每个唯一值只计算一次哈希。
基本上说,预先计算并不能保证所有的字段都更快,它只对那些具有高基数和/或者内容很长的字符串字段有作用。需要记住的是,预计算只是简单的将查询消耗的时间提前转移到索引时,并非没有任何代价,区别在于你可以选择在 什么时候 做这件事,要么在索引时,要么在查询时。
要想这么做,我们需要为数据增加一个新的多值字段。我们先删除索引,再增加一个包括哈希值字段的映射,然后重新索引:
DELETE /cars/ PUT /cars/ { "mappings": { "transactions": { "properties": { "color": { "type": "string", "fields": { "hash": { "type": "murmur3" } } } } } } } POST /cars/transactions/_bulk { "index": {}} { "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" } { "index": {}} { "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" } { "index": {}} { "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" } { "index": {}} { "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" } { "index": {}} { "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" } { "index": {}} { "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
* 多值字段的类型是 murmur3 ,这是一个哈希函数。
现在当我们执行聚合时,我们使用 color.hash 字段而不是 color 字段:
GET /cars/transactions/_search { "size" : 0, "aggs" : { "distinct_colors" : { "cardinality" : { "field" : "color.hash" } } } }
* 注意我们指定的是哈希过的多值字段,而不是原始字段。
现在 cardinality 度量会读取 "color.hash" 里的值(预先计算的哈希值),取代动态计算原始值的哈希。
单个文档节省的时间是非常少的,但是如果你聚合一亿数据,每个字段多花费 10 纳秒的时间,那么在每次查询时都会额外增加 1 秒,如果我们要在非常大量的数据里面使用 cardinality ,我们可以权衡使用预计算的意义,是否需要提前计算 hash,从而在查询时获得更好的性能,做一些性能测试来检验预计算哈希是否适用于你的应用场景。
repo_sys_role_menu